亲身经历,非常痛苦
1.网上尝试各种办法都没成功~,很是蛋疼,最后只能死马当活马医,http://landinghub.visualstudio.com/visual-cpp-build-tools下载Visual C++ 2015 Build Tools
2.下好后,静静等静静的。。。。,直到安装完成,重启电脑,在pycharm中安装scrapy成功。。
3.这时如何创建一个scrapy的项目呢?
第一步:在随意一个文件上创建一个文件夹,在该位置打开cmd,输入
scrapy startproject 文件名
(如果windows上没有安装scrapy是不能执行成功的,windows安装教程:点击打开链接)
第二步:在pycharm中打开项目,就ok了
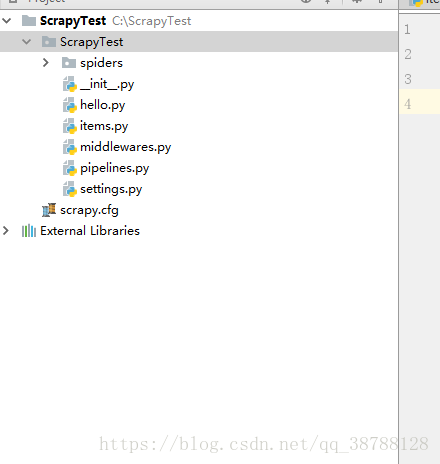
解析scrapy框架结构:
scrapy.cfg: 项目的配置文件。tutorial/: 该项目的python模块。之后您将在此加入代码。tutorial/items.py: 项目中的item文件。tutorial/pipelines.py: 项目中的pipelines文件。tutorial/settings.py: 项目的设置文件。tutorial/spiders/: 放置spider代码的目录。
加一段项目说明 转:https://zhuanlan.zhihu.com/p/26832971
Scrapy框架的基本介绍:
首先,我们得明白一点,Scrapy不是一个功能函数库,而是一个爬虫框架,简单的说,他是一个半成品,可以帮助用户简单快速的部署一个专业的网络爬虫。如果说前面我们写的定制bs4爬虫是”手动挡“,那Scrapy就相当于”半自动档“的车。
Scrapy框架结构:
首先来一张框架整体的图:
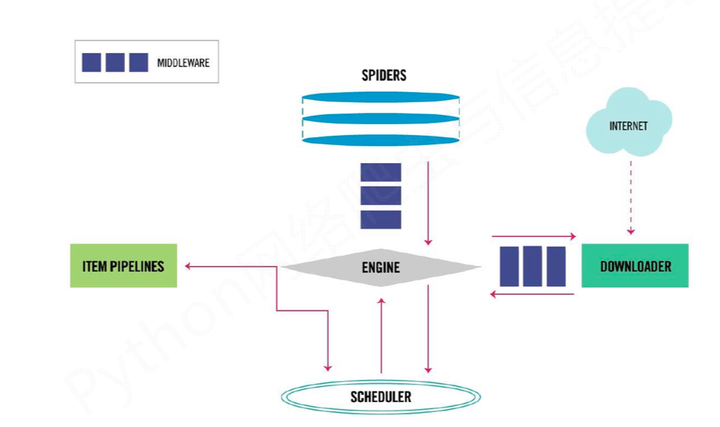
从图中我们可以清楚的看到,整个框架一共分为五个部分:
- SPIDERS
- ITEM PIPELINES
- DOWNLOADER
- SCHEDULER
- ENGIINE
这五个部分互相协作,共同完成了整个爬虫项目的工作。下面我们来一个一个介绍。
- SPIDERS:
Spiders这个模块就是整个爬虫项目中需要我们手动实现的核心部分,就是类似我们之前写的get_content函数部分,最主要的功能是 解析网页内容、产生爬取项、产生额外的爬去请求。
ITEM PIPELINES:
这个模块也是需要我们手动实现的,他的主要功能是将我们爬取筛选完毕的数据写入文本,数据库等等。总之就是一个“本地化”的过程。
DOWNLOADER:
这个模块,是Scrapy帮我们做好的,不需要我们自己编写,直接拿来用就行,其主要功能就是从网上获取网页内容,类似于我们写的get_html函数,当然,比我们自己写的这个简单的函数要强大很多
SCHEDULER:
这个模块对所有的爬取请求,进行调度管理,同样也是不需要我们写的模块。通过简单的配置就能达到更加多线程,并发处理等等强大功能。
ENGIINE
这个模块相当于整个框架的控制中心,他控制着所有模块的数据流交换,并根据不同的条件出发相对应的事件,同样,这个模块也是不需要我们编写的。
Scrapy框架的数据流动:
先上一张图:
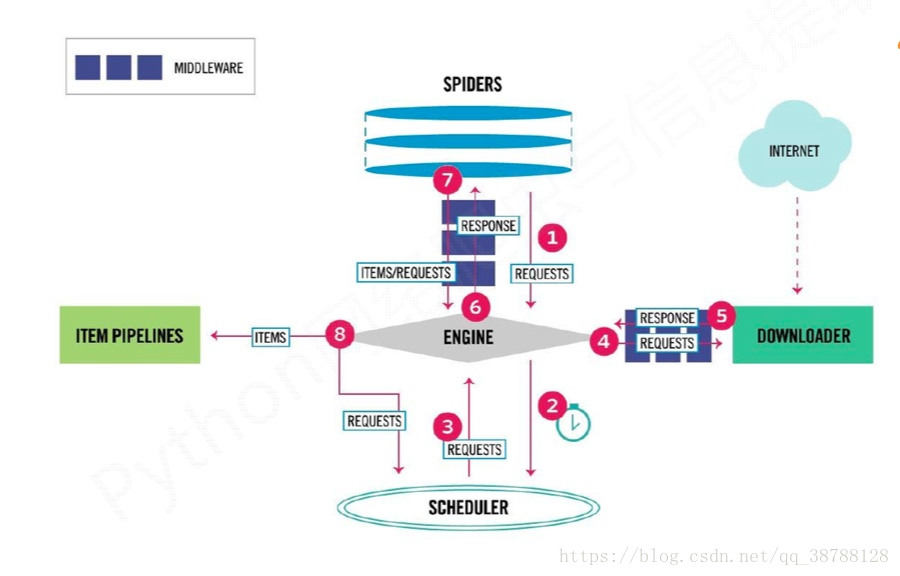
说了各个模块的作用,那么整个项目跑起来的时候,数据到底是怎么运作的呢?让我来详细说明:
- Engine从Spider处获得爬取请求(request)
- Engine将爬取请求转发给Scheduler,调度指挥进行下一步
- Engine从Scheduler出获得下一个要爬取的请求
- Engine将爬取请求通过中间件发给Downloader
- 爬取网页后后,downloader返回一个Response给engine
- Engine将受到的Response返回给spider处理
- Spider处理响应后,产生爬取项和新的请求给engine
- Engine将爬取项发送给ITEM PIPELINE(写出数据)
- Engine将会爬取请求再次发给Scheduler进行调度(下一个周期的爬取)