Twitter Heron是Twitter公司开源的一个实时的、容错的、分布式的流数据处理系统。Heron是Apache Storm的直接继承者。它继承了Apache Storm的实时性、容错、低延迟的特性。并且它保留了Apache Storm的Topology API,使用者可以直接将Apache Storm上构建的Topology项目,直接转移到Apache Storm中运行而不需要做其他更改。它广泛应用于实时分析、连续计算、复杂事件处理和一些实时性要求的应用。相比于Apache Storm,它提供了扩展性更好,调试能力更强,性能更好,管理更容易等特性。它能够每秒钟百万级别的吞吐量和毫秒级别的延迟。目前Twitter Heron被Twitter公司广泛使用。
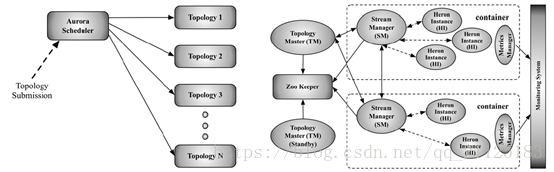
图4-xxx Twitter Heron系统架构,来自SIGMOD 15的Twitter Heron论文
Twitter Heron相比于Apache Storm,Heron有如下几个优点。首先,与storm不同Heron Instance是一个独立的jvm进程,可能是spout也可能是bolt,这样比较清晰,更容易debug,不会像storm一样很多spout、bolt在一个jvm进程内运行。其次TwitterHeron中Topology只会使用他们初始分配的资源,永远不能超过他们资源限制。TwitterHeron利用YARN进行资源调度。然后,Heron有内置的反压机制来确保拓扑在组件缓慢的情况下可以自适应。最后Heron中对系统设计进行更好的优化,使得Heron相比Apache Storm有更高的吞吐量和更低的延迟。
图4显示了Twitter Heron的整体架构。用户通过客户端将Topology提交给Twitter Heron。Topology Master管理了Topology整个生命周期,它包括对系统资源进行统一分配,将Topology中每个Instance通过封装到一个Container中去执行。Stream Manager主要是管理tuple的路由,每个HeronInstance连接到自己本地的StreamManager,每个StreamManager和它相关的StreamManager连接接收、发送tuple。与storm不同Heron Instance是一个独立的jvm进程,可能是spout也可能是bolt,这样比较清晰,更容易debug,不会像storm一样很多spout、bolt在一个jvm进程内运行。HeronInstance 有两个线程来运行,其中一个线程负责数据的输入输出和通信。还有一个线程负责运行用户逻辑代码。Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU等。并且多个HeronInstance运行在YARNContainer上,有YARNContainer进行统一管理。每个Container中运行一个Metrics Manager(MM),用于收集和导出一个container中所有组件的Metrics信息。这些Metrics信息包括系统Metrics和Topology的用户Metrics。然后这些Metrics信息可以路由给Topology Master和一些外部Metrics收集器,如Scribe等系统。
Twitter Heron使用了更加先进的设计,并且它能够方便的调试程序,它还能够兼容Apache Storm 的Topology API。相比Apache Storm,它提供更好的吞吐量和低延迟的性能。