SSD: Single Shot MultiBox Detector
intro: ECCV 2016 Oral
arxiv: http://arxiv.org/abs/1512.02325
paper: http://www.cs.unc.edu/~wliu/papers/ssd.pdf
slides: http://www.cs.unc.edu/%7Ewliu/papers/ssd_eccv2016_slide.pdf
github(Official): https://github.com/weiliu89/caffe/tree/ssd
video: http://weibo.com/p/2304447a2326da963254c963c97fb05dd3a973
github: https://github.com/zhreshold/mxnet-ssd
github: https://github.com/zhreshold/mxnet-ssd.cpp
github: https://github.com/rykov8/ssd_keras
github: https://github.com/balancap/SSD-Tensorflow
github: https://github.com/amdegroot/ssd.pytorch
github(Caffe): https://github.com/chuanqi305/MobileNet-SSD
SSD网络结构以及原理
首先使用VGG16作为base network,然后同其它的检测网络一样替换掉VGG16本身的两个全连接层,在SSD中直接改为卷积层。
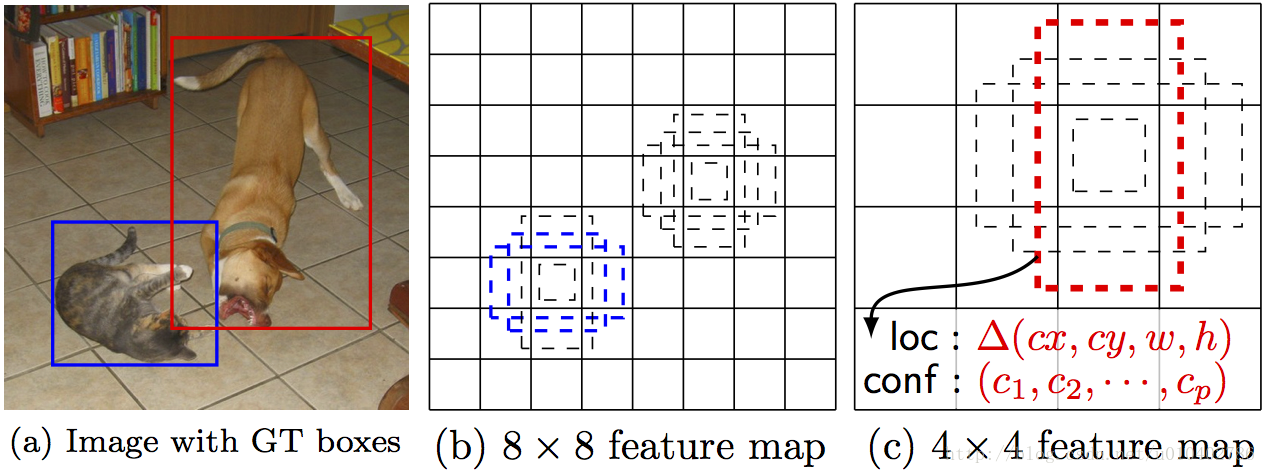
网络结构的变化,又加入了4个卷积层,SSD与yolo不同之处是除了在最终特征图上做目标检测之外,还在之前选取的5个特特征图上进行预测。SSD图1为SSD网络进行一次预测的示意图,可以看出,检测过程不仅在填加特征图(conv8_2, conv9_2, conv_10_2, pool_11)上进行,为了保证网络对小目标有很好检测效果,检测过程也在基础网络特征图(conv4_3, conv_7)上进行。
此部分贴出几个比较清楚的文章:
http://blog.csdn.net/zy1034092330/article/details/72862030
http://www.cnblogs.com/fariver/p/7347197.html
https://zhuanlan.zhihu.com/p/28867241
SSD的缺点以及相应的方案
SSD的缺点:
1. 需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中prior box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的prior box大小和形状恰好都不一样,导致调试过程非常依赖经验。
2. 虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。作者认为,这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
针对上述缺点1,参考链接: https://github.com/zhreshold/mxnet-ssd/issues/25
针对上述缺点2,参考链接:为什么SSD(Single Shot MultiBox Detector)对小目标的检测效果不好?