转载请注明地址
本次模拟系统,是利用Hadoop等组件来模拟巨型日志的处理系统,包括Python定时、Flume收集日志、MR处理日志、Sqoop导出数据、Hive的简单统计等,具体的架构如下:
一、项目架构
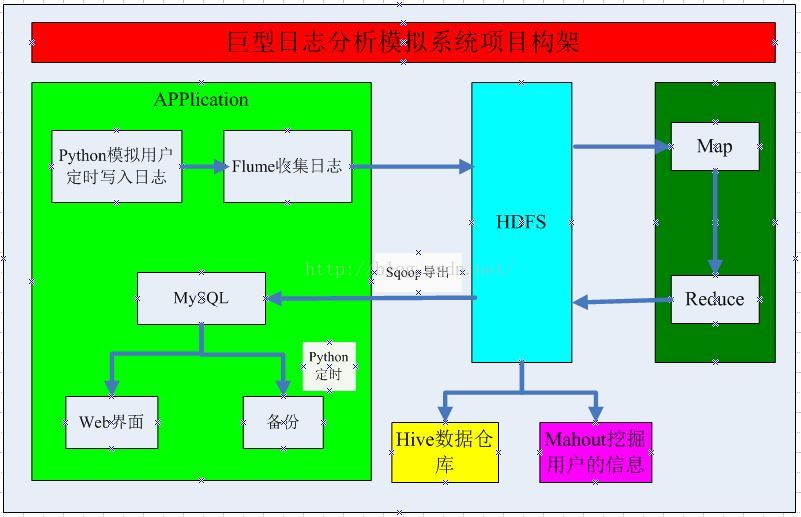
二、数据源下载
数据源我也是从csdn上下载的日志数据,想要的可以留下邮箱!
【注意:如何搞定时间不同,复制的文件也不同】
from datetime import date, time, datetime, timedelta
import os
def work(i):
if i>13:
data_path='/home/hadoop/LogModel/data/ex0412'+str(i)+'.log'
os.system("sudo cp "+data_path2+" /home/hadoop/LogModel/source/")
if i<10:
data_path='/home/hadoop/LogModel/data/ex05010'+str(i)+'.log'
os.system("sudo cp "+data_path2+" /home/hadoop/LogModel/source/")
if i>9 or i<14:
data_path1='/home/hadoop/LogModel/data/ex0412'+str(i)+'.log'
os.system("sudo cp "+data_path1+" /home/hadoop/LogModel/source/")
data_path2='/home/hadoop/LogModel/data/ex0501'+str(i)+'.log'
os.system("sudo cp "+data_path2+" /home/hadoop/LogModel/source/")
def runTask(func, day=0, hour=0, min=0, second=0):
# Init time
now = datetime.now()
strnow = now.strftime('%Y-%m-%d %H:%M:%S')
print("now:",strnow)
# First next run time
period = timedelta(days=day, hours=hour, minutes=min, seconds=second)
next_time = now + period
strnext_time = next_time.strftime('%Y-%m-%d %H:%M:%S')
print("next run:",strnext_time)
i=12
while(i<31):
# Get system current time
iter_now = datetime.now()
iter_now_time = iter_now.strftime('%Y-%m-%d %H:%M:%S')
if str(iter_now_time) == str(strnext_time):
i=i+1
# Get every start work time
print("start work: %s" % iter_now_time)
# Call task func
func(i)
print("task done.")
# Get next iteration time
iter_time = iter_now + period
strnext_time = iter_time.strftime('%Y-%m-%d %H:%M:%S')
print("next_iter: %s" % strnext_time)
# Continue next iteration
continuerunTask(work, min=0.5)
1、日志分布情况:
机子slave1上有个日志文件:/home/hadoop/LogModel/source1
机子slave2上有个日志文件:/home/hadoop/LogModel/source2
2、日志汇总:
机子hadoop上在HDFS中有个日志汇总文件:/LogModel/source
3、具体实现:
对于slave1主机:
#agent1
a1.sources=sc1
a1.sinks=sk1
a1.channels=ch1
#source1
a1.sources.sc1.type=spooldir
a1.sources.sc1.spoolDir=/home/hadoop/LogModel/source1
a1.sources.sc1.channels=ch1
a1.sources.sc1.fileHeader = false
#channel1
a1.channels.ch1.type=file
#a1.channels.ch1.checkpointDir=/home/hadoop/flume/tmp
a1.channels.ch1.dataDirs=/home/hadoop/flume/data_tmp
#sink1
a1.sinks.sk1.type=avro
a1.sinks.sk1.hostname=hadoop
a1.sinks.sk1.port=23004
a1.sinks.sk1.channel=ch1:#agent2
a2.sources=sc2
a2.sinks=sk2
a2.channels=ch2
#source2
a2.sources.sc2.type=spooldir
a2.sources.sc2.spoolDir=/home/hadoop/LogModel/source2
a2.sources.sc2.channels=ch2
a2.sources.sc2.fileHeader = false
#channel2
a2.channels.ch2.type=file
#a2.channels.ch2.checkpointDir=/home/hadoop/flume/tmp
a2.channels.ch2.dataDirs=/home/hadoop/flume/data_tmp
#sink2
a2.sinks.sk2.type=avro
a2.sinks.sk2.hostname=hadoop
a2.sinks.sk2.port=41414
a2.sinks.sk2.channel=ch2a3.sources=sc1 sc2
a3.channels=ch1 ch2
a3.sinks=sk1 sk2
a3.sources.sc1.type = avro
a3.sources.sc1.bind=0.0.0.0
a3.sources.sc1.port=23004
a3.sources.sc1.channels=ch1
a3.channels.ch1.type = file
a3.channels.ch1.checkpointDir=/home/hadoop/flume/checkpoint
a3.channels.ch1.dataDirs=/home/hadoop/flume/data
a3.sinks.sk1.type=hdfs
a3.sinks.sk1.channel=ch1
a3.sinks.sk1.hdfs.path=hdfs://hadoop:9000/LogModel/source
a3.sinks.sk1.hdfs.filePrefix=ent-
a3.sinks.sk2.hdfs.fileType=DataStream
a3.sinks.sk2.hdfs.writeFormat=TEXT
a3.sinks.sk1.hdfs.round=true
a3.sinks.sk1.hdfs.roundValue=5
a3.sinks.sk1.hdfs.roundUnit=minute
a3.sinks.sk1.hdfs.rollInterval=30
a3.sinks.sk1.hdfs.rollSize=0
a3.sinks.sk1.hdfs.rollCount=0
a3.sources.sc2.type = avro
a3.sources.sc2.bind=0.0.0.0
a3.sources.sc2.port=41414
a3.sources.sc2.channels=ch2
a3.channels.ch2.type = file
a3.channels.ch2.checkpointDir=/home/hadoop/flume/checkpoint2
a3.channels.ch2.dataDirs=/home/hadoop/flume/data2
a3.sinks.sk2.type=hdfs
a3.sinks.sk2.channel=ch2
a3.sinks.sk2.hdfs.path=hdfs://hadoop:9000/LogModel/source
a3.sinks.sk2.hdfs.fileType=DataStream
a3.sinks.sk2.hdfs.writeFormat=TEXT
a3.sinks.sk2.hdfs.filePrefix=ent-
a3.sinks.sk2.hdfs.round=true
a3.sinks.sk2.hdfs.roundValue=5
a3.sinks.sk2.hdfs.roundUnit=minute
a3.sinks.sk2.hdfs.rollInterval=30
a3.sinks.sk2.hdfs.rollSize=0
a3.sinks.sk2.hdfs.rollCount=0在HDFS中得到文件夹:
/LogModel/source/
五、利用java封装日志信息:
1、分析日志格式:每行以空格隔开,包含11段:日期、时间、客户端主机IP、服务器IP、服务器端口、请求、源页面、状态、浏览器和操作系统版本
2004-12-13 00:02:37 219.137.244.90 - 211.66.184.35 80 GET /news/newshtml/schoolNews/20041210171434.asp - 200 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+SV1;+MyIE2)
2004-12-13 00:00:45 172.16.96.22 - 211.66.184.35 80 GET /all.css - 304 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1)
2004-12-18 23:58:47 172.16.96.14 - 211.66.184.35 80 GET /images/index_r2_c7.jpg - 304 Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.0)
2、分析保留主要字段:
日期、时间、客户端主机IP、服务器IP、源页面、状态、浏览器版本、操作系统版本
3、分装日志对象:
public class Log {
private String date;
private String time;
private String client_IP;
private String server_IP;
private String orignHtml;
private String status;
private String Btype;
//构造函数
public Log()
{}
public Log(String log)
{
String[]logs=log.split(" ");
if(logs.length>10)
{
if(logs[0].length()>=10)
{
this.date=logs[0].substring(logs[0].length()-10);
}
this.time=logs[1];
this.client_IP=logs[2];
this.server_IP=logs[4];
this.orignHtml=logs[7];
this.status=logs[9];
this.Btype=logs[10];
}
}
//set、get函数
public String getBtype() {
return Btype;
}
public void setBtype(String btype) {
Btype = btype;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getClient_IP() {
return client_IP;
}
public void setClient_IP(String client_IP) {
this.client_IP = client_IP;
}
public String getServer_IP() {
return server_IP;
}
public void setServer_IP(String server_IP) {
this.server_IP = server_IP;
}
public String getOrignHtml() {
return orignHtml;
}
public void setOrignHtml(String orignHtml) {
this.orignHtml = orignHtml;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
}public class LogFormat {
public static class LogMap extends Mapper<Object, Text, NullWritable, Text>{
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//获取一行日志
if(!value.toString().startsWith("#")&&value.toString()!=null&&value.toString().length()>60)
{
Log log=new Log(value.toString());
//注意如何处理过滤掉不合格的数据
if(log.getDate()!=null&&log.getTime()!=null&&!log.getTime().equals("date")&&!log.getTime().equals("time")&&log.getDate().contains("-")&&log.getTime().contains(":"))
{
//构造格式化日志
String val=log.getDate()+"\t"+log.getTime()+"\t"+log.getClient_IP()+"\t"+log.getServer_IP()+"\t"+log.getOrignHtml()+"\t"+log.getStatus()+"\t"+log.getBtype();
//写出
context.write(NullWritable.get(),new Text(val));
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: LogFormat <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "LogFormat");
job.setJarByClass(LogFormat.class);
job.setMapperClass(LogMap.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
job.waitForCompletion(true);
System.out.println("Job is successful?:"+(job.isSuccessful() ? "shi": "no"));
}
}1、MySQL配置:【尤其是远程访问】
MySQL安装在slave1机子上,建立xuchao用户,赋予所有的权限:
A、修改/etc/mysql/my.cnf文件,把bind.adress=127.0.0.1改为 0.0.0.0;
B、grant all privileges on *.* to 'xuchao'@'%' identified by '123456'; FLUSH PRIVILEGES;
C、重新启动mysql服务:/etc/init.d/mysql start
2、在MySQL中建立一张表:
create table Log(date char(11),time char(9),client_IP char(15),server_IP char(15),orignHtml char(100),status char(4),Btype char(120))
sqoop export --connect jdbc:mysql://slave1:3306/Log --username xuchao --password 123456 --table Log --export-dir /output/part-r-00000
--input-fields-terminated-by '\t' --input-null-string '\\N' --input-null-non-string '\\N'
import os
import sys
from datetime import date, time, datetime, timedelta
from stat import *
def MySQLBackup():
User = 'xuchao'
Passwd = '123456'
Mysqlcommand = '/usr/bin/mysqldump'
Gzipcommand = '/bin/gzip'
Mysqldata = ['Log','Log']
Tobackup = '/home/hadoop/LogModel/mysqlBackup/'
for DB in Mysqldata:
now = datetime.now()
Backfile = Tobackup + DB + '-' + now.strftime('%H-%M-%S') + '.sql'
Gzfile = Backfile +'.gz'
if os.path.isfile(Gzfile):
print(Gzfile + " is already backup")
else:
Back_command = Mysqlcommand + '-h slave1 -u' + User + ' -p' + Passwd + ' -P3306 ' + DB + ' > ' + Backfile
if os.system(Back_command)==0:
print('Successful backup to', DB + ' to ' + Backfile)
else:
print('Backup FAILED')
Gzip_command = Gzipcommand + ' ' + Backfile
if os.system(Gzip_command)==0:
print('Successful Gzip to',Gzfile)
else:
print('Gzip FAILED')
Scp_command1='scp -r '+Tobackup+' hadoop@hadoop:~/LogModel/'
Scp_command2='scp -r '+Tobackup+' hadoop@slave2:~/LogModel/'
if os.system(Scp_command1)==0:
print('Successful backup to', DB + ' to hadoop')
else:
print('Backup To hadoop FAILED')
if os.system(Scp_command2)==0:
print('Successful backup to', DB + ' to slave2')
else:
print('Backup To slave2 FAILED')
def runTask(func, day=0, hour=0, min=0, second=0):
# Init time
now = datetime.now()
strnow = now.strftime('%Y-%m-%d %H:%M:%S')
print("now:",strnow)
# First next run time
period = timedelta(days=day, hours=hour, minutes=min, seconds=second)
next_time = now + period
strnext_time = next_time.strftime('%Y-%m-%d %H:%M:%S')
print("next run:",strnext_time)
while True:
# Get system current time
iter_now = datetime.now()
iter_now_time = iter_now.strftime('%Y-%m-%d %H:%M:%S')
if str(iter_now_time) == str(strnext_time):
# Get every start work time
print("start work: %s" % iter_now_time)
# Call task func
func()
print("task done.")
# Get next iteration time
iter_time = iter_now + period
strnext_time = iter_time.strftime('%Y-%m-%d %H:%M:%S')
print("next_iter: %s" % strnext_time)
# Continue next iteration
continue
runTask(MySQLBackup, hour=10)1、配置MySQL作为Hive的远程元数据库:
在mysql中创建一个用户:
create user 'hive' identified by '123456';
grant all privileges on *.* to 'hive'@'%' with grant option;
FLUSH PRIVILEGES; <property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://slave1:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
2、从HDFS中直接导入数据到Hive表中:
创建空表:
create table Log(dat string,tim string,client_IP string,server_IP string,status string,Btype string) row format delimited fields terminated by '\t';
load data inpath '/output/part-r-00000' overwrite into table Log;十、利用SQL进行简单的数据统计
1、查询本次收集了哪些天的数据,每天的浏览量有多少条?
select dat,count(dat) as count from log group by dat;
2004-12-13 12599
2004-12-14 1890
2004-12-15 12571
2004-12-16 2089
2004-12-17 12185
2004-12-18 2941
2004-12-19 11767
2004-12-20 2445
2004-12-21 11790
2004-12-22 2314
2004-12-23 11604
2004-12-24 1852
2004-12-25 12558
2004-12-26 1379
2004-12-27 13250
2004-12-28 1673
2004-12-29 12712
2004-12-30 1163
2004-12-31 13054
2005-01-01 1176
2005-01-02 13464
2005-01-03 908
2005-01-04 13364
2005-01-05 2082
2005-01-06 12302
2005-01-07 3335
2005-01-08 10853
2005-01-09 1260
2005-01-10 13458
2005-01-11 1624
2005-01-12 12952
2、每天访问的独立IP数量:
select dat,count(distinct(client_IP)) from Log group by dat;
2004-12-13 217
2004-12-14 41
2004-12-15 235
2004-12-16 57
2004-12-17 220
2004-12-18 72
2004-12-19 213
2004-12-20 57
2004-12-21 254
2004-12-22 57
2004-12-23 246
2004-12-24 54
2004-12-25 220
2004-12-26 45
2004-12-27 229
2004-12-28 49
2004-12-29 250
2004-12-30 40
2004-12-31 216
2005-01-01 40
2005-01-02 209
2005-01-03 36
2005-01-04 223
2005-01-05 52
2005-01-06 226
2005-01-07 70
2005-01-08 208
2005-01-09 37
2005-01-10 208
2005-01-11 38
2005-01-12 256
3、查询出现各种状态以及数据条数:
select status,count(status) from Log group by status;
200 94975
206 114
207 59
302 144
304 128762
403 39
404 4486
405 9
406 2
500 24
4、访问主要的原页面以及条数(考虑条数限制):
select orignHtml,count(orignHtml) a from Log group by orignHtml having a>500 order by a Desc;
+--------------------------------------------------------------+------+
| orignHtml | a |
+--------------------------------------------------------------+------+
| /index.asp | 6686 |
| /all.css | 6282 |
| /news/newsweb/call_news_top.asp | 6160 |
| /images/head.jpg | 5015 |
| /images/index_r2_c4.jpg | 4985 |
| /images/index_r2_c3.jpg | 4984 |
| /images/index_r2_c1.jpg | 4981 |
| /images/index_r2_c20.jpg | 4978 |
| /images/index_r2_c18.jpg | 4977 |
| /images/index_r2_c22.jpg | 4975 |
| /images/44_r3_c2.jpg | 4974 |
| /images/index_r2_c12.jpg | 4973 |
| /images/spacer.gif | 4973 |
| /images/index_r2_c14.jpg | 4970 |
| /images/index_r2_c15.jpg | 4969 |
| /images/44_r7_c2.jpg | 4969 |
| /images/index_r2_c7.jpg | 4969 |
| /images/index_r3_c1.jpg | 4968 |
| /images/index_r2_c13.jpg | 4968 |
| /images/index_r3_c6.jpg | 4966 |
| /images/44_r1_c1.jpg | 4965 |
| /images/44_r4_c2.jpg | 4962 |
| /images/44_r2_c1.jpg | 4959 |
| /images/xinwentiao.jpg | 4955 |
| /images/44_r2_c2.jpg | 4954 |
| /images/44_r6_c2.jpg | 4953 |
| /images/44_r5_c2.jpg | 4953 |
| /images/zuotiao1.jpg | 4939 |
| /images/44_r11_c1.jpg | 4927 |
| /images/44_r2_c4.jpg | 4923 |
| /images/111_r2_c3.jpg | 4878 |
| /images/111_r1_c1.jpg | 4876 |
| /images/111_r1_c2.jpg | 4876 |
| /images/login.gif | 4876 |
| /images/zoutiao.jpg | 4875 |
| /images/111_r1_c4.jpg | 4872 |
| /images/111_r3_c1.jpg | 4870 |
| /images/111_r4_c1.jpg | 4867 |
| /images/zoutiao3.jpg | 4867 |
| /news/inc/default.css | 1428 |
| /News/newstemplate/template/6.jpg | 997 |
| /News/newstemplate/template/9.jpg | 995 |
| /News/newstemplate/template/8.jpg | 995 |
| /pop/newyear.htm | 697 |
| /news/newshtml/schoolNews/7.jpg | 677 |
| /News/newstemplate/template/News/newstemplate/template/5.jpg | 647 |
| /news/newshtml/insideInform/index.asp | 622 |
| /news/newshtml/insideInform/4.jpg | 612 |
| /news/newsweb/call_notimenews.asp | 598 |
| /News/newstemplate/template/3.jpg | 589 |
| /News/newstemplate/template/2.jpg | 589 |
| /News/newstemplate/template/5.jpg | 564 |
| /news/newshtml/insideInform/7.jpg | 503 |
+--------------------------------------------------------------+------+
5、查找爬虫的记录
select date, Btype from Log where Btype like '%http://%' or '%spider%';
...................
....................
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
| 2005-01-05 | Baiduspider+(+http://www.baidu.com/search/spider.htm) |
640 rows in set
6、查找客户端IP和IP的条数---如何与全国IP表对照求出访问地址?
select client_IP,count(client_IP) from Log group by client_IP;
................
............................
| 61.235.74.120 | 5 |
| 61.235.74.184 | 3 |
| 61.235.74.24 | 41 |
| 61.235.74.49 | 40 |
| 61.235.80.177 | 99 |
| 61.240.64.75 | 1 |
| 61.241.132.196 | 4 |
| 61.241.132.228 | 3 |
| 61.48.106.24 | 1 |
| 61.50.142.28 | 86 |
| 61.51.110.148 | 39 |
| 61.51.131.179 | 22 |
| 61.51.227.171 | 1 |
| 61.55.0.92 | 1 |
| 61.55.182.254 | 1 |
+-----------------+------------------+
2234 rows in set (0.58 sec)
7、查看访问时间段分布:(没有列的时段都为0)
select count(time) from Log where time like '00%';
+-------------+
| count(time) |
+-------------+
| 136147 |
+-------------+
select count(time) from Log where time like '01%';
+-------------+
| count(time) |
+-------------+
| 47739 |
+-------------+
select count(time) from Log where time like '02%';
+-------------+
| count(time) |
+-------------+
| 12055 |
+-------------+
select count(time) from Log where time like '03%';
+-------------+
| count(time) |
+-------------+
| 4542 |
+-------------+
select count(time) from Log where time like '20%';
+-------------+
| count(time) |
+-------------+
| 7807 |
+-------------+
select count(time) from Log where time like '21%';
+-------------+
| count(time) |
+-------------+
| 4088 |
+-------------+
select count(time) from Log where time like '22%';
+-------------+
| count(time) |
+-------------+
| 4270 |
+-------------+
select count(time) from Log where time like '23%';
+-------------+
| count(time) |
+-------------+
| 11966 |
+-------------+
有兴趣的可以关注DataAnswer大数据!http://www.dataanswer.top
