Spring扩展点之番外篇(自定义标签)
文章目录
1. 自定义标签简介
在之前的文章中,我们在深入源码分析SpringIOC(一)的章节里提到了IOC容器读取Bean的过程是定位、加载、注册,而在加载的过程中,我们分析到,Spring会判断是否是自定义标签,如果不是自定义的话,将会使用Spring的规则去解析标签,例如<import/>、<bean/>,将标签转换成DOM对象,进而将对象转换成BeanDefinition,将其注册进beanFactory中。那么如果不是Spring的规则的标签,也就是自定义标签的话,Spring将会做什么事情去解析它呢?我们又如何使用自定义标签呢?
//使用Spring的Bean规则从Document的根元素开始进行Bean定义的Document对象
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
//Bean定义的Document对象使用了Spring默认的XML命名空间
if (delegate.isDefaultNamespace(root)) {
//获取Bean定义的Document对象根元素的所有子节点
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
//获得Document节点是XML元素节点
if (node instanceof Element) {
Element ele = (Element) node;
//Bean定义的Document的元素节点使用的是Spring默认的XML命名空间
if (delegate.isDefaultNamespace(ele)) {
//使用Spring的Bean规则解析元素节点
parseDefaultElement(ele, delegate);
}
else {
//没有使用Spring默认的XML命名空间,则使用用户自定义的解析规则解析元素节点
delegate.parseCustomElement(ele);
}
}
}
}
else {
//Document的根节点没有使用Spring默认的命名空间,则使用用户自定义的
//解析规则解析Document根节点
delegate.parseCustomElement(root);
}
}
这段代码是在IOC加载Bean配置的一个方法,此过程将加载到的Document对象进行解析成BeanDefinition。
可见,这里有几个关键的判断点:
-
当Spring拿到一个元素时首先做的是根据命名空间进行解析,判断标签是否为Spring默认的XML命名空间 。
-
如果是Spring默认的XML命名空间,还会再判断一次它的子节点。
-
凡是判断到不是默认的命名空间时,都会使用自定义的解析规则。什么意思呢?
<bean> <custom:demo id="test" name="aaa" /> </bean> <custom:demo id="test2" name="bbb" />也就是说,上述两种标签,都会被自定义解析。
自定义标签的使用场景有很多,一个功能或是框架如果要集成Spring,自定义标签起到了关键的作用,例如dubbo、AOP、事务等等,都是由配置文件的一个标签开启的。例如:
<!-- 开启AOP -->
<aop:aspectj-autoproxy />
<!-- 开启事务@Transactional注解支持 -->
<tx:annotation-driven proxy-target-class="true" transaction-manager="transactionManager"/>
2. 自定义标签的使用
这里会先介绍自定义标签是如何使用的,然后会给出一个很常用的自定义标签并解析它,最后再透过这些现象深入源码看原理。
自定义标签格式:
<"命名空间":"解析名" />
(1) 首先创建一个普通的POJO,用于模拟自定义标签构造出的对象(User.Class):
/**
* @author linyh
*/
public class User {
private Integer id;
private String name;
//get set toString方法 略..
}
(2) 然后是一个xsd文件描述如何解析标签内元素(具体查询Schema用法):
<?xml version="1.0" encoding="UTF-8" ?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.linyh.com/schema/user"
elementFormDefault="qualified">
<element name="user">
<complexType>
<attribute name="id" type="integer"/>
<attribute name="name" type="string"/>
</complexType>
</element>
</schema>
(3) 创建一个类,实现BeanDefinitionParser(这里为了方便,直接继承实现好了的抽象类AbstractSingleBeanDefinitionParser):
/**
* @author linyh
*/
public class CustomTagParser extends AbstractSingleBeanDefinitionParser {
protected Class getBeanClass(Element element){
//代表Bean的类为User.class
return User.class;
}
@Override
protected void doParse(Element element, BeanDefinitionBuilder builder) {
//解释如何从Element对象解析成Bean的对象
Integer id = Integer.parseInt(element.getAttribute("id"));
String name = element.getAttribute("name");
builder.addPropertyValue("id", id);
builder.addPropertyValue("name", name);
}
}
(4) 创建一个Handler,其作用为初始化解析类,如上CustomTagParser解析类:
/**
* @author linyh
*/
public class CustomTagNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
//意思是读取到user标签的,都将使用CustomTagParser类进行解析
registerBeanDefinitionParser("user", new CustomTagParser());
}
}
(5) 创建两个文件,这是Spring约定的,照做就好了,如果需要修改,需修改Spring源码:
- Spring.handlers (指定命名空间对应的Hadler)
http\://www.linyh.com/schema/user=com.mytest.demo.customtag.CustomTagNamespaceHandler
- Spring.schemas (指定xsd的资源路径)
http\://www.linyh.com/schema/user.xsd=META-INF/Spring-test.xsd
(6) 测试
首先创建一个配置文件,按照我们的规则去配置一个Bean:
<?xml version="1.0" encoding="UTF-8" ?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xxx="http://www.linyh.com/schema/user"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://www.linyh.com/schema/user http://www.linyh.com/schema/user.xsd">
<xxx:user id="1" name="test"/>
</beans>
然后创建一个main,看看容器中是否能拿到此对象:
/**
* @author linyh
*/
public class CustomtagTest {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("test.xml");
User user = (User) context.getBean("test");
System.out.println(user);
}
}
控制台打印:
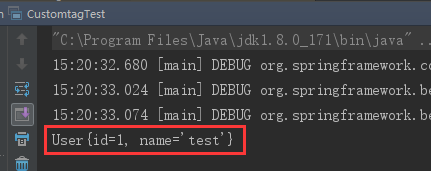
此时自定义解析成功了。这里引出一个例子,我们使用占位符配置Bean的时候是这样的:
<jee:jndi-lookup id="dataSource" jndi-name="${dataSource.jndi}"/>
那么此时占位符是如何被转换的呢?如果你不配置以下标签,将不能使用占位符:
<context:property-placeholder location="classpath:demo.properties" />
从上面的自定义标签的使用受到启发,我们可以从命名空间入手,找到配置头,发现如下配置:
xmlns:context="http://www.springframework.org/schema/context"
我们全局搜索此命名空间(http后面加一个\符号,为了找到命名空间对应的Handler类):
http\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler
我们找到了Spring.handlers文件,这里说明了这个自定义标签的Handler类到底是哪一个,进入此类看看:
public class ContextNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
//这里标签是property-placeholder,所以只解析这一行
registerBeanDefinitionParser("property-placeholder", new PropertyPlaceholderBeanDefinitionParser());
registerBeanDefinitionParser("property-override", new PropertyOverrideBeanDefinitionParser());
registerBeanDefinitionParser("annotation-config", new AnnotationConfigBeanDefinitionParser());
registerBeanDefinitionParser("component-scan", new ComponentScanBeanDefinitionParser());
registerBeanDefinitionParser("load-time-weaver", new LoadTimeWeaverBeanDefinitionParser());
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
registerBeanDefinitionParser("mbean-export", new MBeanExportBeanDefinitionParser());
registerBeanDefinitionParser("mbean-server", new MBeanServerBeanDefinitionParser());
}
}
由上面代码看出,对应的解析类是PropertyPlaceholderBeanDefinitionParser:
@Override
protected Class<?> getBeanClass(Element element) {
//略...
return PropertyPlaceholderConfigurer.class;
}
此类负责解析标签,并且最后会将PropertyPlaceholderConfigurer 类型的Bean注册到IOC容器中,而这个类实现了BeanFactoryPostProcessor这个接口:
在我们上一篇文章讲到扩展Spring时有讲到,实现了BeanFactoryPostProcessor的Bean将会在Bean初始化之前修改Bean的配置,所以这里PropertyPlaceholderConfigurer 的实现原理正是读取我们标签中传进去的location资源文件路径,然后动态修改Bean的配置信息,然后根据修改后的配置信息对Bean进行初始化,达到配置时可以使用占位符的效果。例如有些项目的数据库账号密码由于安全问题不能明文保存在配置文件中,此时就可以自定义一个这样的自定义标签解析,在Parser类中去存放账号密码的服务器中动态读取账号密码,去初始化数据源DataSource的配置信息,这样,就不必明文将账号密码保存在文件中,而是存放在服务器中去了。
3. 深入源码分析自定义标签实现原理
我们把思路回到开头,我们说到Spring在加载资源时会选择是使用自定义解析还是Spring定义的解析方式,如果是自定义解析,将调用以下方法:
//自定义解析的入口
delegate.parseCustomElement(ele);
@Nullable
public BeanDefinition parseCustomElement(Element ele) {
return parseCustomElement(ele, null);
}
@Nullable
public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
//首先根据标签头,获取命名空间
String namespaceUri = getNamespaceURI(ele);
if (namespaceUri == null) {
return null;
}
//根据命名空间去初始化对应Handler(init)并获取Handler
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
//调用对应的Handler的对应Parser解析
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
将此方法分为三个步骤:
- 获取命名空间
- 根据命名空间,拿到对应的
Handler - 最后根据
Handler注册的Parser中选择相应的Parser进行解析
3.1 获取Handler
有了命名空间,我们就能根据命名空间去Spring.handlers文件拿到Handler了,这个过程是怎样的呢?进入上面的resolve 方法(readerContext中的NamespaceHandlerResolver 在之前已经被初始化为DefaultNamespaceHandlerResolver):
@Override
@Nullable
public NamespaceHandler resolve(String namespaceUri) {
//获取所有Hanlder的映射关系,命名空间对应Handler
Map<String, Object> handlerMappings = getHandlerMappings();
//根据命名空间获取Handler,如果是第一次获取,只是获取Handler类路径
Object handlerOrClassName = handlerMappings.get(namespaceUri);
if (handlerOrClassName == null) {
return null;
}
//如果类型以及是NamespaceHandler,说明不是第一次获取,直接从缓存取出
else if (handlerOrClassName instanceof NamespaceHandler) {
return (NamespaceHandler) handlerOrClassName;
}
//到这里说明此时Map存放的还只是类路径
else {
//String类型的类路径
String className = (String) handlerOrClassName;
try {
//使用反射将Handler转换成类
Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);
if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {
throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +
"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");
}
//初始化此Handler
NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);
//调用Handler的init方法
namespaceHandler.init();
//将处理好的Handler放入缓存方便下次取出
handlerMappings.put(namespaceUri, namespaceHandler);
return namespaceHandler;
}
//Catch 略..
}
}
此时我们知道了为什么要复写Handler的init方法,在取出Handler的时候将会调用init方法,其作用就是将指定规则和Parser注册进Handler中。这里看看getHandlerMappings 方法是如何获取Handler的映射关系的:
private Map<String, Object> getHandlerMappings() {
Map<String, Object> handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
synchronized (this) {
handlerMappings = this.handlerMappings;
if (handlerMappings == null) {
try {
//从约定的路径中加载资源文件
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
if (logger.isDebugEnabled()) {
logger.debug("Loaded NamespaceHandler mappings: " + mappings);
}
Map<String, Object> mappingsToUse = new ConcurrentHashMap<>(mappings.size());
//将资源文件中的命名空间与Handler路径的映射关系存放在Map中
CollectionUtils.mergePropertiesIntoMap(mappings, mappingsToUse);
handlerMappings = mappingsToUse;
this.handlerMappings = handlerMappings;
}
//catch 略..
}
}
}
return handlerMappings;
}
值得一提的是,我们前面提到,NamespaceHandlerResolver默认被初始化成 DefaultNamespaceHandlerResolver这个类,在初始化资源对象时使用了类中属性handlerMappingsLocation :
Properties mappings = PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
我们追踪DefaultNamespaceHandlerResolver的handlerMappingsLocation这个属性,发现这个属性在其构造函数中就已经指定好了:
/**
* The location to look for the mapping files. Can be present in multiple JAR files.
*/
public static final String DEFAULT_HANDLER_MAPPINGS_LOCATION = "META-INF/spring.handlers";
public DefaultNamespaceHandlerResolver(@Nullable ClassLoader classLoader) {
//使用了约定好的资源路径
this(classLoader, DEFAULT_HANDLER_MAPPINGS_LOCATION);
}
public DefaultNamespaceHandlerResolver(@Nullable ClassLoader classLoader, String handlerMappingsLocation) {
Assert.notNull(handlerMappingsLocation, "Handler mappings location must not be null");
this.classLoader = (classLoader != null ? classLoader : ClassUtils.getDefaultClassLoader());
this.handlerMappingsLocation = handlerMappingsLocation;
}
所以,这里也能解释为什么要在固定路径创建spring.handlers文件了。
3.2 使用Handler调用对应的Parser
回到主线,当用命名空间拿到了对应的Handler之后调用handler的parse方法:
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
@Nullable
private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) {
//获取标签元素,例如<xxx:user/>,此时locaName就是user
String localName = parserContext.getDelegate().getLocalName(element);
//根据user获取对应的Parser
BeanDefinitionParser parser = this.parsers.get(localName);
if (parser == null) {
parserContext.getReaderContext().fatal(
"Cannot locate BeanDefinitionParser for element [" + localName + "]", element);
}
return parser;
}
我们可以先来回忆一下我们的Handler的init方法做了什么:
public void init() {
registerBeanDefinitionParser("user", new CustomTagParser());
}
这里就将user与对应的Parser类对应了起来,在上面就可以根据标签元素,例如user,获取到CustomTagParser,到这里,我们可以明白为什么需要init方法注册Parser,并且只要你init中注册了对应元素的解析器,在init中就可以注册多个标签元素例如<xxx:a/> 、<xxx:b/>等等,其都属于xxx这个命名空间之下。
回到主线,在取出Parser之后,调用了Parser的parse方法:
@Override
@Nullable
//由于这里我们的示例是继承了一个抽象的Parser类,省去了编写一些方法的麻烦
//所以这里parse方法其实调用的是父类AbstractBeanDefinitionParser的parse
public final BeanDefinition parse(Element element, ParserContext parserContext) {
//parseInternal是一个抽象方法,由子类实现,获取一个BeanDefinition
AbstractBeanDefinition definition = parseInternal(element, parserContext);
if (definition != null && !parserContext.isNested()) {
try {
String id = resolveId(element, definition, parserContext);
if (!StringUtils.hasText(id)) {
parserContext.getReaderContext().error(
"Id is required for element '" + parserContext.getDelegate().getLocalName(element)
+ "' when used as a top-level tag", element);
}
String[] aliases = null;
if (shouldParseNameAsAliases()) {
String name = element.getAttribute(NAME_ATTRIBUTE);
if (StringUtils.hasLength(name)) {
aliases = StringUtils.trimArrayElements(StringUtils.commaDelimitedListToStringArray(name));
}
}
//将获取到的BeanDefinition封装为BeanDefinitionHolder
BeanDefinitionHolder holder = new BeanDefinitionHolder(definition, id, aliases);
//将封装好的Holder注册进IOC容器中
registerBeanDefinition(holder, parserContext.getRegistry());
if (shouldFireEvents()) {
BeanComponentDefinition componentDefinition = new BeanComponentDefinition(holder);
postProcessComponentDefinition(componentDefinition);
parserContext.registerComponent(componentDefinition);
}
}
catch (BeanDefinitionStoreException ex) {
String msg = ex.getMessage();
parserContext.getReaderContext().error((msg != null ? msg : ex.toString()), element);
return null;
}
}
return definition;
}
//获取BeanDefinition的方法由子类实现
@Nullable
protected abstract AbstractBeanDefinition parseInternal(Element element, ParserContext parserContext);
这里我们可以知道,解析过程其实是将解析好的元素转换成BeanDefinition,然后注册进IOC容器,达到自定义解析自定义标签成Bean的效果。这里看看子类实现的parseInternal方法是如何获取BeanDefinition的:
@Override
//这里还是抽象类的方法,在AbstractSingleBeanDefinitionParser中
protected final AbstractBeanDefinition parseInternal(Element element, ParserContext parserContext) {
//创建一个可以创建BeanDefinition的对象,对其填充信息,在最后可以使用其生成BeanDefinition
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition();
String parentName = getParentName(element);
if (parentName != null) {
builder.getRawBeanDefinition().setParentName(parentName);
}
//子类复写该方法,实现调用getBeanClass可以获取元素的类
Class<?> beanClass = getBeanClass(element);
if (beanClass != null) {
builder.getRawBeanDefinition().setBeanClass(beanClass);
}
else {
String beanClassName = getBeanClassName(element);
if (beanClassName != null) {
builder.getRawBeanDefinition().setBeanClassName(beanClassName);
}
}
builder.getRawBeanDefinition().setSource(parserContext.extractSource(element));
BeanDefinition containingBd = parserContext.getContainingBeanDefinition();
if (containingBd != null) {
// Inner bean definition must receive same scope as containing bean.
builder.setScope(containingBd.getScope());
}
if (parserContext.isDefaultLazyInit()) {
// Default-lazy-init applies to custom bean definitions as well.
builder.setLazyInit(true);
}
//子类复写该方法,实现对BeanDefinition进行进一步的填充
doParse(element, parserContext, builder);
//由设置好的信息生成一个BeanDefinition返回
return builder.getBeanDefinition();
}
到了这里,我们应该明白了,为什么要复写一个getBeanClass方法,此方法将获得自定义标签所要注册的Bean的类型,而doParse将实现进一步填充BeanDefinition的方法。
4.总结
到这里,我们就已经完成了对自定义标签的解析。我们从自定义的标签的使用到举例这两个步骤看现象,透过现象深入源码看本质,如果你理解了这些底层原理,相信使用自定义标签去扩展Spring将会得心应手。在我们熟知的dubbo框架中你可以在MATA-INF文件夹下发现我们上面介绍到的两个配置文件,此时是否可以理解这是为什么了。当我们遇到自定义标签的时候,可以更快的找到路口,例如:
<context:component-scan base-package="com.test.demo"/>
此时你的第一反应应该是查看context对应的命名空间,然后全局搜索命名空间,找到对应的Handler,在init 方法中找到component-scan注册的对应的Parser,然后查看parse方法究竟做了什么,还有Parser的getBeanClass 方法查看此标签要注册的Bean的Class类型。
有了自定义标签,我们可以使用自定义标签方式去配置Bean,并将其注册到IOC容器中。
此篇文章需要在上一篇文章的基础上阅读,因为这里的自定义标签的作用一般来说都是注册一些BeanFactoryPostProcessor或是BeanPostProcessor这类的类来对其他一些Bean进行扩展的,而这些类的使用在上一篇文章中有详细的讲解。