目录
一、目标检测概述
1.1 项目演示介绍
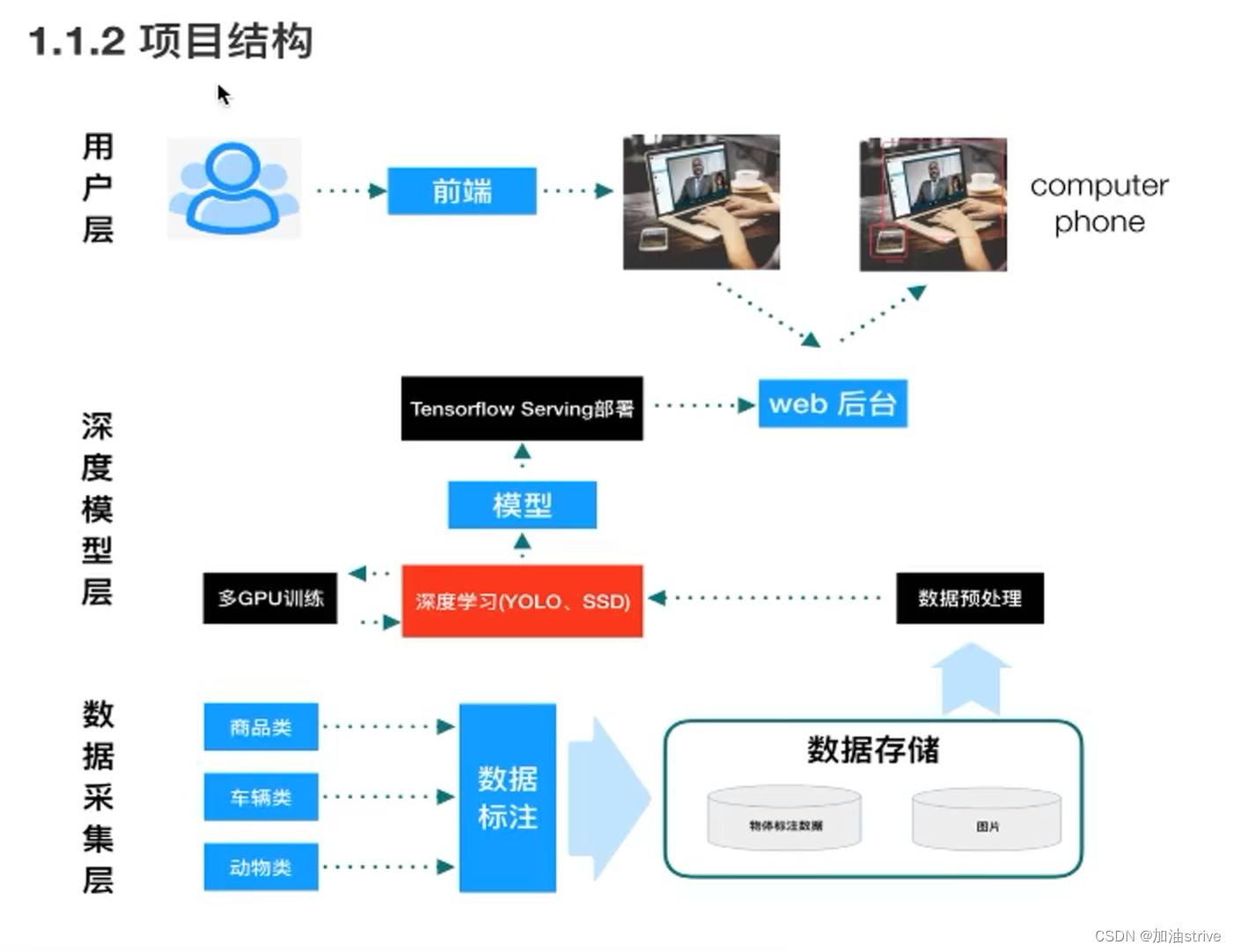
项目架构
-
数据采集层: 数据标注、数据的存储格式
-
深度模型层:数据预处理,GPU训练得到模型
- tensorflow serving 进行模型部署
- web后台
-
用户层: 网页、小程序、检测识别结果
项目安排三阶段

1.2 图片识别背景
图片识别常见示例

图像识别的三大任务:
- 目标识别: 输出类别
- 目标检测: 输出类别已经在物体在图片当中的位置
- 目标分割: 把物体形状描述出来,背景进行剔除
图像识别的发展
- 通用场景: 谷歌、阿里、百度提供的API,普及范围比较广,一般性的图像识别
- 垂直场景:
– 医疗领域:医疗影像的检测
– 林木产业:木板树种的检测
– 其他垂直领域:轮胎类型等。。。。
1.3 目标检测定义
识别图片中有哪些物体以及物体的位置(坐标位置)

位置信息的表示

极坐标表示示例

中心点坐标 表示示例

格式: x_center | y_center | box_weight | box_height
目标检测的发展历史

二、目标检测算法原理
2.1 任务描述
- 目标
–了解目标洁厕算法分类
–知道目标检测常见指标IoU
–了解目标定位的简单实现方式
2.2 目标检测算法必备基础
-
两步走的目标检测: 先进性区域推荐,而后进行目标分类
– 代表:R-CNN SPP-net Fast R-CNN Faster R-CNN -
端到端的目标检测: 采用一个网络一步到位
– 代表:YOLO SSDpass:
卷积层是深度学习中的一种基础层,最主要的功能是:
特征提取:卷积层可以通过卷积核在输入数据上进行卷积操作,从而提取出数据中的特征。这些特征可以表示数据的局部信息,如图像中的边缘、角点等。
池化层:
平均池化:计算图像区域的平均值作为该区域池化后的值。
最大池化:选图像区域的最大值作为该区域池化后的值。
主要功能:降维,特征压缩,减少网络模型计算量,可以扩大感受野
常见的模型
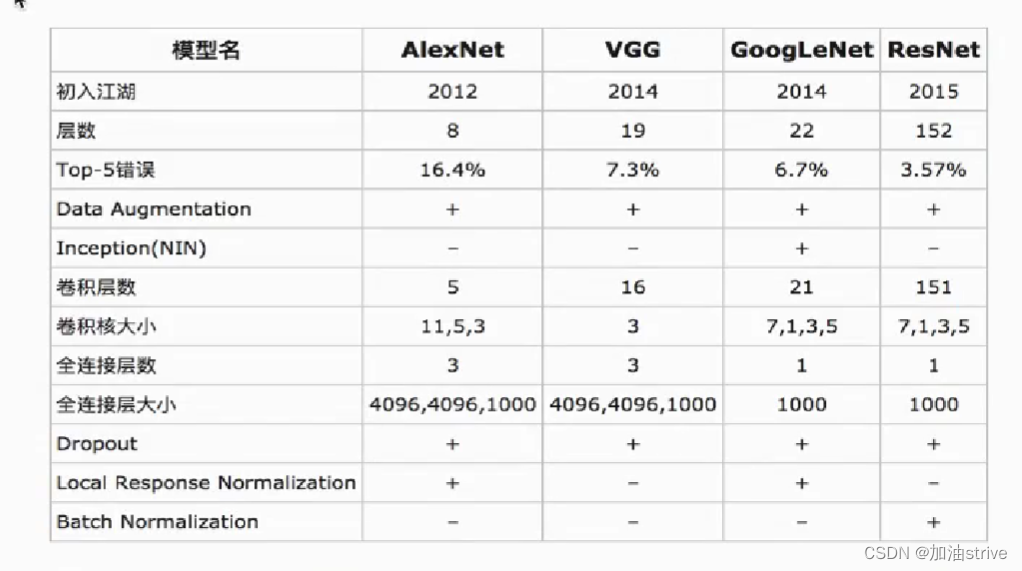
图片分类
评估指标 acc

目标检测
评估指标 IOU
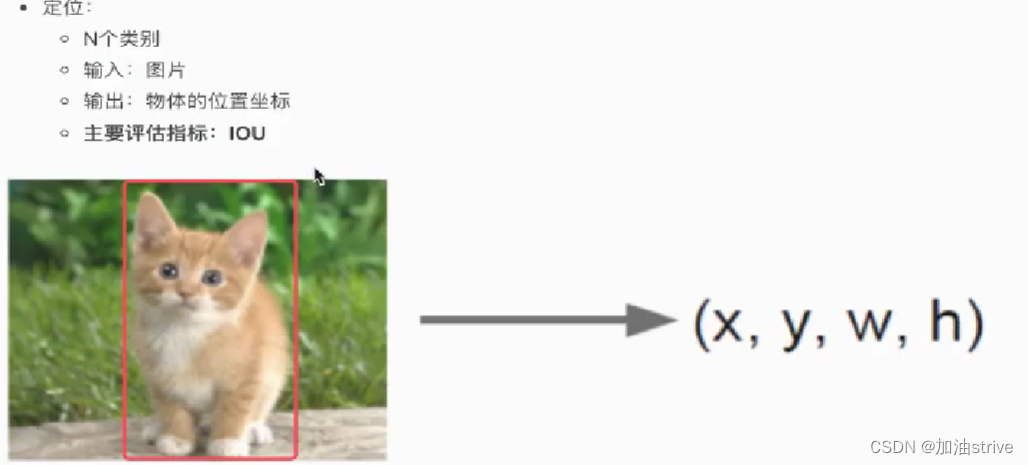
目标的位置框 :Bounding box
在目标检测中,有两种框:
- Ground-trurh bounding box:图片中真是标记的框
- Predicted bounding box: 预测的时候标记的框
IoU(交并比)的解释:
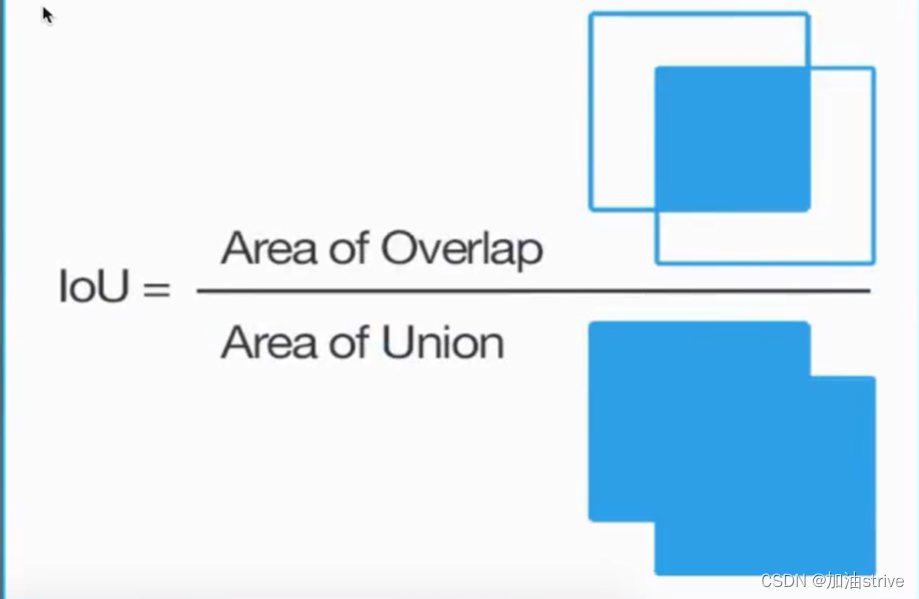
两个区域的重叠程度overlap
简述: 交集/并集
2.3目标检测算法模型输出
在原有基础上增加一个全连接层
- FC1: 作为类别的输出
- FC2:作为这个物体位置数值的输出
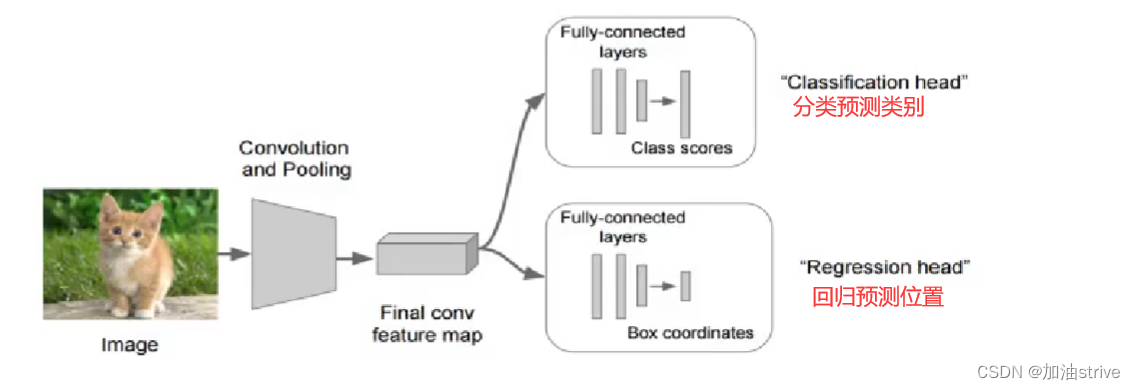
对于分类概率的评价指标,使用的是交叉熵损失 softmax
对于位置信息的回归评价指标,使用的是MSE均方误差损失 L2损失
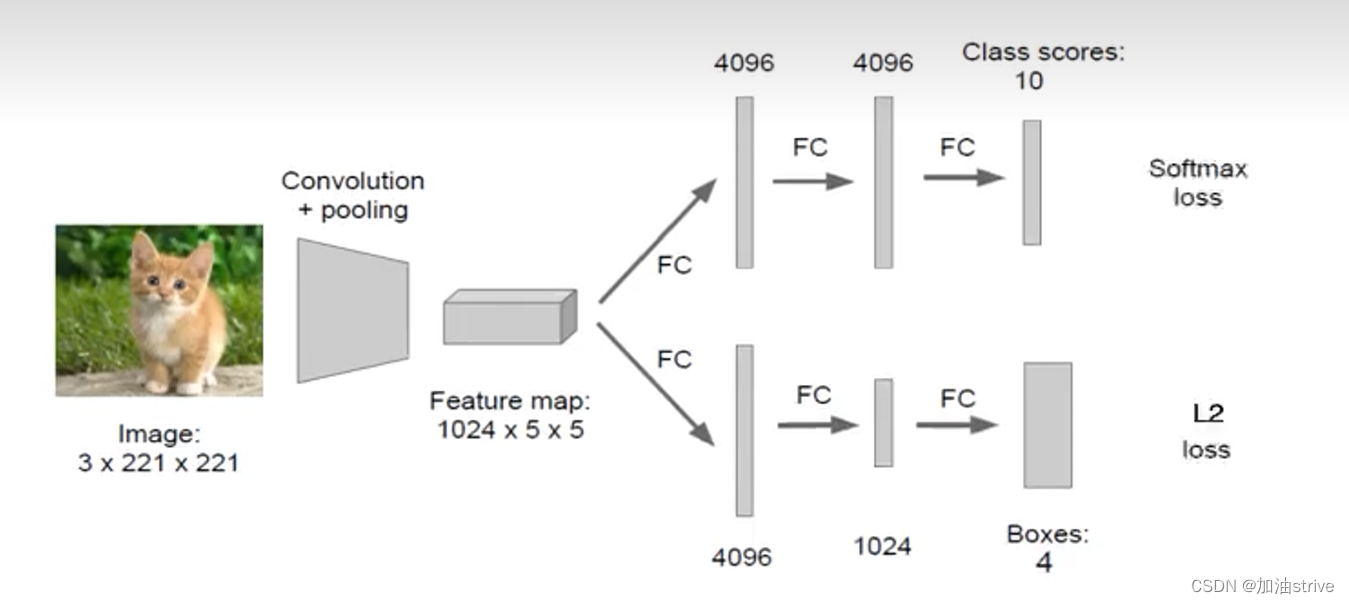

存在问题
图片中假设存在多个物体的时候,你的网络输出多少不确定,全连接层回归
输出几个坐标不确定。

目标检测 -overfeat模型
目标检测的暴力方法,是从左到右,从上到下滑动窗口,利用分类识别目标。
为了在不同观察距离处检测不同的目标类型,我们使用不同大小的宽高比的窗口。如下图所示:


模型构造大致如下: 滑动窗口大小为k
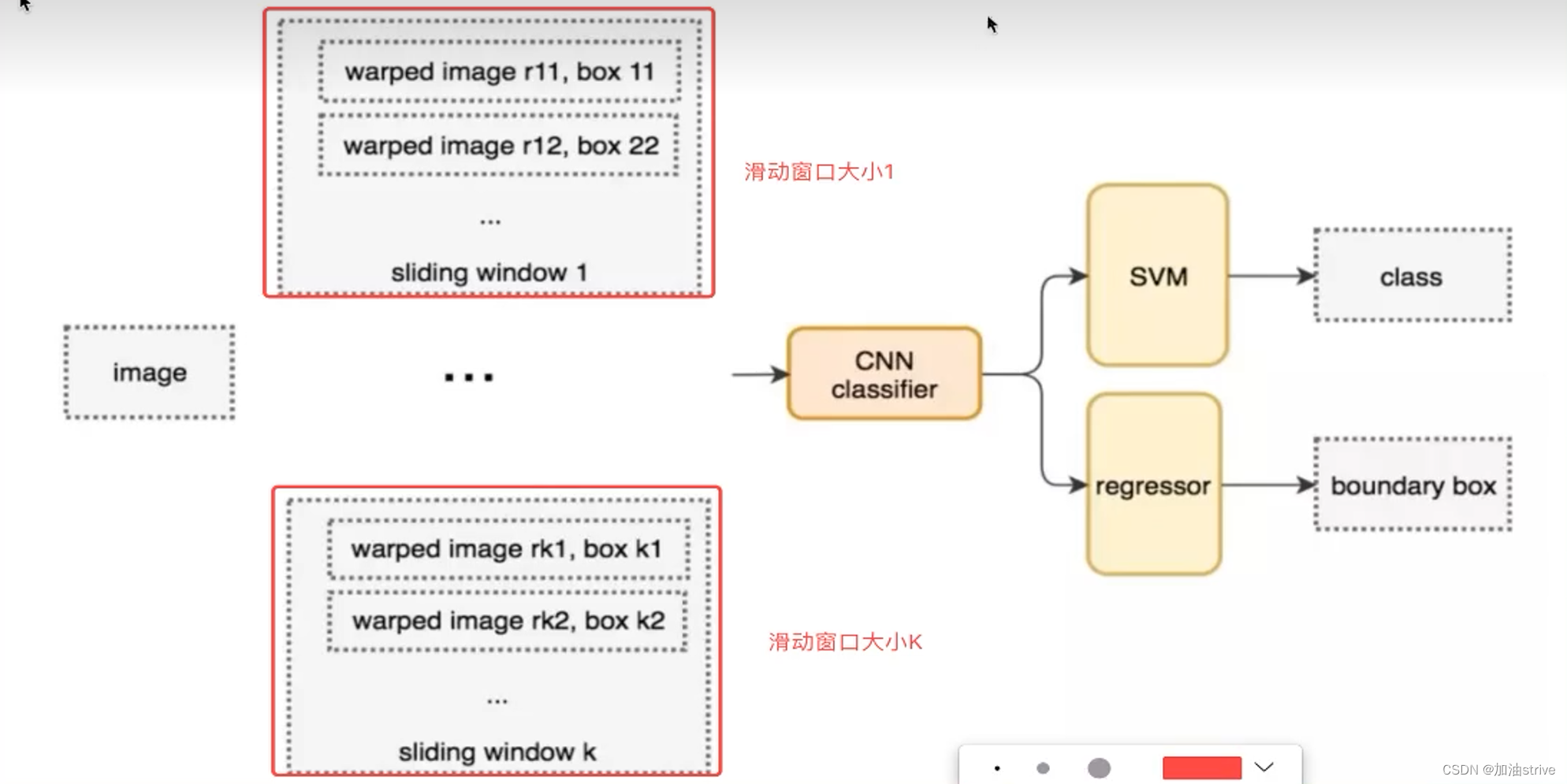
取出子图,并标记是否是数据

overfeat模型总结

R-CNN模型
完整的R-CNN的结构
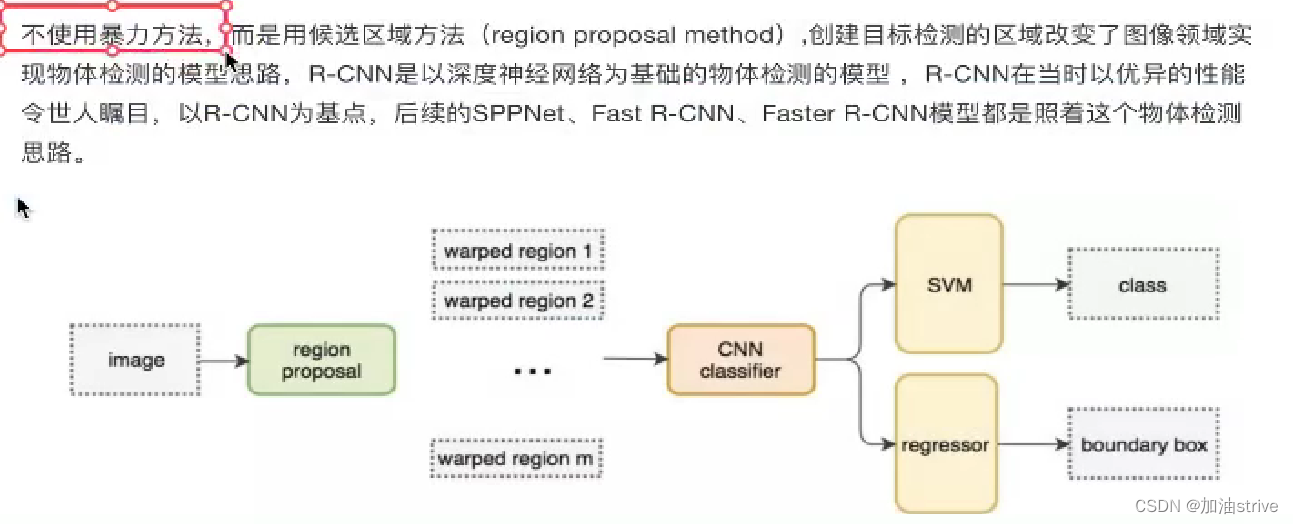
步骤

pass:
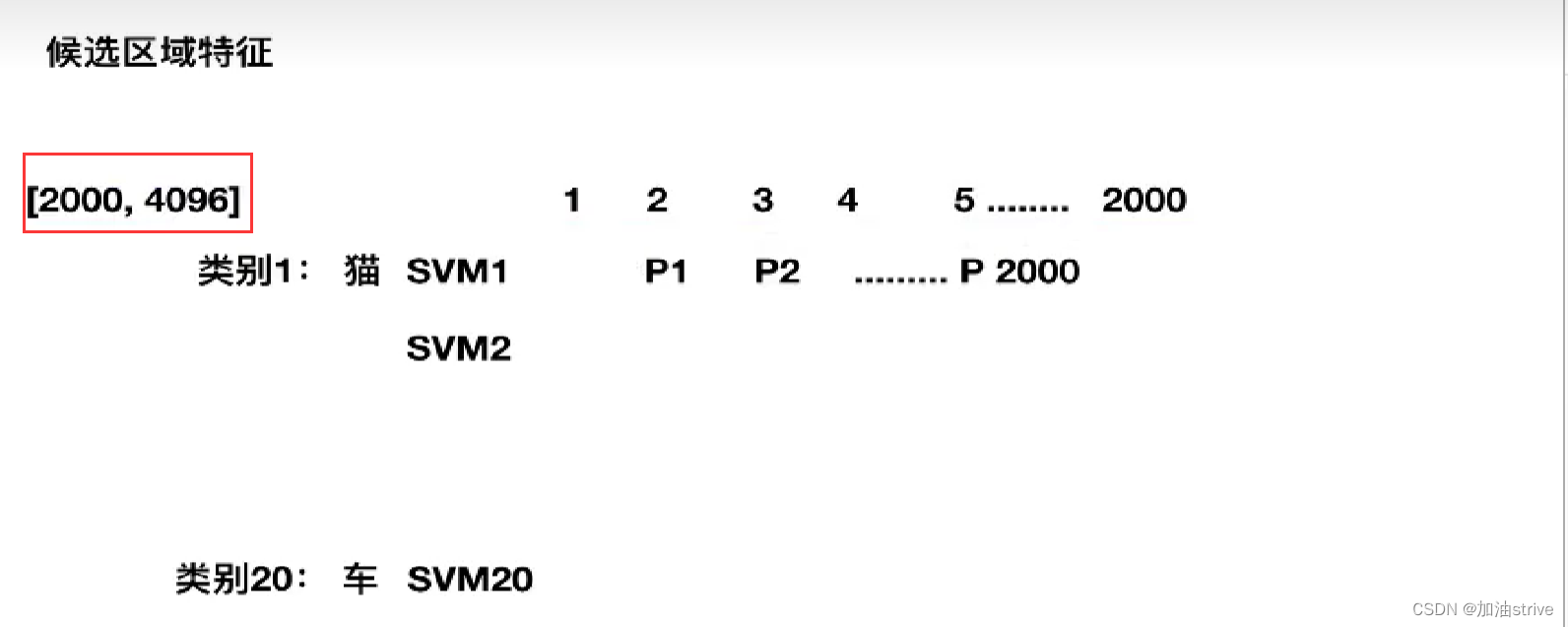
CNN提取2000×4096维的矩阵
20个SVM分类器,获得2000×20维的矩阵
NMS对每一列(列对应的类)进行非极大抑制,剔除重叠的建议框
候选区域
选择性搜索 SelectiveSearch – SS

warp比crop缩放后失真程度更小

步骤一中:
通过选择性搜索(SS)算法,进行预选框的筛选
大小统一的框使用的是 warp图片缩放的方式
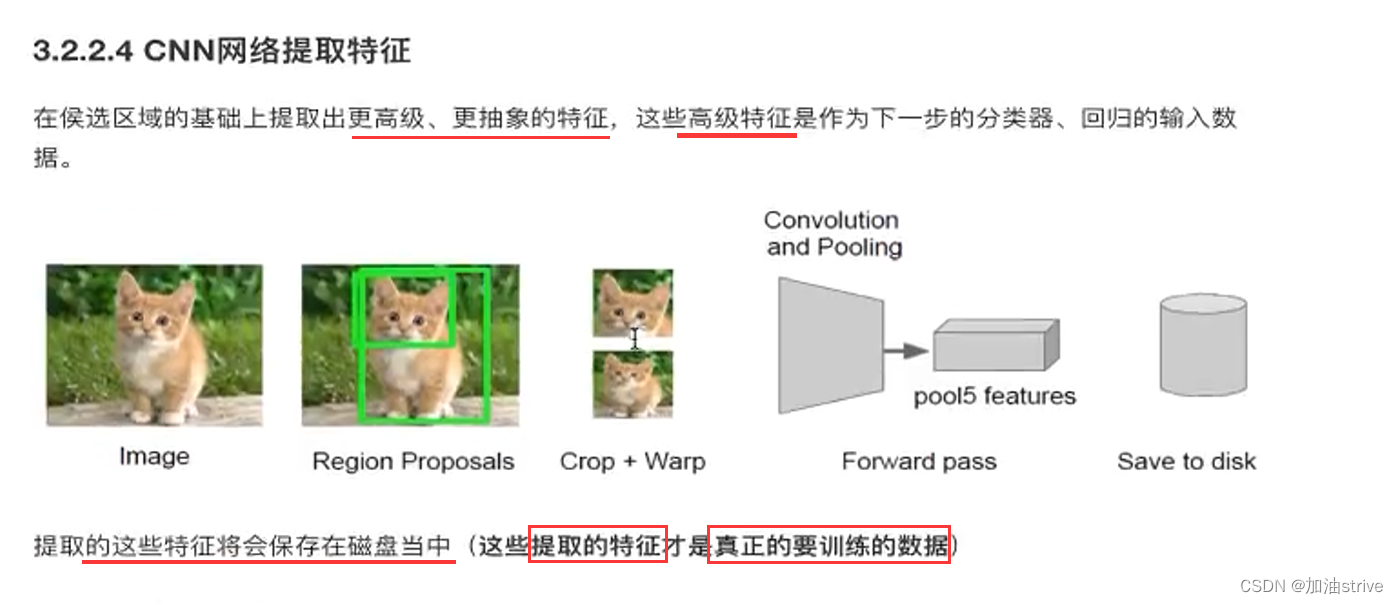
特征提取
步骤二中:
CNN提取特征,用的是AlexNet的结构,输入要求 277×277
提取的特征会保存在磁盘中
数据维度 (2000,4096) 如下图所示
20个类别是指,你训练的数据集一共就有20个类别,根据你的数据集的类别数量进行调整
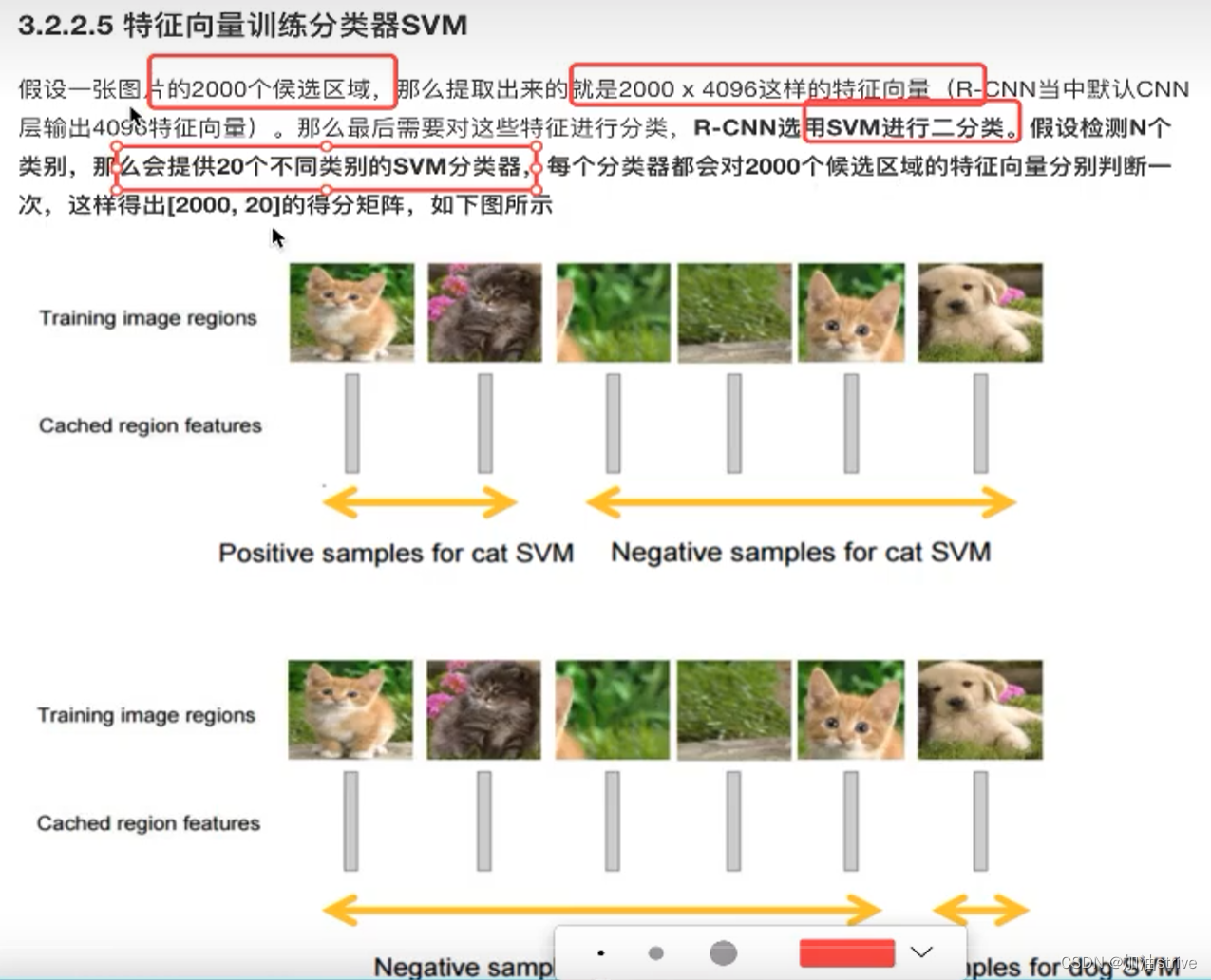
列是候选区域,行是类别特征
非极大抑制 (NMS)

非极大抑制的过程

修正候选区域

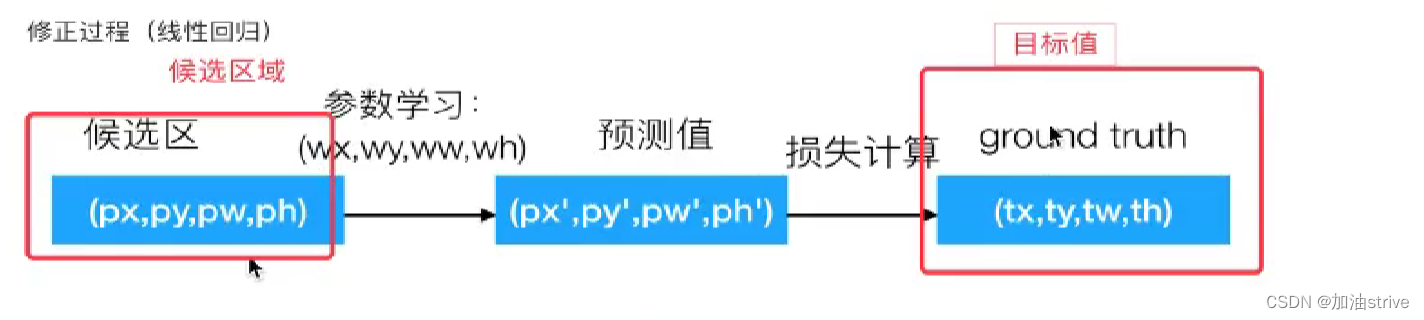
预测值是A,目标是G,进行修正后得到 G’
如下图所示:
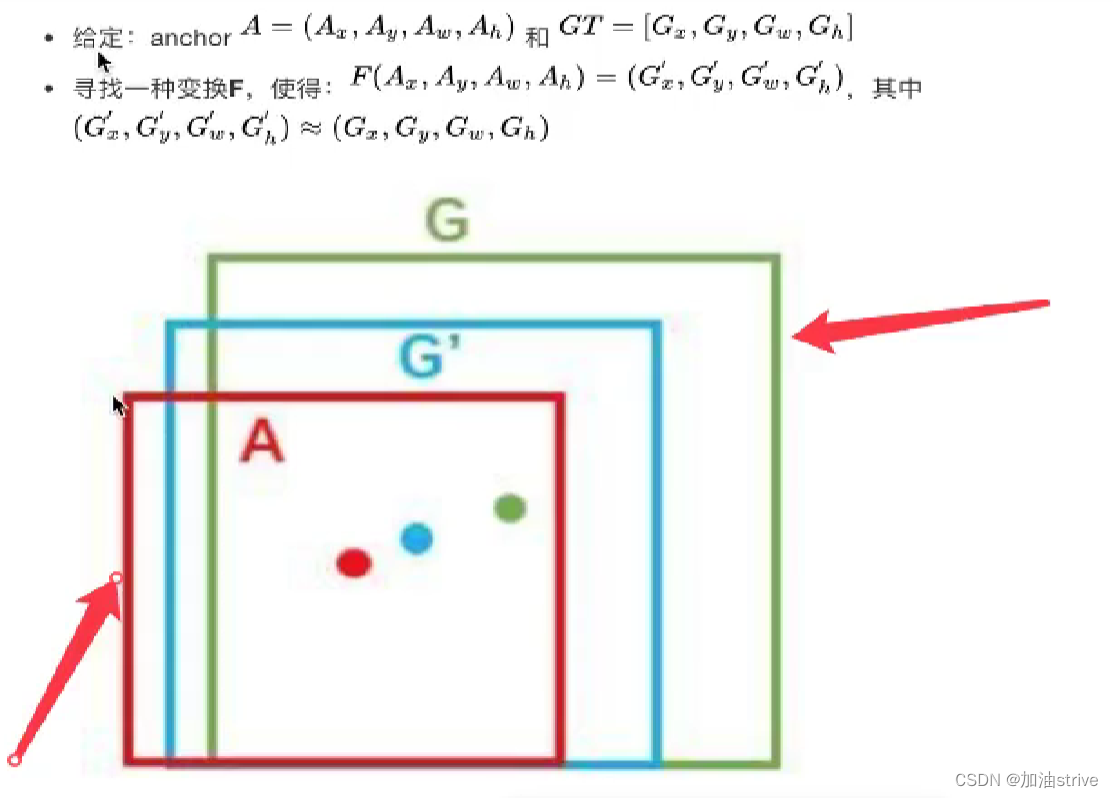

R-CNN的训练过程
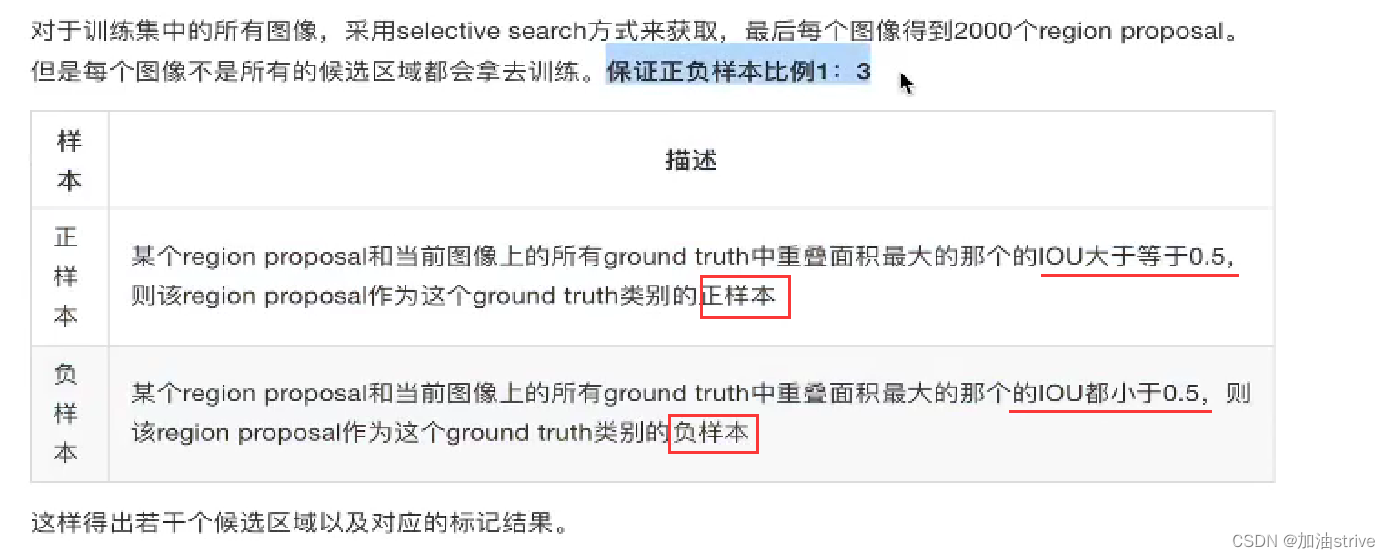
正负样本准备+预训练+微调网络+训练SVM+训练边框回归器
正负样本准备
预训练
CNN模型层数多,模型容量大,通常会采用2012年的AlexNet来学习特征,包含5个卷积层和2个全连接,比如著名的ImageNet比赛的数据集,来训练AlexNet,保存其中的模型参数
微调
类似于迁移学习

总结:
- 正负样本标记
- 预训练:别人已经在大数据集上训练好的CNN网络模型model1
- 微调: 利用标记好的样本,输入到model1当中,继续训练,得出model2

R-CNN的测试过程
- 输入一张图片,利用selective search得到2000个region proposal
- 对说有的region proposal变换得到固定尺寸,并作为预训练好的CNN网络输入,每个候选框得到4096的特征
- 对已经训练好的每个类别的svm分类器对提取到的特征打分,所以SVM的weight matrix是4096 N,N是类别数
- 采用NMS(非极大抑制)去除候选框
- 得到region proposal进行回归预测,微调
R-CNN在VOC2007数据集上平均精确度达到66%
缺点:
