前几天有些搁置,希望能赶紧把最近所学的写下来,仅仅过了几天记忆以及没那么清晰了,仍然和前面一样,自己理解不对的地方还请明白的朋友指出来,再次谢过~这一篇介绍隐层,其实现在linear.cc, recurrency.cc里面。这里通过is_recurrent可以方便的设置隐层是否为循环网络。对于is_recurrent == true, 表示循环结构的神经网络,其示意图如下:

注意这里我把输入层的细节省略掉了,直接用了一个长椭圆代替,事实上rwthlm里面循环结构的网络输入层并不是这样的,后面会给出介绍,上面的图是整体纵向来看的,也是很多论文里面直接这样的图,但我始终觉的这个图只能给一个整体的感觉,无法更直观的看出这个网络的计算顺序,误差流向,以及时间轴的关系等。我把过程的全图做了下,对于网络的rnn ( recurrent neural network 后面都用这样的简称) 结构,其前向计算的过程是下面这张图:

这个图应该要清楚得多,首先在t=0时刻,即句子的开始处,进行第一次前向计算,在t = 1时刻时,计算第二个,这次隐层的输入来源就有t = 0时刻的了,然后继续下去。这里的时间轴其实就是对应着句子里面词语训练的顺序。在进行了批量的前向计算后,开始BPTT算法,其过程如下图:
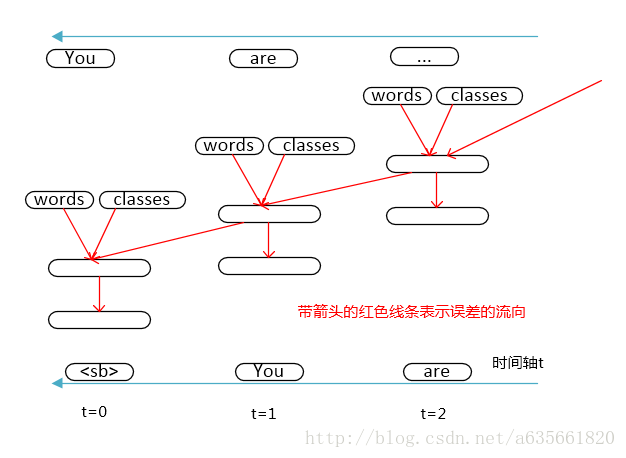
注意这里的时间轴是从t= 2开始往后面走了,红色的线段表示误差的流向,从输出层开始往输入层流,由于rnn结构的特性,误差的流向从时间轴上来看又从现在往过去流,这样就解释清楚rnn的运作了。
下面看看部分rnn实现的核心代码,如下:
#include <cmath>
#include "fast.h"
#include "recurrency.h"
Recurrency::Recurrency(const int output_dimension,
const int max_batch_size,
const int max_sequence_length,
Real *&b, //说明b是指向rela类型的指针,并且它是实参的别名
Real *&b_t,
Real *&delta,
Real *&delta_t)
//Function前两个参数是input_dimension,output_dimension.
: Function(0, output_dimension, max_batch_size, max_sequence_length),
b_(b),
b_t_(b_t),
delta_(delta),
delta_t_(delta_t) {
recurrent_weights_ = FastMalloc(output_dimension * output_dimension);
momentum_recurrent_weights_ = FastMalloc(output_dimension *
output_dimension);
}
//循环结构下,计算隐层的输入
const Real *Recurrency::Evaluate(const Slice &slice, const Real x[]) {
// b_{-1} = 0
//当t为初始时刻0时,将不计算上面的部分,就好像b_(-1)_等于0一样
if (b_t_ != b_) {
//b_t_ <= b_t_ + recurrent_weights_ * (b_t_ - GetOffset())
//这里的b_t_ - GetOffset()即是b_(t-1)_,表示t-1时刻隐层的输出
//现在才体会到这种数据结构的好处,如此方便的就实现了循环网络的结构,而且在输出层的word部分能够并行
FastMatrixMatrixMultiply(1.0,
recurrent_weights_,
false,
output_dimension(),
output_dimension(),
b_t_ - GetOffset(),
false,
slice.size(),
b_t_);
}
return b_t_;
}
void Recurrency::ComputeDelta(const Slice &slice, FunctionPointer f) {
// delta_{T+1} = 0
//将程序执行到一个句子末尾时记作t+1时刻,这个时候delta_t_ == delta
//将不执行下面的条件语句,相当于delta_{T+1} = 0
if (delta_t_ != delta_) {
//下面这句注释我的理解是:在整个句子组织的数据结构中,一个batch_size里面是由句子的长度
//从大到小排列的,这样slice.size(){t}>=slice.size{t+1}
// batch_size_t >= batch_size_{t+1}, so delta_{t+1}_ must be filled with 0
//delta_t_ <= delta_t_ + recurrent_weights_^T * (delta_t_ - GetOffset())
//含义就是把m+1时刻隐层的误差传到m时刻隐层上
FastMatrixMatrixMultiply(1.0,
recurrent_weights_,
true,
output_dimension(),
output_dimension(),
delta_t_ - GetOffset(),
false,
slice.size(), // smaller batch_size suffices,这里的注释意思是m+1时刻对应的误差信号矩阵的列却
delta_t_); //用了m时刻的误差信号矩阵的列,但由于m时刻的列大于m+1时刻的列,所以大小足够
}
}
void Recurrency::AddDelta(const Slice &slice, Real delta_t[]) {
}
const Real *Recurrency::UpdateWeights(const Slice &slice,
const Real learning_rate,
const Real x[]) {
// b_{-1} = 0
//当t为初始时刻0时,将不计算上面的部分,就好像b_(-1)_等于0一样
if (b_t_ != b_) {
//momentum_recurrent_weights_ <= -learning_rate* delta_t_ * (b_t_ - GetOffset())^T + momentum_recurrent_weights_
//这里积累隐层自循环的权值的改变
FastMatrixMatrixMultiply(-learning_rate,
delta_t_,
false,
output_dimension(),
slice.size(),
b_t_ - GetOffset(),
true,
output_dimension(),
momentum_recurrent_weights_);
}
return b_t_;
}
上面是循环部分,另一部分是非循环部分,对于is_recurrent = flase, 表示该层是非循环的,简图如下:
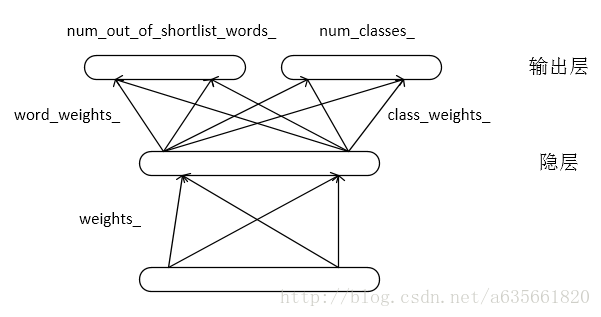
两个一维数组的指针,其中b_保存隐层的输入输出, delta_保存隐层的误差信号相关计算,这个结构如图,仍然和output.cc里面的结构一样
b_ = FastMalloc(output_dimension * max_batch_size * max_sequence_length);
delta_ = FastMalloc(output_dimension * max_batch_size * max_sequence_length);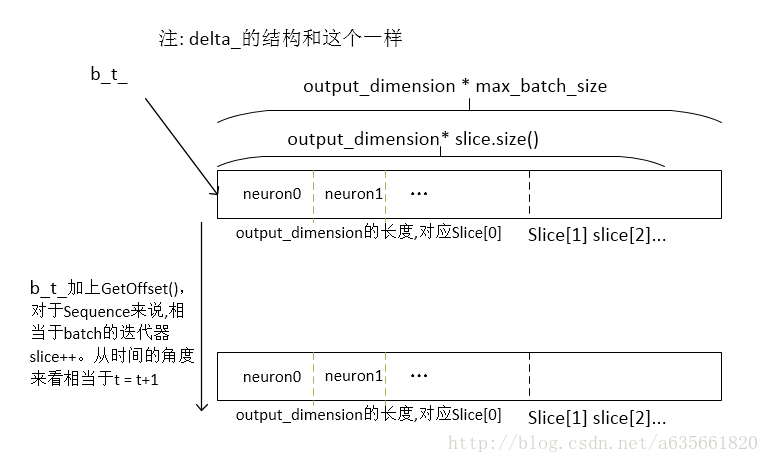
其余的内容就在代码的注释上了,下面是linear.cc的实现,只贴了核心实现。注意is_recurrent的嵌入,它是一个开关,一个打开隐层是否循环的开关,这个工具的设计确实非常灵活,感觉作者不仅能做科研,而且写代码也好厉害!!!
#include <memory>
#include "fast.h"
#include "linear.h"
#include "recurrency.h"
Linear::Linear(const int input_dimension,
const int output_dimension,
const int max_batch_size,
const int max_sequence_length,
const bool is_recurrent,
const bool use_bias,
ActivationFunctionPointer activation_function)
: Function(input_dimension,
output_dimension,
max_batch_size,
max_sequence_length),
activation_function_(std::move(activation_function)){
//b_保存隐层的输入输出,这个结构如图,仍然和output.cc里面的结构一样
//这里不分class, word部分,结构更为简单一些。
b_ = FastMalloc(output_dimension * max_batch_size * max_sequence_length);
//保存隐层的误差信号相关计算,这个结构和b_一样
delta_ = FastMalloc(output_dimension * max_batch_size * max_sequence_length);
//隐层和前一层的权值矩阵
weights_ = FastMalloc(output_dimension * input_dimension);
//输出层的偏置向量
bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
//隐层到前一层的momentum权重,用来累加权重的改变
momentum_weights_ = FastMalloc(output_dimension * input_dimension);
momentum_bias_ = use_bias ? FastMalloc(output_dimension) : nullptr;
//如果是循环神经网络结构,便生成Recurrency对象
//这里可以看到该开源工具程序设计上的巧妙之处,在前馈的神经网络中,同过这种方式
//便十分灵活的提供了两种网络结构出来,以前看rnnlm时,只是纯循环神经网络的结构
//感觉在程序设计上面这个工具确实设计的很棒啊!
if (is_recurrent) {
//构造函数的行参是传进去的指针的别名
recurrency_ = RecurrencyPointer(new Recurrency(output_dimension,
max_batch_size,
max_sequence_length,
b_,
b_t_,
delta_,
delta_t_));
}
}
//计算隐层的输出
//x表示前一层的输入
const Real *Linear::Evaluate(const Slice &slice, const Real x[]) {
if (bias_) {
//如果存在偏置向量,则拷贝到b_t_
for (size_t i = 0; i < slice.size(); ++i)
FastCopy(bias_, output_dimension(), b_t_ + i * output_dimension());
}
//b_t_ <= b_t_ + weights_ * x
//计算隐层的输入
FastMatrixMatrixMultiply(1.0,
weights_,
false,
output_dimension(),
input_dimension(),
x,
false,
slice.size(),
b_t_);
//假设当前时刻不是初始时刻,即t!=0,如果存在循环结构
//则计算如下:
//b_t_ <= b_t_ + recurrent_weights_*b_(t-1)_
//上面式子右边b_t_表示t时刻隐层的输入,b_(t-1)_表示t-1时刻隐层的输出
//当t = 0即为初始时刻时,将不计算上面的部分
if (recurrency_)
recurrency_->Evaluate(slice, x);
//这里计算隐层的输出
activation_function_->Evaluate(output_dimension(), slice.size(), b_t_);
const Real *result = b_t_;
// let b_t_ point to next time step
//下一个word,从时间的角度来看,像是t = t + 1了
b_t_ += GetOffset();
return result;
}
//这里仍然提醒一下执行的顺序问题,Evaluate()执行是从句子的开始到句子结束
//然后到句子末尾时,才开始计算ComputeDelta()
void Linear::ComputeDelta(const Slice &slice, FunctionPointer f) {
// let b_t_ point to current time step
//让b_t_从句子的末尾往前走
b_t_ -= GetOffset();
// delta_t_ points to current time step
//下面delta_t获得上层传过来的误差,现在的delta_t_只是到达隐层的误差,下面是才是算隐层的误差
f->AddDelta(slice, delta_t_);
//重复的对这个函数进行执行,就会形成BPTT算法,这里我做了一张图来说明
if (recurrency_)
//将m+1时刻的误差信号传到m时刻隐层来,具体的值是保存在delta_t_中的
recurrency_->ComputeDelta(slice, f);
//计算该层的误差信号
activation_function_->MultiplyDerivative(output_dimension(), slice.size(),
b_t_, delta_t_);
}
//将隐层的误差信号再往前传
void Linear::AddDelta(const Slice &slice, Real *delta_t) {
// bias delta is zero
FastMatrixMatrixMultiply(1.0,
weights_,
true,
input_dimension(),
output_dimension(),
delta_t_,
false,
slice.size(),
delta_t);
// let delta_t_ point to previous time step
//相当于t = t -1,再次注意,对于b_t_最开始是t++的走的,到句子末尾时,才开始t--
//即b_t_指向数组最开头地址时表示着t=0,而delta_t_却相反,delta_t_指向数组首地址时,表示最末尾的时刻,这个时刻取决于句子的长度
delta_t_ += GetOffset();
}
//更新权值,x表示前面一层的输出
//更新的过程是从时刻0到t+1这样的过程
const Real *Linear::UpdateWeights(const Slice &slice,
const Real learning_rate,
const Real x[]) {
//delta_t_的走向是从t+1到0
delta_t_ -= GetOffset();
//存在偏置
if (bias_) {
for (size_t i = 0; i < slice.size(); ++i) {
//momentum_bias_ <= -learning_rate*delta_t_ + momentum_bias_
FastMultiplyByConstantAdd(-learning_rate,
delta_t_ + i * output_dimension(),
output_dimension(),
momentum_bias_);
}
}
//momentum_weights_ <= -learning_rate*delta_t_ *x^T + momentum_weights_
//相当于在积累权值的改变
FastMatrixMatrixMultiply(-learning_rate,
delta_t_,
false,
output_dimension(),
slice.size(),
x,
true,
input_dimension(),
momentum_weights_);
if (recurrency_)
//更新循环结构处的权值
recurrency_->UpdateWeights(slice, learning_rate, x);
const Real *result = b_t_;
// let b_t_ point to next time step
b_t_ += GetOffset();
return result;
}
void Linear::UpdateMomentumWeights(const Real momentum) {
//weights_ <= weights_ + momentum_weights_
//这里是正式改变网络的权值
FastAdd(momentum_weights_,
output_dimension() * input_dimension(),
weights_,
weights_);
//momentum_weights_ <= momentum_weights_ * momentum + momentum_weights_
FastMultiplyByConstant(momentum_weights_,
output_dimension() * input_dimension(),
momentum,
momentum_weights_);
if (bias_) {
//bias_ <= bias_ + momentum_bias_
FastAdd(momentum_bias_, output_dimension(), bias_, bias_);
//momentum_bias_ <= momentum_bias_ + momentum_bias_*momentum
FastMultiplyByConstant(momentum_bias_,
output_dimension(),
momentum,
momentum_bias_);
}
if (recurrency_)
recurrency_->UpdateMomentumWeights(momentum);
}