【示例环境】
系统 WIN10
语言及版本 python3.6 安装好scrapy(装好python,在命令行中输入pip install scrapy)
首先,我们要创建一个scrapy项目,打开命令提示符(win+R, 输入cmd回车),cd到你要创建项目的目录下,使用scrapy startproject <project_name>命令, 该参数表示你为项目起的名:(如图所示,我将项目命名为example,你可以根据需要改名)
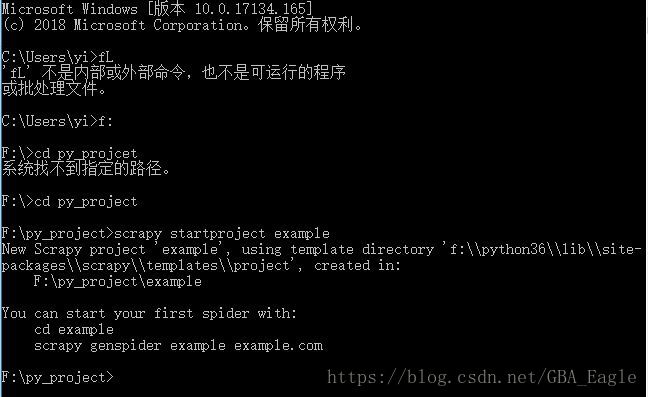
后面有如图中提示即表示创建成功(请忽略图中我的失误。。-_-学编程是一件枯燥的事,留些失误博君一笑~)。
接下来我们可以到磁盘中查看项目文件:
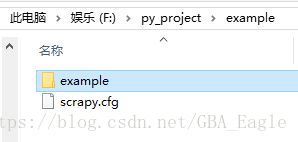


如上图组,项目已经成功创建!
接下来同样,在命令提示符中,cd到项目根目录下,我们可以使用scrapy genspider <spider_name> <domain>命令生成我们自己的Spider类,该命令的两个参数分别表示爬虫名称以及爬取的域名:
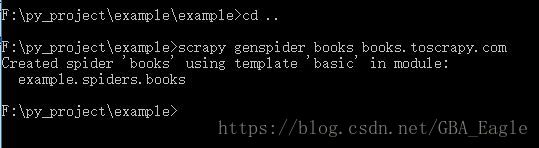
有如图提示即为创建成功
接下来我们到磁盘中去看看
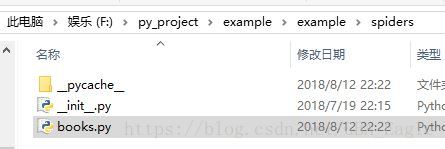
我们发现spider目录下多了一个文件books.py,即是我们刚才创建的,打开该文件看看

scrapy框架真的好用,自动帮我们生成了一个scrapy.Spider的子类BooksSpider,接下来我们只要在这个子类中实现我们要的功能就可以啦。
参考书籍:《精通Scrapy网络爬虫》,清华大学出版社,好看好用的入门书籍,推荐大家阅读~