主要看了以及参考了以下这几篇文章:
首先大背景是这样的:
对于加法策略可以表示如下:
初始化(模型中没有树时,其预测结果为0):
往模型中加入第一棵树:
往模型中加入第二棵树:
…
往模型中加入第t棵树:
其中
表示第
棵树,
表示组合
棵树模型对样本
的预测结果。
我们知道,每次往模型中加入一棵树,其损失函数便会发生变化。另外在加入第t棵树时,则前面第t-1棵树已经训练完成,此时前面t-1棵树的正则项和训练误差都成已知常数项。
(1)不懂的公式推导之一
基于以上背景,以下公式推导中,第1行蓝色方框圈住的,由于前面第t-1棵树已经训练完成可以当做已知常数项,因此相当于第2行绿色方框,第3行红色方框圈住的,同样的原因,以及这一项与
无关,所以被纳入了constant项,因此两个红色方框相加相当于第4行的棕色方框。

(2)不懂的公式推导之二

很多XGBoost的讲解都有以上这张图片,但是,图中画蓝线的圈1式子是如何变为圈2式子的,始终没有说得很明白。
![]() (1)
(1)
以上的最后的是真实值,即已知,可以当作一个常数,
当作
,
当作
。例如以下a是一个常数:
 (2)
(2)
以上就可以把a当作一个常数,然后对x求偏导,利用公式:

得到:
 (3)
(3)
可以发现,(3)式与(2)式的结果相同。
基于这个例子,于是(1)式:

其中,标红色的和
等价,标蓝色的
和
等价。并且,第3行的两个偏导数,即以下圈住的部分
 (4)
(4)
令![]() ,
,![]() ,于是就得到了(4)式中第4行的部分。
,于是就得到了(4)式中第4行的部分。
由于第t-1颗树的值![]() 已知,
已知,也是已知的,因此,
对目标函数的优化不影响,可以直接去掉,且常数项也可以移除,从而得到如下一个比较统一的目标函数。
(3)不懂的公式解释之三
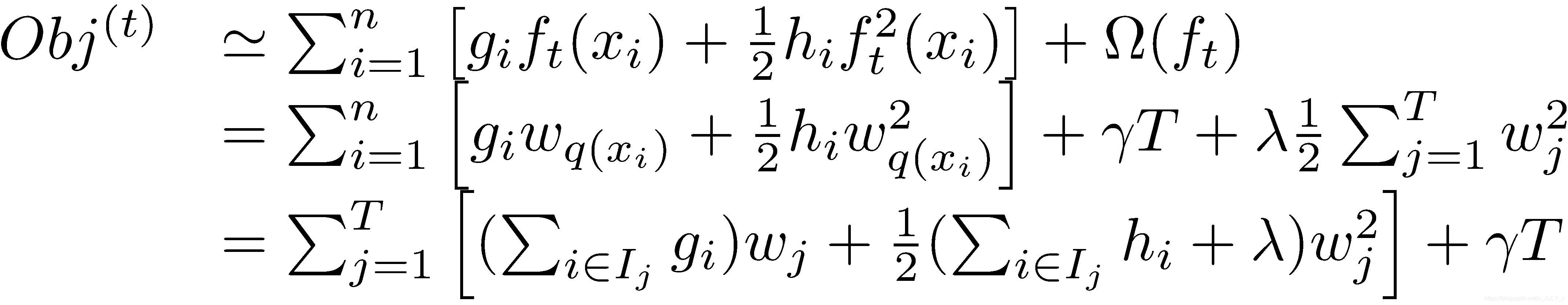
以上图片中,由i变成j其实相当于将在样本上遍历转换成在叶子节点上遍历。
近似算法
模型对特征中的值的范围不敏感,只对顺序敏感。举个例子,假设一个样本集中某特征出现的值有1,4,6,7,那么把它对应的换成1, 2,3,4。生成的模型里树的结构是一样的,只不过对应的判断条件变了,比如把小于6换成了小于3而已。这也给我们一个启示,我们完全可以用百分比作为基础来构造模型。
一些进一步优化
在机器学习中,one-hot后,经常会得到的是稀疏矩阵,于是XGBoost也对这个作出了优化。还可以处理缺失值,毕竟这也是树模型一贯的优点。但这里就不细表了,毕竟太过于细节了。下一节我们就来看XGBoost这种强大的模型应该怎么使用吧。
例程
官方例程如下:
import xgboost as xgb
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train')
dtest = xgb.DMatrix('demo/data/agaricus.txt.test')
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic' }
num_round = 2
bst = xgb.train(param, dtrain, num_round)
# make prediction
preds = bst.predict(dtest)参数
很明显,上面重要的就是param,这个参数应该怎么设。在官网上有整整一个网页的说明。在这里我们只挑选一些重要常用的说一下。
与过拟合有关的参数
在机器学习中,欠拟合很少见,但是过拟合却是一个很常见的东西。XGBoost与其有关的参数也不少。
增加随机性
- eta 这个就是学习步进,也就是上面中的ϵ。
- subsample 这个就是随机森林的方式,每次不是取出全部样本,而是有放回地取出部分样本。有人把这个称为行抽取,subsample就表示抽取比例
- colsample_bytree和colsample_bylevel 这个是模仿随机森林的方式,这是列抽取。colsample_bytree是每次准备构造一棵新树时,选取部分特征来构造,colsample_bytree就是抽取比例。colsample_bylevel表示的是每次分割节点时,抽取特征的比例。
- max_delta_step 这个是构造树时,允许得到的最大值。如果为0,表示无限制。也是为了后续构造树留出空间,和
相似
控制模型复杂度
- max_depth 树的最大深度
- min_child_weight 如果一个节点的权重和小于这玩意,那就不分了
- gamma每次分开一个节点后,造成的最小下降的分数。类似于上面的Gain
- alpha和lambda就是目标函数里的表示模型复杂度中的L1范数和L2范数前面的系数
其他参数
- booster 表示用哪种模型,一共有gbtree, gbline, dart三种选择。一般用gbtree。
- nthread 并行线成数。如果不设置就是能采用的最大线程。
- sketch_eps 这个就是近似算法里的ϵ。
- scale_pos_weight 这个是针对二分类问题时,正负样例的数量差距过大。