本文提到的一些术语,比如Serializability和Linearizability,解释看Linearizability, Serializability and Strict Serializability。
本文中观点大部分都是参考了CockroachDB多篇官方blog,设计文档,代码以及相关资料,相对来说比较琐碎,而且有些地方没有交代的太清楚,这里尝试将这些资料融合起来。相信看完这篇文章,再看官方文档会更容易。
介绍
CockroachDB是一个支持SQL,支持分布式事务的ACID的分布式数据,支持ANSI SQL的最高隔离级别Serializability。
在一个分布式系统中,要支持Linearizability比较难,因为不同的机器之间时钟有误差,需要一个全局时钟。TiDB选择了和Percolator一样的方案,单点timestamp oracle提供时钟源。Google Spanner直接搞了一个基于硬件的TrueTime API提供相对来说比较精准的时钟。CockroachDB没有原子钟,也没有使用单点timestamp oracle,而是基于NTP来尽量同步机器之间的时钟偏移,NTP误差能达到250ms甚至更多,并且不能严格保证,这导致CockroachDB要保证Linearizability一致性很难,并且性能差。最终虽然CockroachDB支持Linearizability,但是官方不推荐。默认,CockroachDB支持Serializable隔离级别,但是不保证Linearizability。
Serializable
一个真实的数据库系统同一时刻会有很多并发的事务在执行,如何让这些事务觉得只有自己运行在数据库中不受其他事务的任何干扰是一个隔离级别的问题。Serializable就是不受任何干扰,弱一点的隔离级别有Repeatable Read, Read Committed, Read Uncommitted,Snapshot Isolation这些隔离级别多多少少会觉得受到了其他事务的干扰,如Repeatable Read有幻读问题,Snapshot Isolation有write skew问题,具体不赘述。可以参考a-critique-of-ansi-sql-isolation-levels
要实现一个支持Serializable隔离级别的数据库挺难的,很多数据库都不支持Serializable隔离级别,原因有几个,我觉得最重要的原因是性能不行。Oracle 11g默认隔离级别RC,最高隔离级别Snapshot Isolation,业界一些知名数据库对隔离级别的支持看When is "ACID" ACID? Rarely. 然而CockroachDB为了实现Serializable,花了大量的功夫。
一个事务通常包含多个读写操作,操作不同的行/列。数据库系统会对系统中的事务进行调度,事务会交叉执行,而不是一个接着一个。
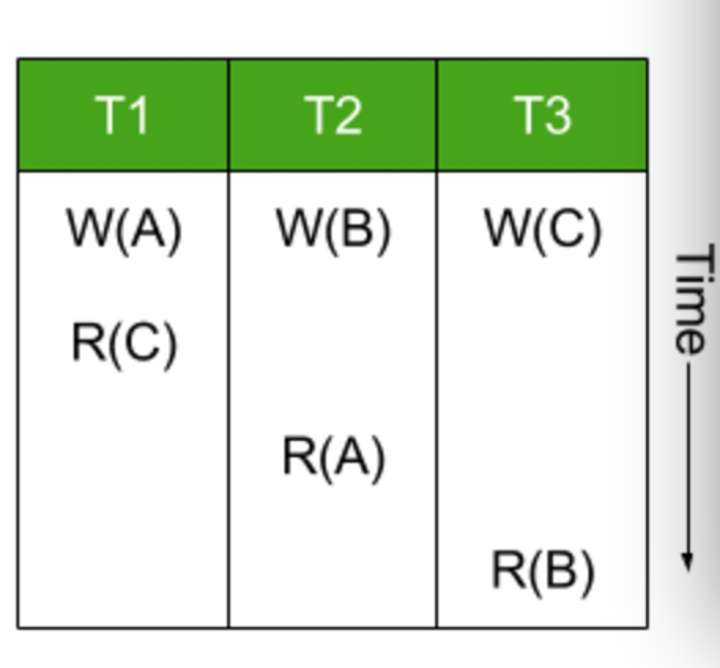
一共三个事务,上图是数据库系统对这三个事务的一种调度。那么这个调度是不是Serializable的?这个有理论支持: serializability graph。这个理论引入了三种冲突,三种冲突都是对于不同的事务操作同一个数据而言:
- RW: W覆盖了R读到的值
- WR: R读到了W更新的值
- WW: W覆盖了第一个W更新的值
对于任何一个事务调度结果,如果两个事务存在某种冲突,就在事务之间连上有向边(后面的事务指向前面的事务)。下图是上面事务调度的serializability graph:
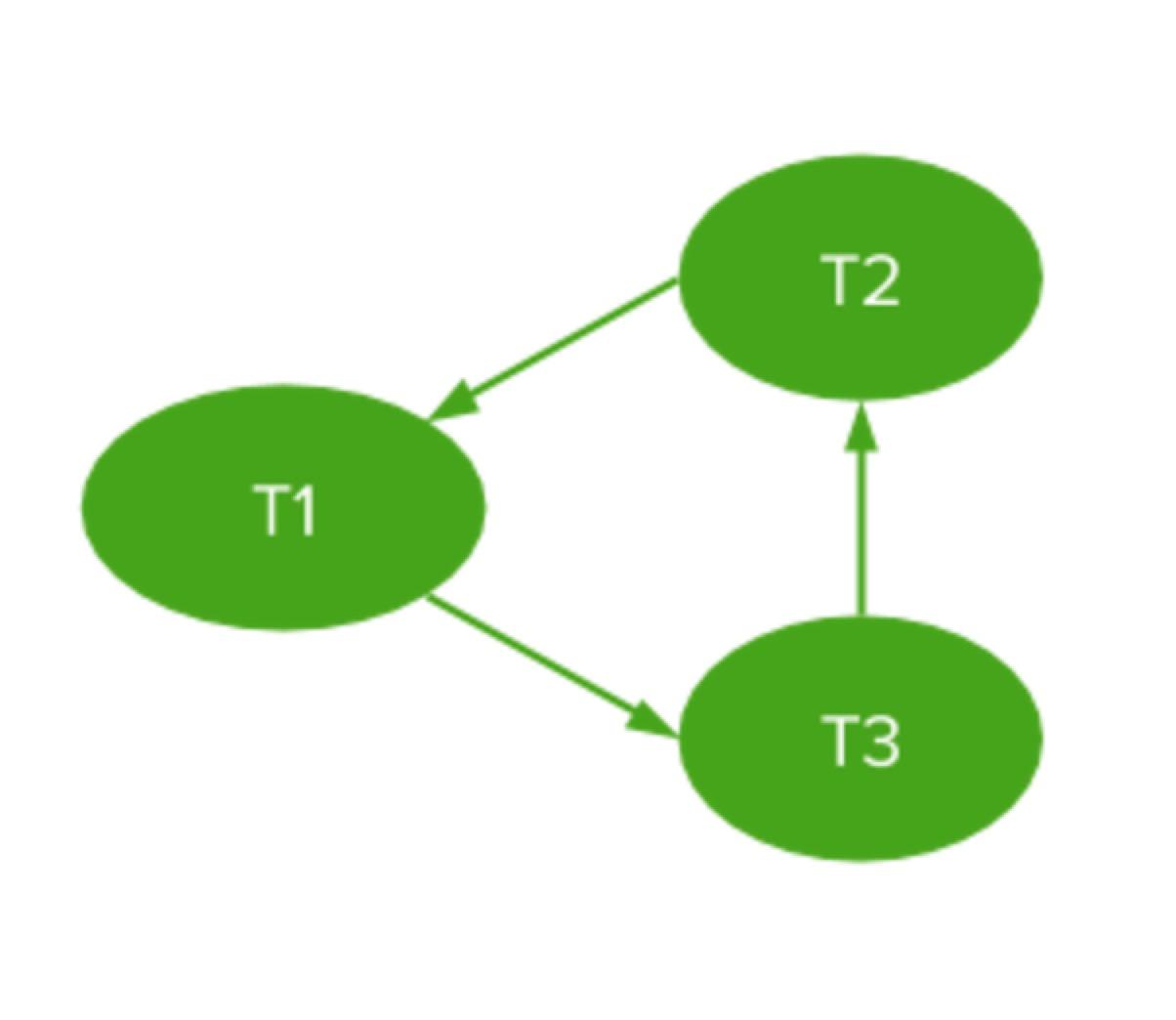
已经证明如果一个事务调度的serializability graph中不存在环,那么这个事务调度就是Serializable的。那么CockroachDB是怎么做的?
CockroachDB事务处理系统
- 多版本
CockroachDB的事务是Lock-Free的,不需要加任何读写锁,自然就需要维护数据的多个版本,版本通过timestamp来标识。
ACID中的A和I密切相关,都是通过并发控制协议保证的,下面先说明A是如何保证的,然后说明在并发的情况下,I是如何保证的。并发控制协议保证了A和I。
- 原子性
一个分布式事务可能会对多个节点上的数据进行读写,如何保证原子性? 大家都知道分布式事务都是2PC,第一阶段做Prepare,把需要的读的数据读进来(怎么保证读到最新的数据,后面会说,这里先假设能读到),计算,最后把计算后的数据写入各个节点,但是不对外生效,即系统中其他事务暂且读不到这个数据。这种已经写入各个节点,但是没有生效的数据CockroachDB把它叫做write intent,这种write intent和实际的数据存储在一起,只是外部读不到而已。
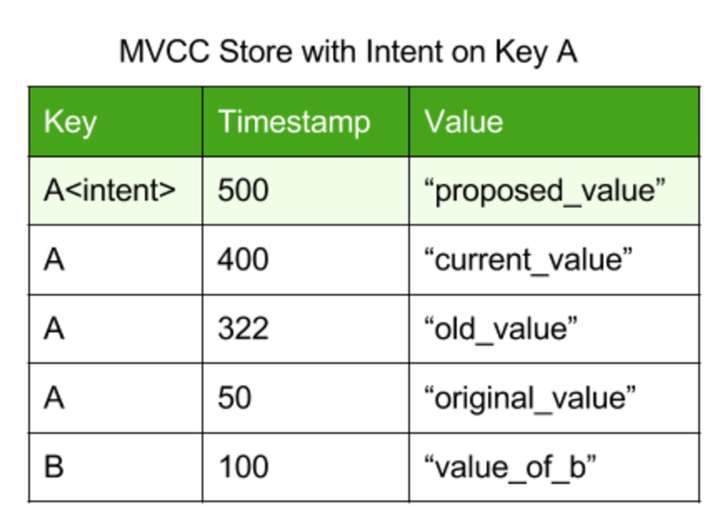
那么这个事务的状态存在哪?事实上,在一个事务开始的时候,会往底层存储系统中写入一条记录,这个记录叫做Transaction Record,record会记录事务ID,事务状态,Pending(正在运行)还是Committed,还是Aborted,而write intent里存在key指向这个Transaction Record。提交事务,只需要把Transaction Record中的事务状态改成Committed即可,回滚事务改成Aborted即可。一旦事务状态修改成功,就可以返回给客户端,遗留的write intent会异步处理:commit时,将write intent的值覆盖原始值,删掉write intent,rollback时直接删掉write intent即可。
随后客户端过来读的时候,如果碰到了write intent(之前说了,write intent是异步删除),就会沿着write intent找到Transaction Record,看看事务的状态,如果状态是committed,返回write intent中的值,如果Abort就会返回原始的值。如果是Pending,说明这个事务还在正常跑,遇到了写写冲突,如何解决写写冲突? 这个牵扯到隔离级别和并发控制协议,看下面。
- 隔离性
之前提到,数据是多版本的,版本通过timestamp来标识。timestamp是读写事务/写事务在事务开始的时候从本机拿到的wall time(实际上是HLC,一种基于物理时钟的可以捕获因果关系的逻辑时钟),这个timestamp只是这个事务最后commit的候选timestamp而已,不一定是最终的commit的timestamp(根本原因是机器之间存在时钟offset,后面会讲到),这里先假定,拿到了一个最终的timestamp。timestamp越大,说明版本越新。这个事务的所有写入的数据都会打上这个timestamp作为版本标识。在这样一个系统中,serializability graph大概是下面的样子:
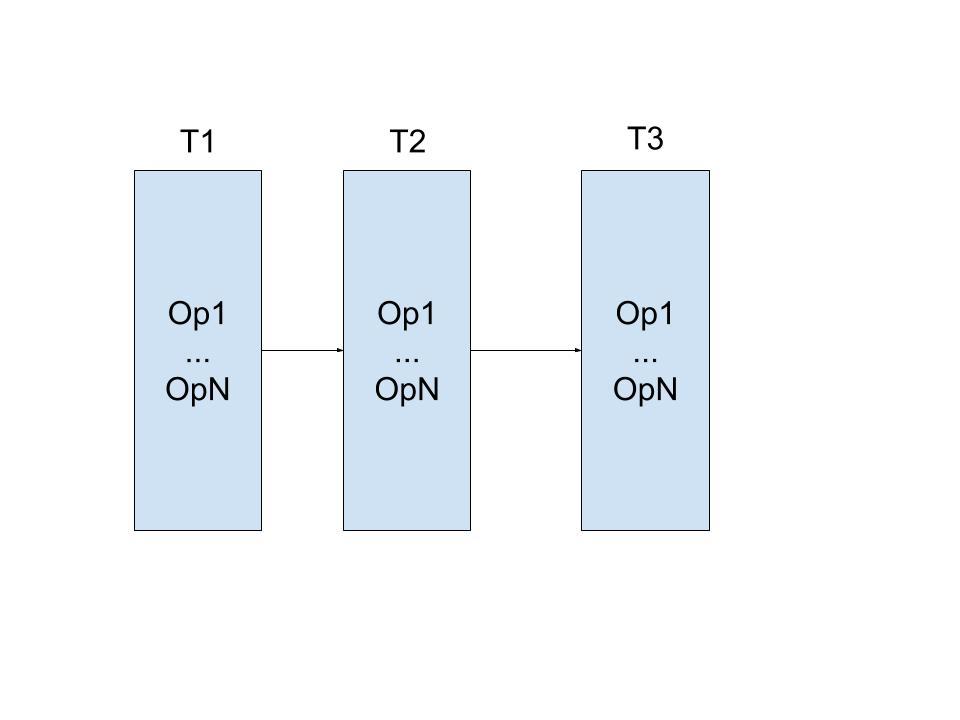
上面这个图是无环的。下面这个图是有环的:
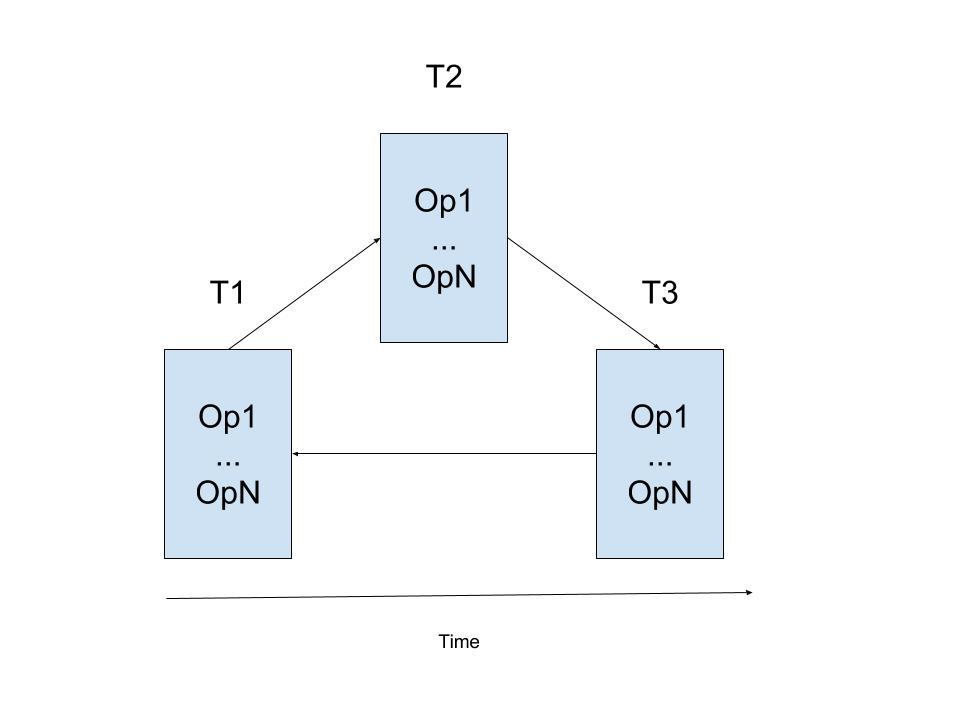
回到Serializability,为了实现Serializability,需要保证事务的调度是无环的。CockroachDB通过在timestamp的反方向避免之前提到的三种冲突,从而在图中就不会有和timestamp走向一致的边,进而保证无环。最后,CockroachDB的serializability graph长如下样子:
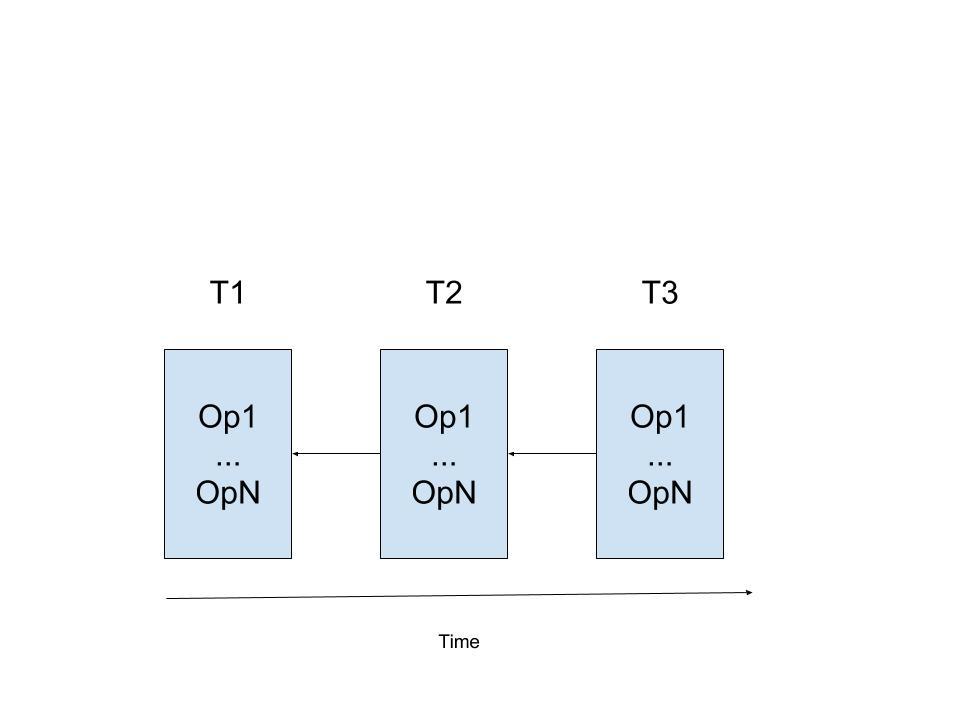
CockroachDB保证如下约束:
-
- RW: W的时间戳只能比R的大,这只会产生回头边(通过在每个节点维护一个Read Timestamp Cache)。
- WR: R只会读比自己timestamp小的最大的版本,这也只会产生回头边。
- WW:第二W的timestamp比第一个W的timestamp大,这也只会产生回头边。
也就是说,只要保证一个事务只与timestamp更小的事务冲突,就能保证无环。
- Recoverable
残酷的是,仅仅保证无环能实现Serializability,同时还需要保持数据库的一致性,即ACID中的C。考虑如下场景:
T1,T2两个事务,timestamp(T1) < timestamp(T2),T1更新A,还没有提交,T2读A。这是一个WR冲突,但是由于这个冲突是回头边,所以是允许的。为了维护上面提到的RW约束,T2必须读T1的更新(W的timestamp必须比R大,然而T1比T2小)。然而,T2读T1对A的更新有什么问题?
-
- T2读T1的更新。如果最后T2 commit,随后T1回滚,这个会违反T1的原子性:T1没有写成功的值被T2读到了。
CockroachDB使用一种比较苛刻的调度来处理这种场景:所有的操作只能在已经committed的数据上进行!下面讲讲CockroachDB的这种苛刻的调度是如何保证的,这里就需要用到前面原子性的知识。
- Strict Scheduling
从上一节以及原子性章节可以得知,一个事务碰到了一个write intent,那么说明有可能写write intent的事务还没有结束(因为write intent是异步清除的),这就说明有可能碰到了uncommitted的数据。这时,当前事务会去检查write intent所在的事务的状态,如果已经提交了,将write intent覆盖旧值然后清除write intent即可。如果已经回滚了,那么直接清除write intent就行。如果是Pending,正在运行呢?这个时候,就要看事务的优先级了,优先级低的事务需要abort,事务开始时赋予的优先级是random的。CockroachDB会保证被abort的事务在restart之后优先级会提高。
到这里,CockroachDB如何提供Serializability隔离级别就讲完了,注意,这里的前提是每个事务都被赋予了一个合适的timestamp,什么叫做合适的 timestamp? 一个分布式读/读写事务需要能读到最新的已经committed的数据。
- CockroachDB如何为事务赋予时间戳
CockroachDB使用NTP进行时钟同步,NTP基本能保证机器之间的时钟offset小于250ms,但是这也不绝对,这受到网络延时,系统load等因素的影响。从前面可以看出,CockroachDB的Serializability依赖于集群内机器之间的时钟clock在一个范围ε内。这个范围可以配置,默认250ms。任何一个时刻,在一台机器上拿到wall time为t,那么集群中可能存在的最大wall time是t+ε。
一个事务T开始时,先拿一个本地Wall time(实际上是HLC),记作t,根据NTP定义,集群内机器此刻最大的Wall time为t+ε,如果事务执行过程中读到的数据对象处于[t,t+ε]之间,我们是不知道这个值到底是在T开始之后才commit的,还是T开始之前就commit的。所以T需要restart,重新设置t为碰到的这个timestamp。
总结
总体来看,CockroachDB的并发控制协议是一个Lock-Free的,不加锁的,乐观的协议。对于数据竞争比较强的应用不太适合,需要频繁的restart事务。并且,NTP这个东西不能总是保证机器之间时钟误差在一个范围内,一旦超过这个范围,就会违反Serializability。
参考文献
Serializable, Lockless, Distributed: Isolation in CockroachDBHow CockroachDB Does Distributed, Atomic TransactionsCockroachDB beta-20160829cockroachdb/cockroachLiving Without Atomic ClocksLogical Physical Clocks and Consistent Snapshots in Globally Distributed Databases