Scrapy介绍
总共有五部分组成的:具体的流程可看图示
引擎、调度器、下载器、蜘蛛和项目管道
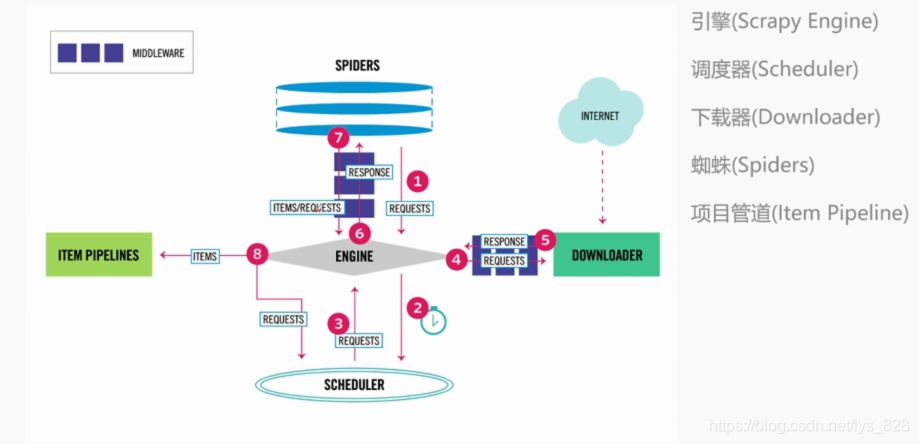
爬取流程
针对于每个URL,
Scheduler -> Downloader -> Spider ->
① 如果返回的是新的URL,就会返回Scheduler
② 如果是需要保存的数据,则会被放到item pipeline里面
Scrapy安装
在命令行窗口下执行下面语句
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
已经安装成功
Scrapy入门
创建项目
进入要储存代码的目录(命令行窗口下)
然后输入scrapy startproject tutorial
查看目录结构
在指定目录下(C:\Users\86177\tutorial)创建了一个文件夹,查看一下文件目录的结构,可以看到该文件夹下一共两个文件(一个是tutorial文件夹,一个是scrapy.cfg配置文件),该文件夹的具体文件如下

scrapy.cfg配置文件是将我们的项目发布到网上去时要进行的设置内容,一般情况下是使用不到的,我们大多情况下接触到的还是tutorial下的文件
spiders文件夹是刚刚命令行窗口下的第二个选项对应的文件存储路径,也就是在运行’scrapy genspider example examplam.com’时,会在spiders文件夹里面创建一个爬虫模板
–init–.py文件是一个声明文件,说明当前创建的这个文件夹是一个包(关于Python的包、库、模块,这里不进行介绍,可自行了解)
items.py文件是要存储要爬取的东西
middlewares.py文件是在下载完东西后需要通过的一个过程(中转站)
pipelines.py文件就是items下载完毕之后的通道
settings.py文件使用来写scrapy项目的配置
第一个Scrapy爬虫
名言网站,界面如下

步骤一、创建一个蜘蛛
在项目根目录运行如下代码
scrapy genspider quotes quotes.toscrape.com
回车确定后输出如下内容
这时候就会在spider文件夹里自动生成如下文件
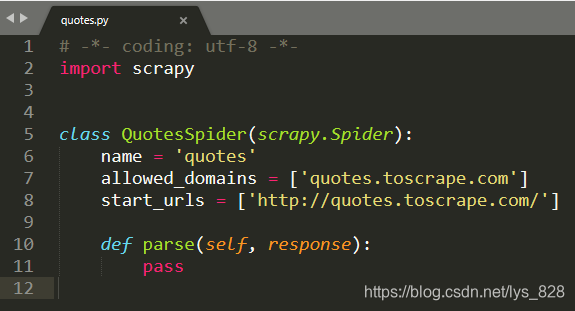
其中name 就对应命令行窗口创建时候网站前面的那个单词的名称,start_urls里面就是要爬取的网站(网址),allowed_domains要求是在主域名下进行爬取信息
步骤二、对创建的文件进行操作
比如这里对前两页的信息进行爬取
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/']
def parse(self, response):
page = response.url.split("/")[-2]
file_name = "quote-{}.html".format(page)
with open(file_name, "wb") as f:
f.write(response.body)
self.log("Saved file {}".format(file_name))
步骤三、开始运行Scrapy
一定是要在根目录下面输入如下代码(在上面的示例中就是tutorials/),否则系统就会报错
scrapy crawl quotes
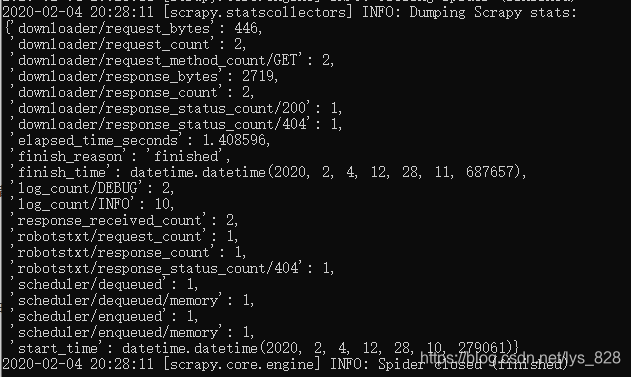
试着运行一下,运行之前记得保存一下qutoes.py文件,也就是刚刚编辑代码的那个窗口文件(如果有错误一般会在中间进行提示,会有各种Error提醒),没有错误时就顺利完成创建
这时候本地就会多出来两个文件夹,里面就包含了我们要爬取网站的源代码(也就是在start_urls包含的网址),如下
其中的quote-1.html的开头源代码如下
步骤四、代码分析
列表倒数元素的获取方法
page = response.url.split("/")[-2]
列表中的负数表示倒数,比如下面的列子
s = 'hello world!'
print(s[-2])
–> 输出结果为:d
所以对于有规律的网站(网址)要提取里面的信息就很简单
s = 'http://quotes.toscrape.com/page/1/'
print(s.split('/')[-2])
–> 输出结果为:1
因此可以使用这种方式获取页码page
Python中的文件存储
with open(file_name, "wb") as f:
f.write(response.body)
使用的方式就如下:
with open(文件名, "wb") as f:
f.write(文件内容)
举个栗子:
with open('hello.txt', "w") as f:
f.write('hello world!')
–> 输出结果为:

或者使用如下:注意和上面的区别
with open('hello.txt', "wb") as f:
f.write('hello world!'.encode())
–> 输出结果为:和上方的输出是一样的
注意事项
不同的spider的name不能相同(容易理解,因为创建的时候会在spider文件夹里创建文件,一山不容二虎),里面的函数名称不能自己随意命名
步骤五、提取数据方法
打开cmd窗口,切换到下载文件的目录里面(这里推荐使用powershell,在目标文件所在目录空白位置同时按住shift和鼠标右键就可以打开,这样不用再切换路径了,powershell和cmd的区别),输入
scrapy shell 'http://quotes.toscrape.com/page/2/'
就会进入交互模式,如下
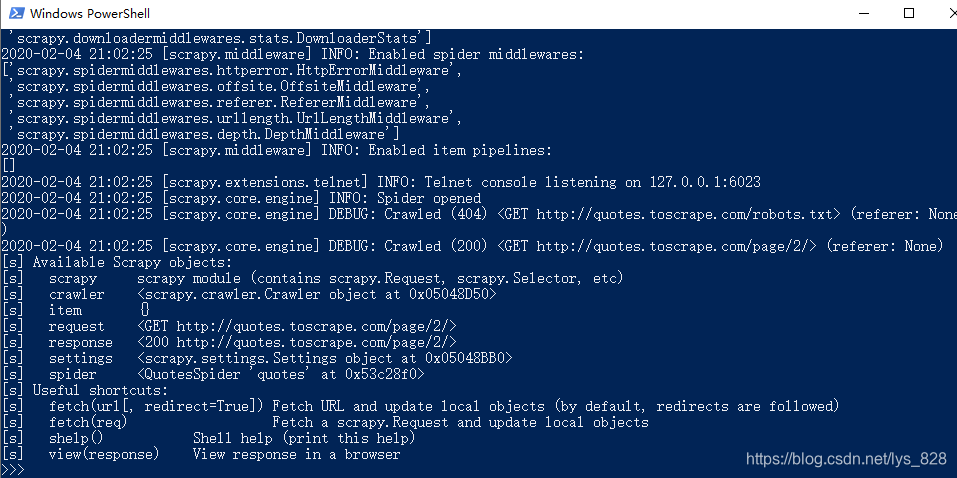
比如我们想获取网页里面的title,就可以使用CSS选择器,通过response.css(‘title’),进行输出,如果要输出标签信息的话,后哦面还需要加上.extract()方法,返回的是一个列表

获取标签里面的内容,注意不是和原来一样将.text放在最后面,而是在中间了

Scrapy也支持xpath进行文本提取(关于xpath会在爬虫专项里面进行讲解),代码执行结果如下

步骤六、分析网页,明确目标
打来目标页面,进行检查,找到对应的标签信息

步骤七、实战解析
这时候已经确定标签对应目标信息的位置,接下来打开quotes.py文件,进行代码编写
首先 获取该页面的全部的正文内容(就是quote,里面的名言)
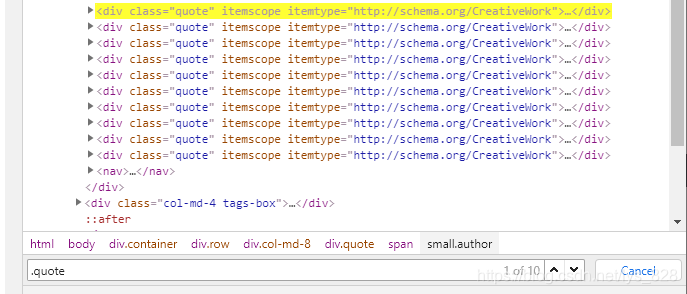
quotes = response.css(".quote")
–> 输出结果,可以看出一个页面是有10条数据,如下
其次 再获取每一个正文里面的文本内容、作者和对应的标签
for quote in quotes:
title = quote.css('.text::text').extract()[0]
author = quote.css('.author::text').extract()[0]
tags = quote.css('.tag::text').extract()
print('title:\n',title)
print('author:\n',author)
print('tags:\n',tags)
然后 保存文件,quotes.py文件里面最终的代码如下
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/']
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
title = quote.css('.text::text').extract()[0]
author = quote.css('.author::text').extract()[0]
tags = quote.css('.tag::text').extract()
print('title:\n',title)
print('author:\n',author)
print('tags:\n',tags)
最后 打开命令行窗口(powershell或者cmd),在根目录下也就时tutarial文件夹路径,运行scrapy项目,输入之前的命令代码,如下
scrapy crawl quotes
在命令行下面输入指令
–> 输出结果:(在全部输出内容的中间部分,和报错产生的位置是一样的)
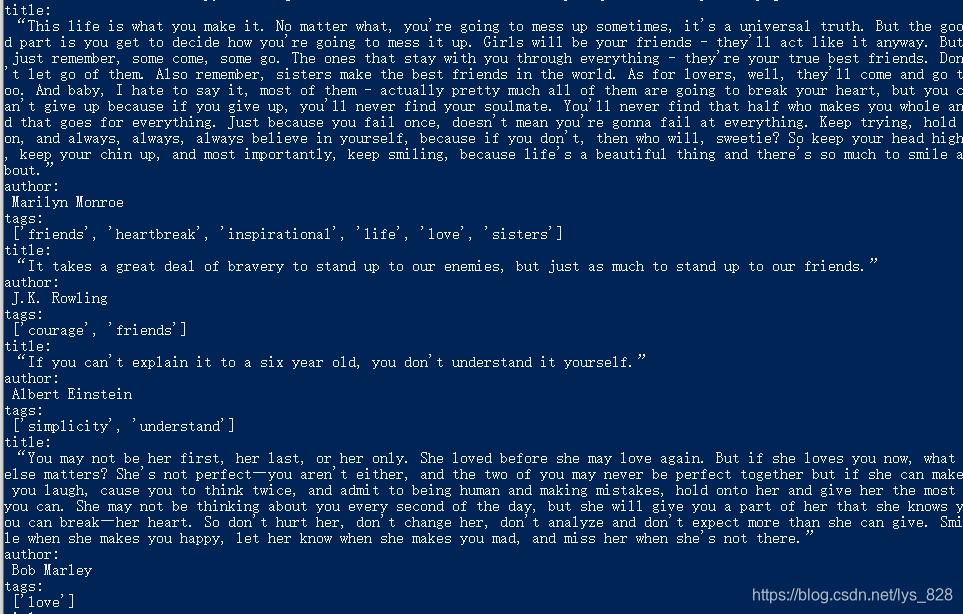
最后的最后 把获取的数据存储到本地
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/']
def parse(self, response):
page = response.url.split("/")[-2]
file_name = "quotes-{}.txt".format(page)
with open(file_name,'w') as f:
quotes = response.css(".quote")
for quote in quotes:
title = quote.css('.text::text').extract()[0]
author = quote.css('.author::text').extract()[0]
tags = quote.css('.tag::text').extract()
print('title:\n',title)
print('author:\n',author)
print('tags:\n',tags)
f.write('title:{}\n author:{}\n tags:{}\n'.format(title,author,tags))
保存一下,然后在命令行窗口下运行指令scrapy crawl quotes,最后在根目录下会生成两个.txt文件,如下
quote1.txt里面的内容就对应着网站第一页的内容,如下

至此,第一个Scrapy项目完结了
实践
【python实现网络爬虫(3)】中使用了requests和beautiful爬取了笑话大全网址,那么尝试一下用scrapy爬取一下笑话大全的网址试一下
