本文公众号文章链接:https://mp.weixin.qq.com/s/Cet4TTTTc6_OWWvmNgjOKA
本文csdn博客文章链接:https://blog.csdn.net/screscent/article/details/79912742
boltdb是一个纯粹的key Value数据库,其宗旨是提供一个简单,快速,可信的数据库。此数据库广泛应用于各大开源组件中。
前面文章已经讲解了
page结构 Boltdb源码分析(一)-------page结构
node结构Boltdb源码分析(二)----node结构
meta结构Boltdb源码分析(三)----meta结构
本文分析bucket结构
由于bucket和其他很多东西有关联。所以这里有几个概念,把这些结构串起来。

先是最底层的磁盘文件,其结构为一维结构。最小的管理单位是page,将文件按照page大小分割成块。
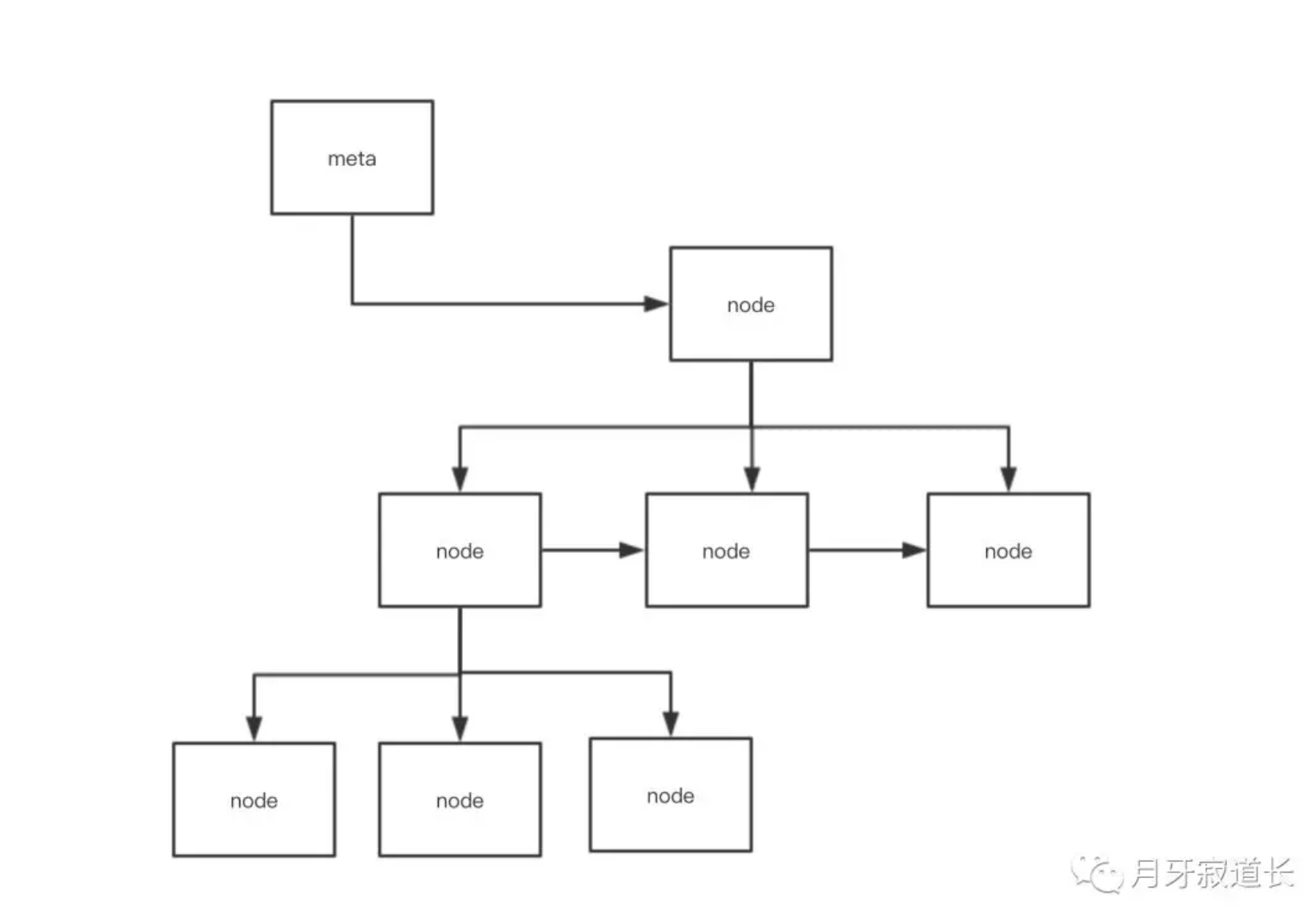
然后将文件对应的page映射到内存中,是这样的一个二维地图。meta是入口,其中有数据的root部分。node是一个树形结构,其中有分支节点,有叶子节点。
然后每个node有着不同的属性,是保持key Value的,还是保持bucket(表头)。
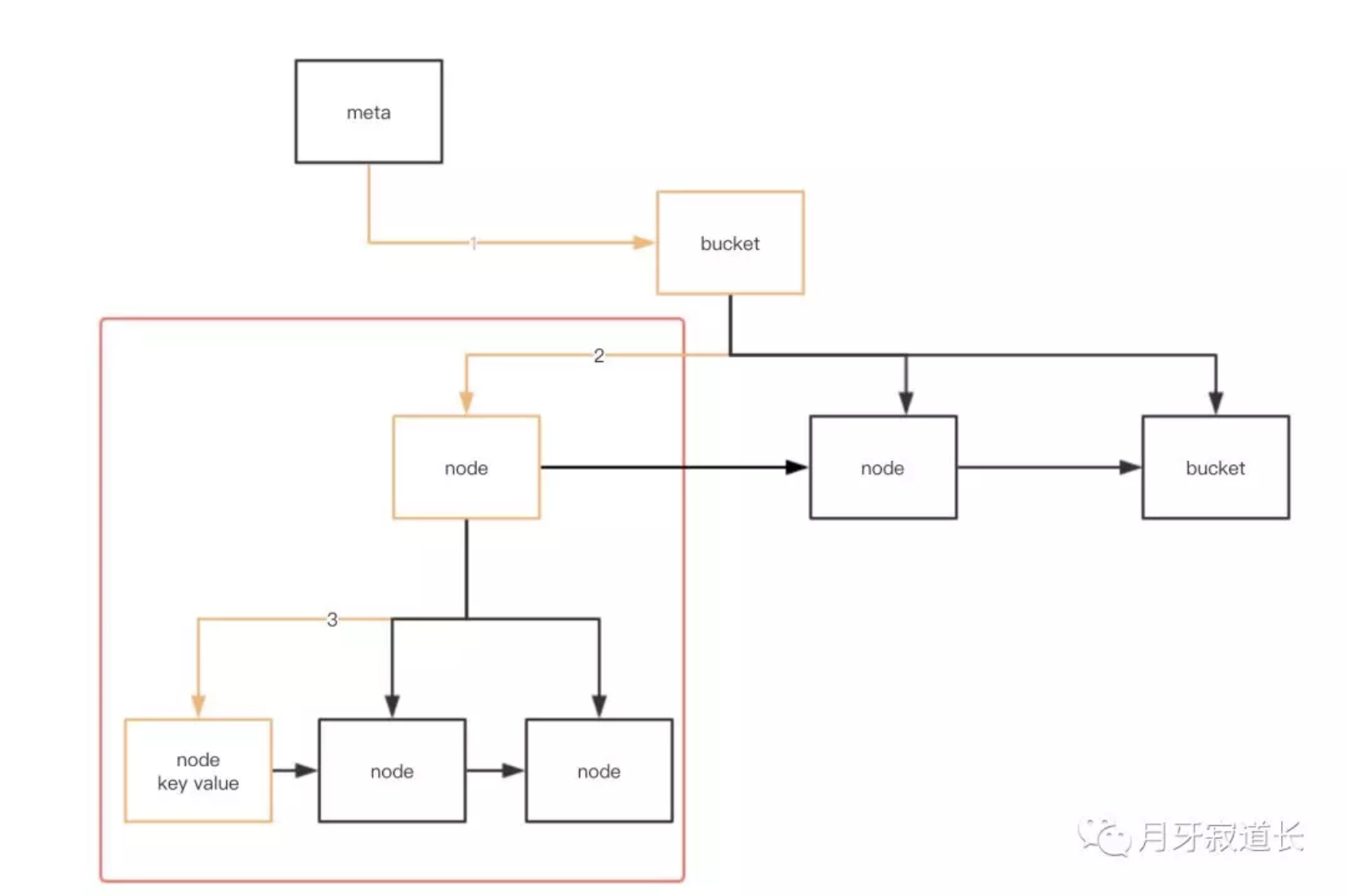
然后才是bucket结构。boltdb,针对每次的操作(读或写)的事务,都会有一次bucket的探索过程。
假设我们要去读一个key所对应的Value
先从meta的root中,获取到对应的bucket。然后红色框中,bucket的一个探索过程,是通过游标cursor来寻找的,cursor表示探索的当前位置,直到cursor定位到所在的位置。这里的位置就是node。
这里可以很形象的比喻下。
1、磁盘文件就是一个以page为单位块的一维空间。
2、内存中通过page---》node的映射,然后node通过树形结构链接起来,形成了一个二维的树结构。其中meta为特殊的page,为整个数据的入口。
3、现在有了node的树形地图。需要对树进行操作,读或写。就需要来一次探索过程。其中bucket就是一个过程,其中bucket的探索定位是通过游标cursor来实现的。
那么下面看代码:
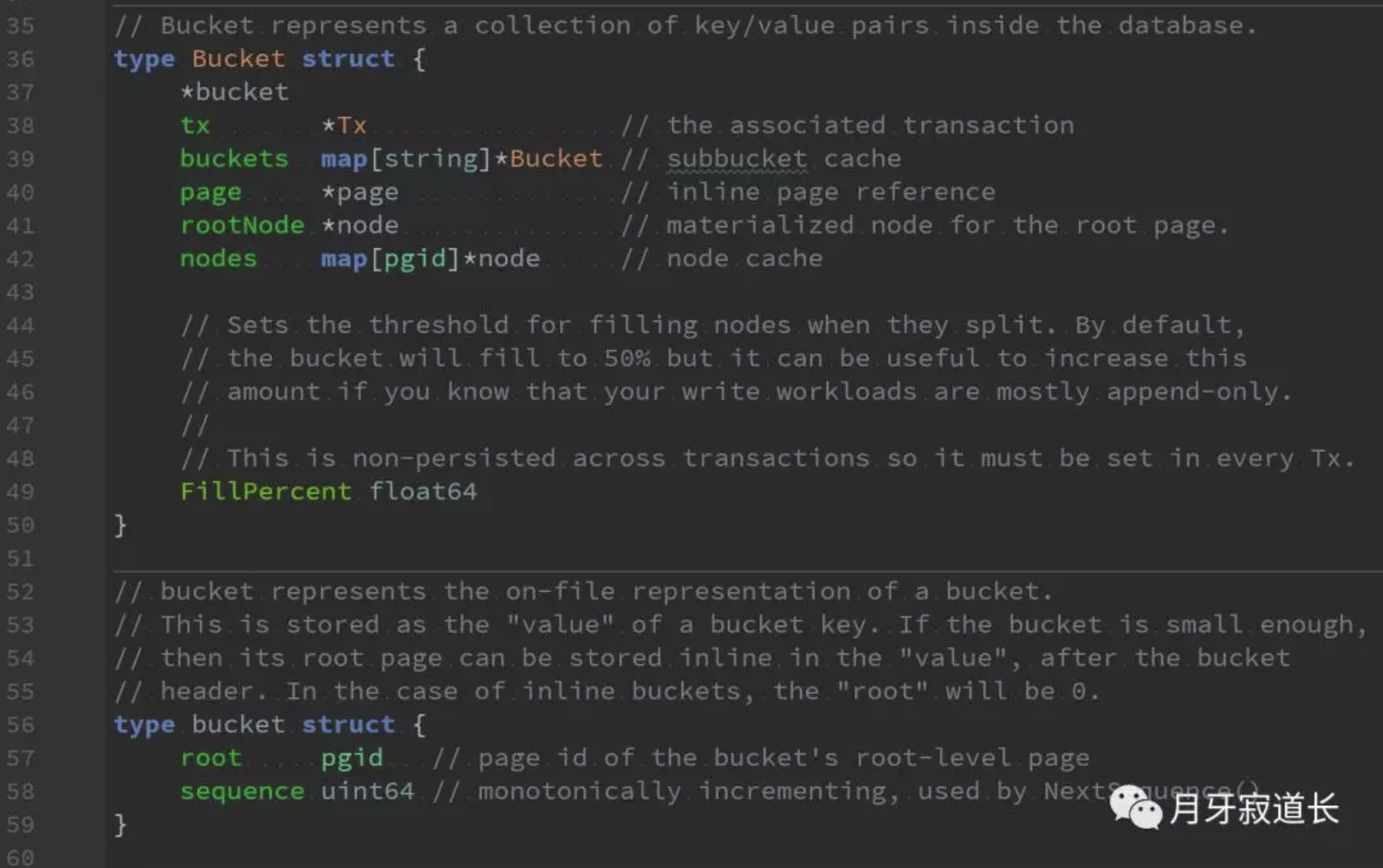
github.com/boltdb/bolt/bucket.go
其中
root pgid // page id of the bucket's root-level page
root就是bucket所在的根
tx *Tx // the associated transaction
事务,每一次对数据库的操作是一次事务,每次事务都是一次探索定位,修改或读取数据
过程
buckets map[string]*Bucket // subbucket cache
探索过程中,缓存记录下已经探索过的buckets
nodes map[pgid]*node // node cache
探索过程中,缓存记录下已经探索过的node
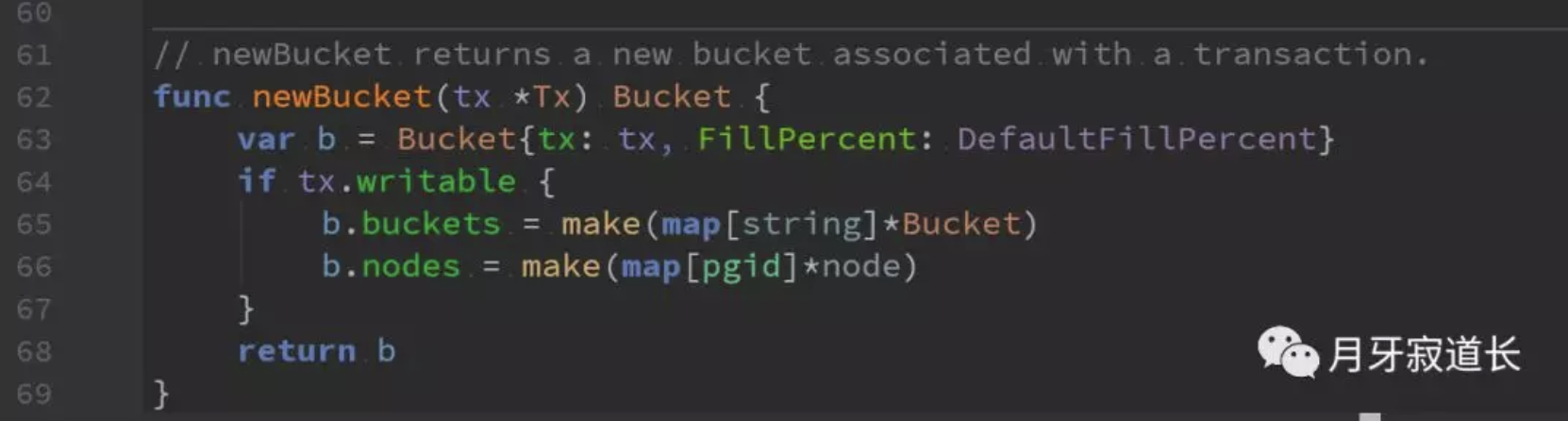
初始化。这里面只是初始化了tx。
另外这里根据是否是读操作还是写操作,来初始化buckets和nodes
github.com/boltdb/bolt/tx.go
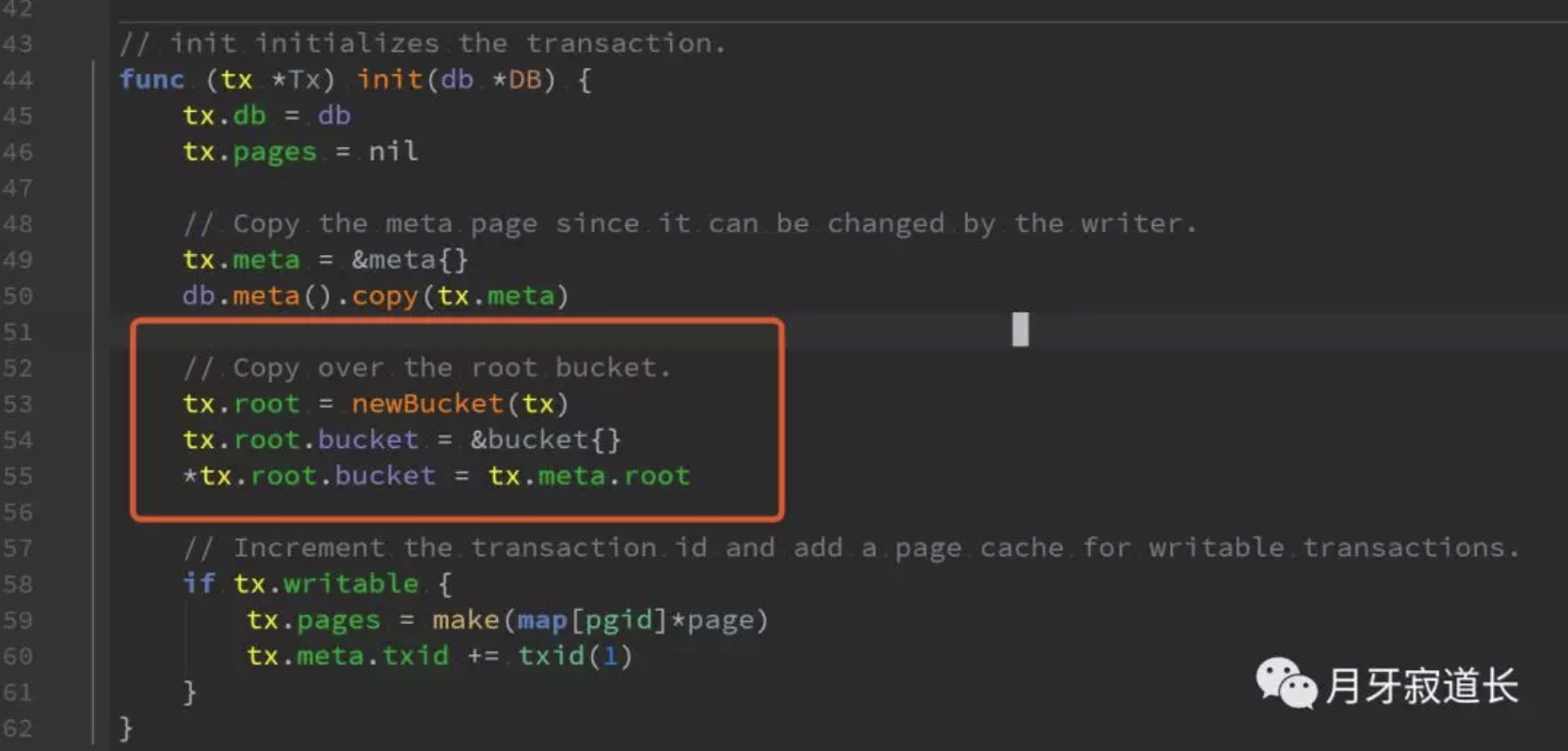
我们看下如何设置root,这个是tx里面的代码。红色框中,显示了bucket的root是从meta root中获取的。
因为bucket是可以嵌套的,也就是说bucket中,不仅仅可以包含key value数据,也可以嵌套包含bucket。
那么下面一步一步分析
github.com/boltdb/bolt/bucket.go
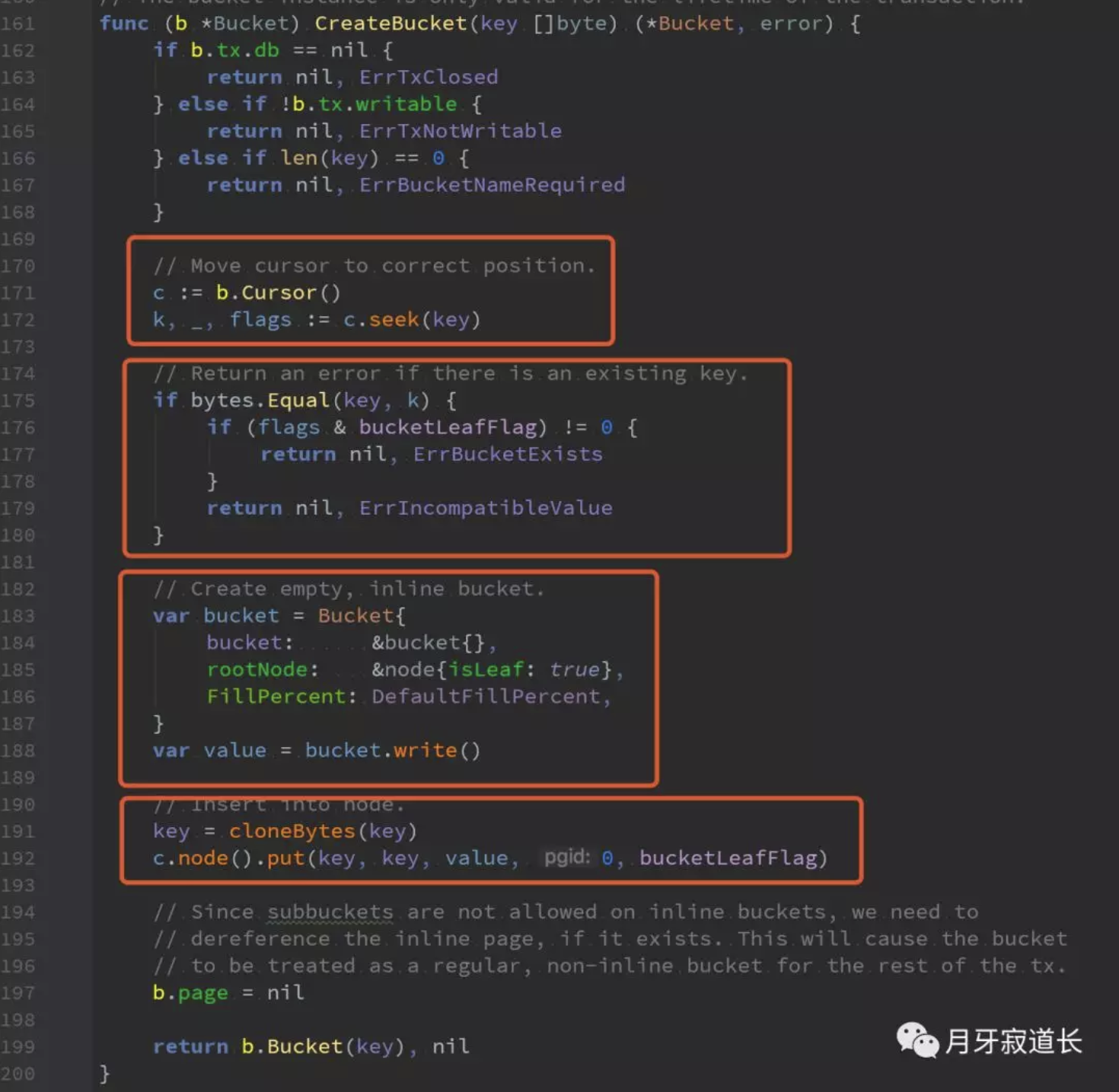
要创建一个bucket
1、通过游标进行查找,查找到所对应key的node数据结构。
2、找到了,对应的node结构是不是bucket类型,是则返回,已经存在的err。否则就类型不匹配err
3、没有找到,则创建一个bucket。并将rootnode初始化为isLeaf
其中bucket.write是将bucket结构数据生成page内存数据
4、然后将写入到node中
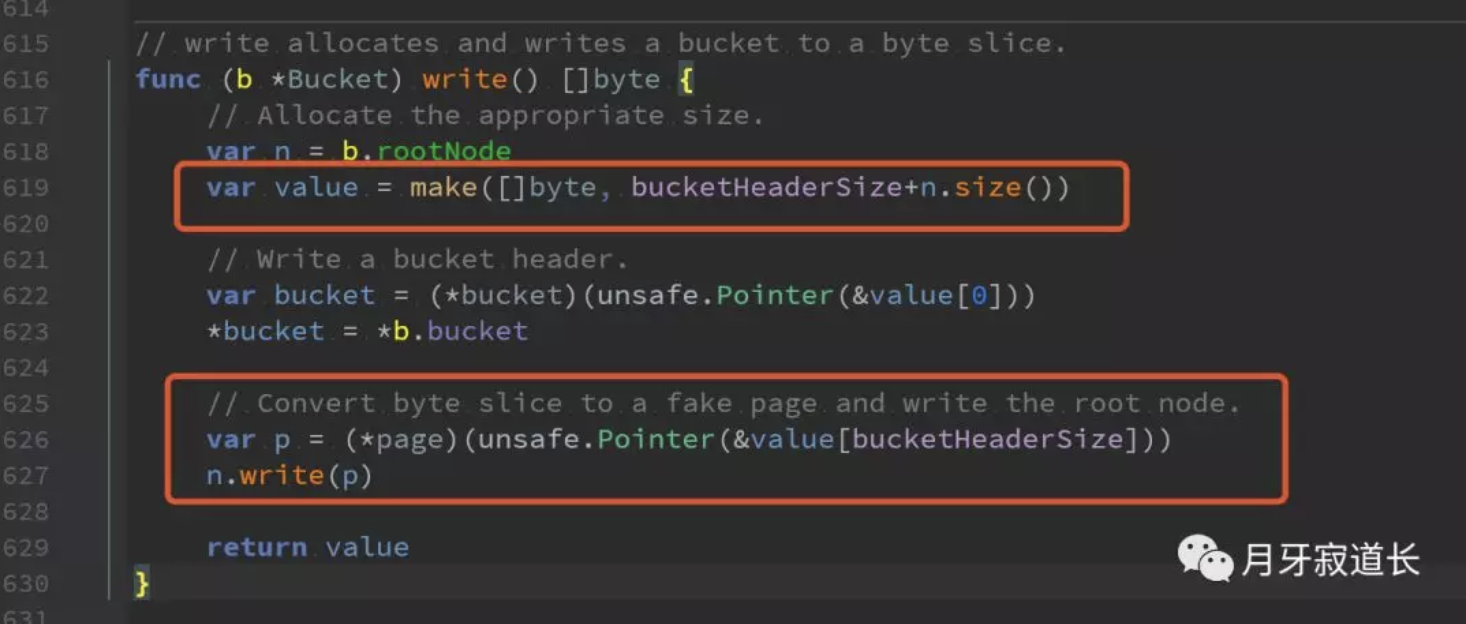
这里面就将bucket的头部dump到了page中。
n.write(p)
就是node数据的dump
然后回到函数CreateBucket中
c.node().put(key, key, value, 0, bucketLeafFlag)
这里将bucket所对应的node结构数据放到游标所对应的node中。
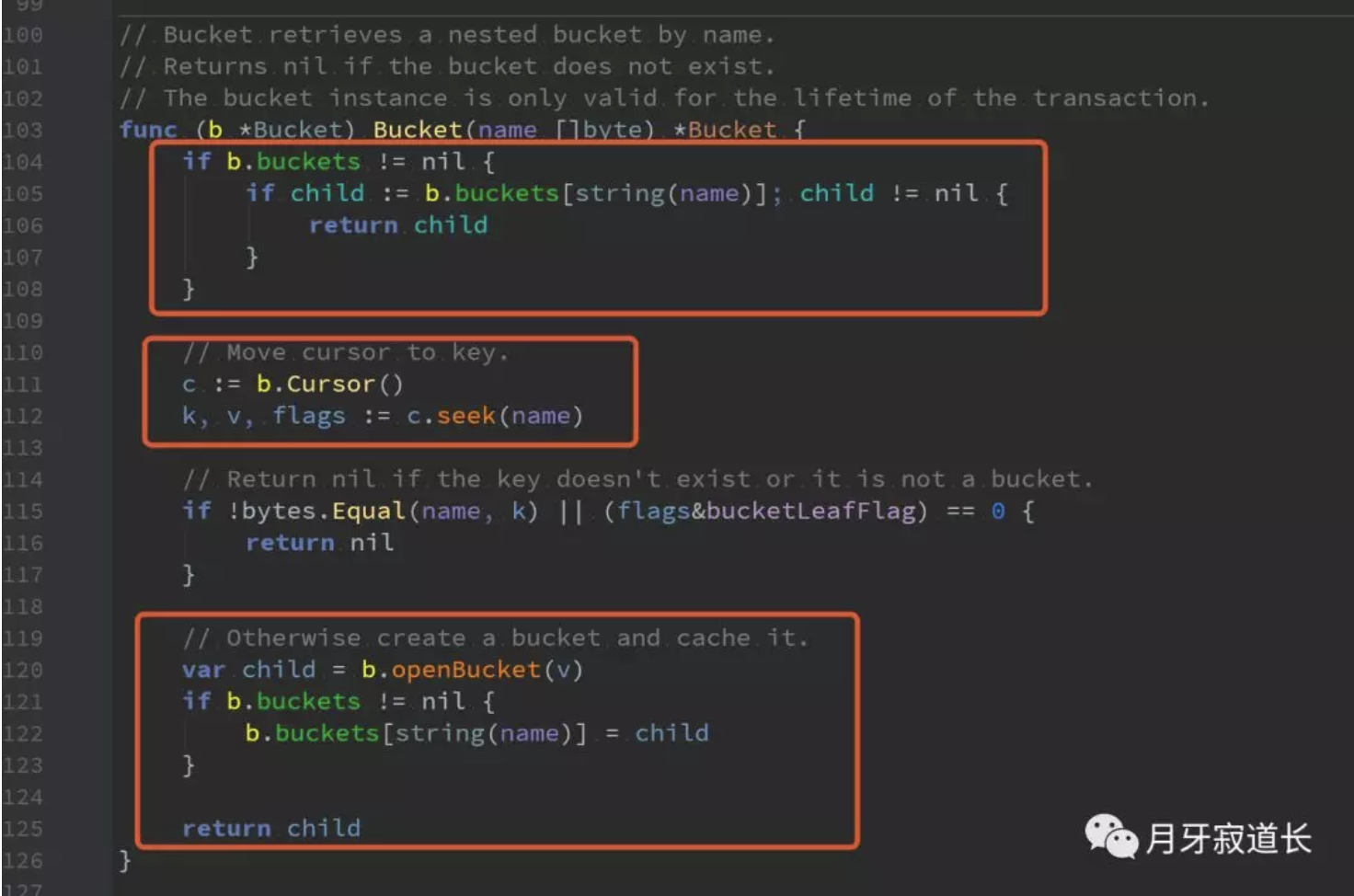
上面是查找bucket。
1、看看buckets缓存记录中有没有,有,则直接返回
2、通过游标查找定位。
3、判断类型是否匹配
4、查找到后,要做一次转化成bucket。并将其放入到buckets记录缓存中。
5、最后返回
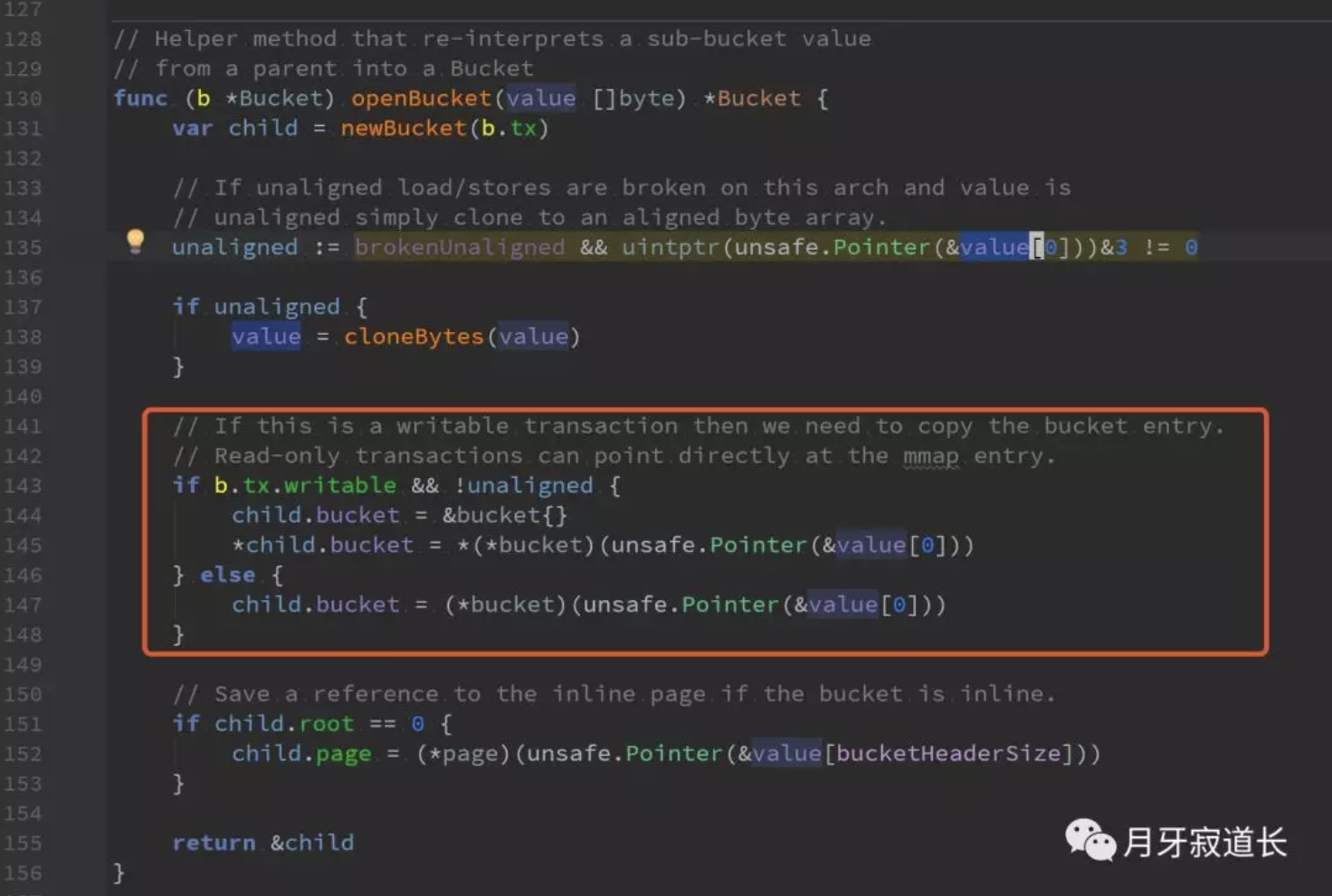
以上就是将查找到的value数据转换成bucket类型。
以上是对bucket的创建和读取。
下面是对key Value的读写
put写
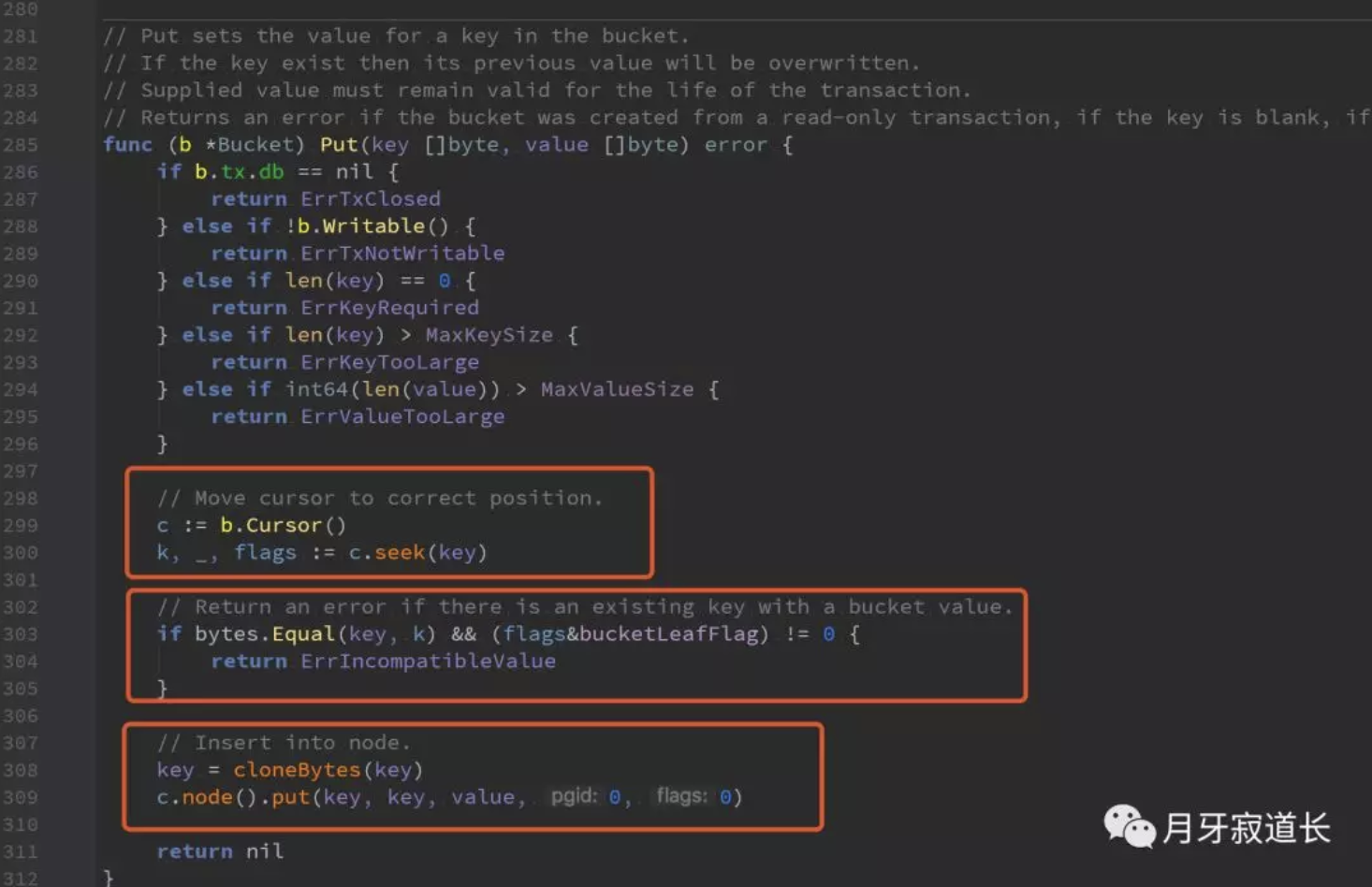
这是设置key Value。还是通过游标查找key所在的node,然后判断node类型,类型不对的话是会返回err的。
最后是将key value写入到node中。
Get读
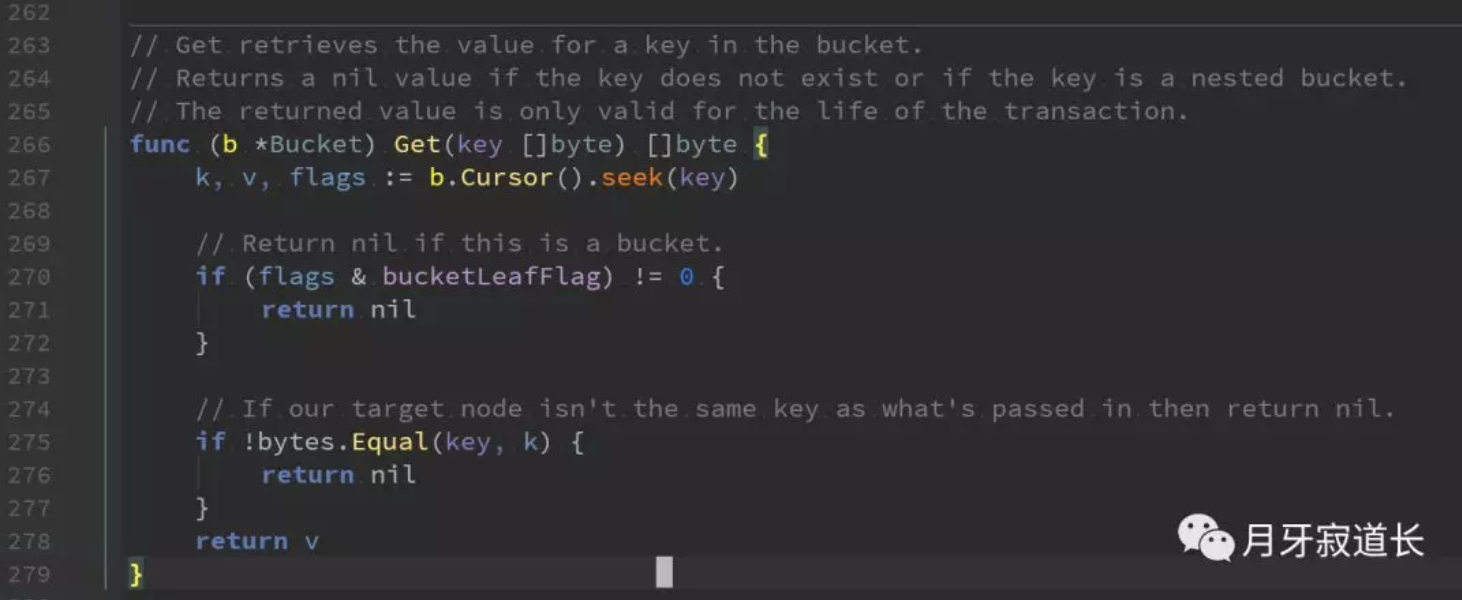
直接通过游标查找,这个很简单。
龚浩华
月牙寂道长
QQ 29185807
2018年04月12日
如果你觉得本文对你有帮助,可以转到你的朋友圈,让更多人一起学习。
第一时间获取文章,可以关注本人公众号:月牙寂道长,也可以扫码关注
