一、需要的工具
需要的工具我已经完成分享,需要的可以直接在网盘中下载。
VMware15 Workstation Pro 提取码:pp12
ubuntu16 18 19 镜像 提取码:yfj0
Xshell+Xftp 提取码:6ao9
jdk1.8 提取码:rzpy
hadoop 提取码:5hpm
二、搭建单机伪分布式集群
-
说明: 搭建完全分布式集群的时候我们可以先从伪分布式集群搭建起,后面从机的java hadoop环境我们可以直接从主机上复制即可,不需要两台从机都要重新配置环境,所以我们从伪分布式集群搭建开始。搭建伪分布式集群可以参考我前面的博客
阿里云服务器搭建hadoop2.7伪分布式环境
不过前面搭建的是基于阿里云centos7.6环境搭建的,其实大致上差不多,但是为了完整性,决定演示一下ubuntu虚拟机上的完整搭建步骤。 -
修改主机名字为master
然后重启主机生效 :sudo reboot -
修改host文件
vim /etc/hostname
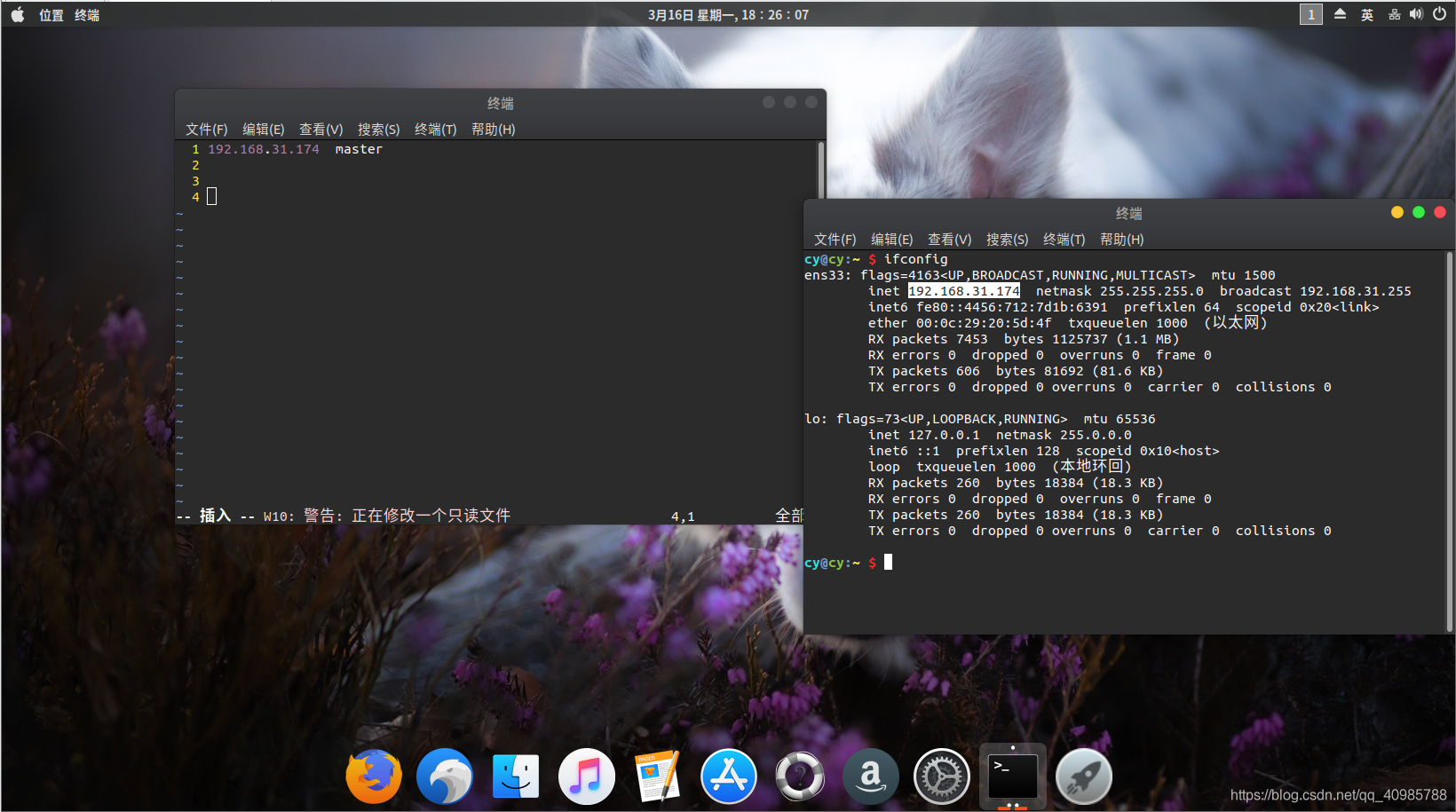
- 安装SSH
sudo apt-get install openssh-server
测试ssh是否安装成功。
ssh master
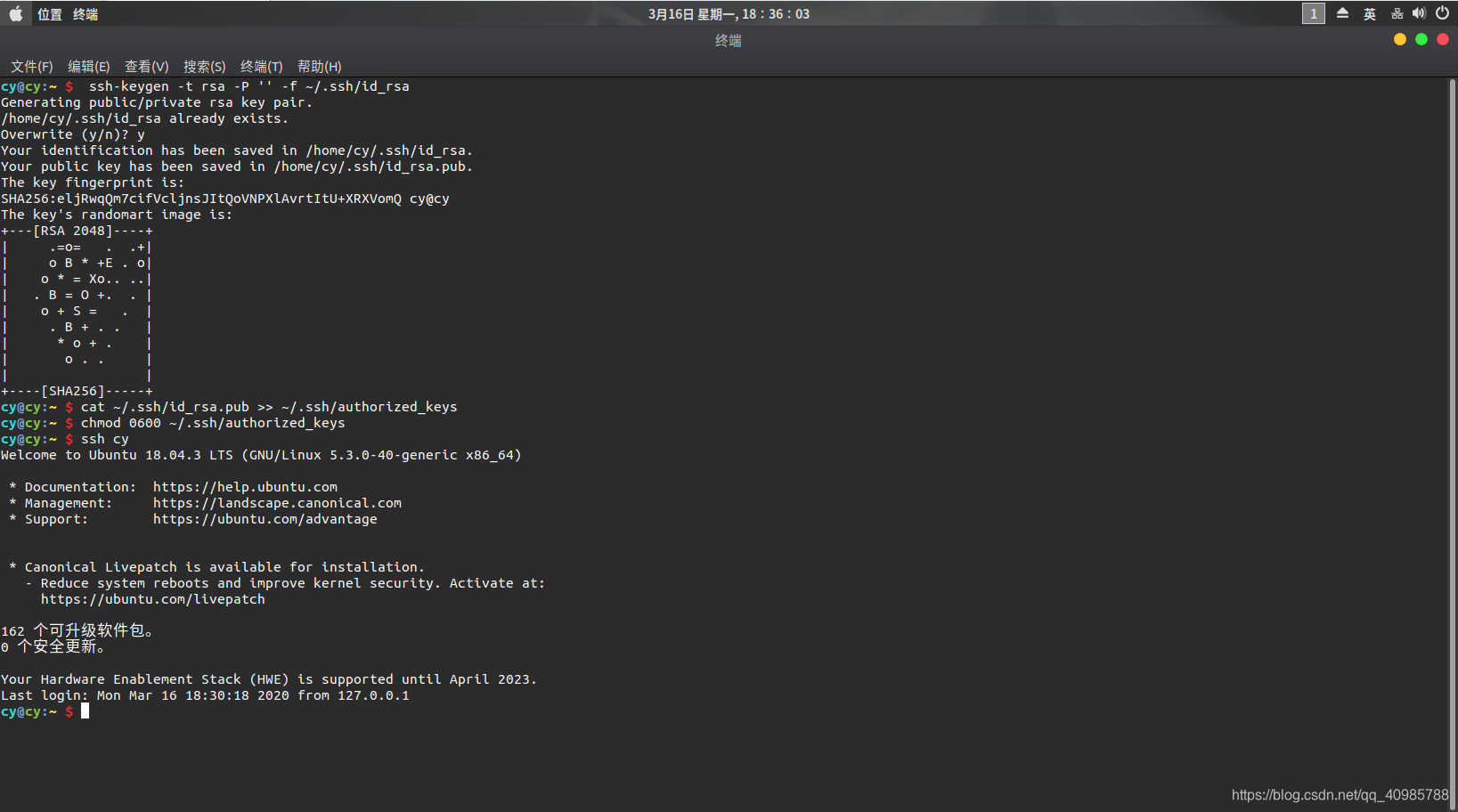
- 配置SSH免key登陆 (必须配置)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
然后用ssh连接主机,此时不需要密码即可 ssh master
-
安装jdk,hadoop
直接链接下载会很慢,我们直接在windows上下载好所需要的jdk,hadoop安装包,然后通过共享文件夹传到虚拟机。
关于共享文件夹如何设置百度一下即可。然后通过软连接建立一下连接即可
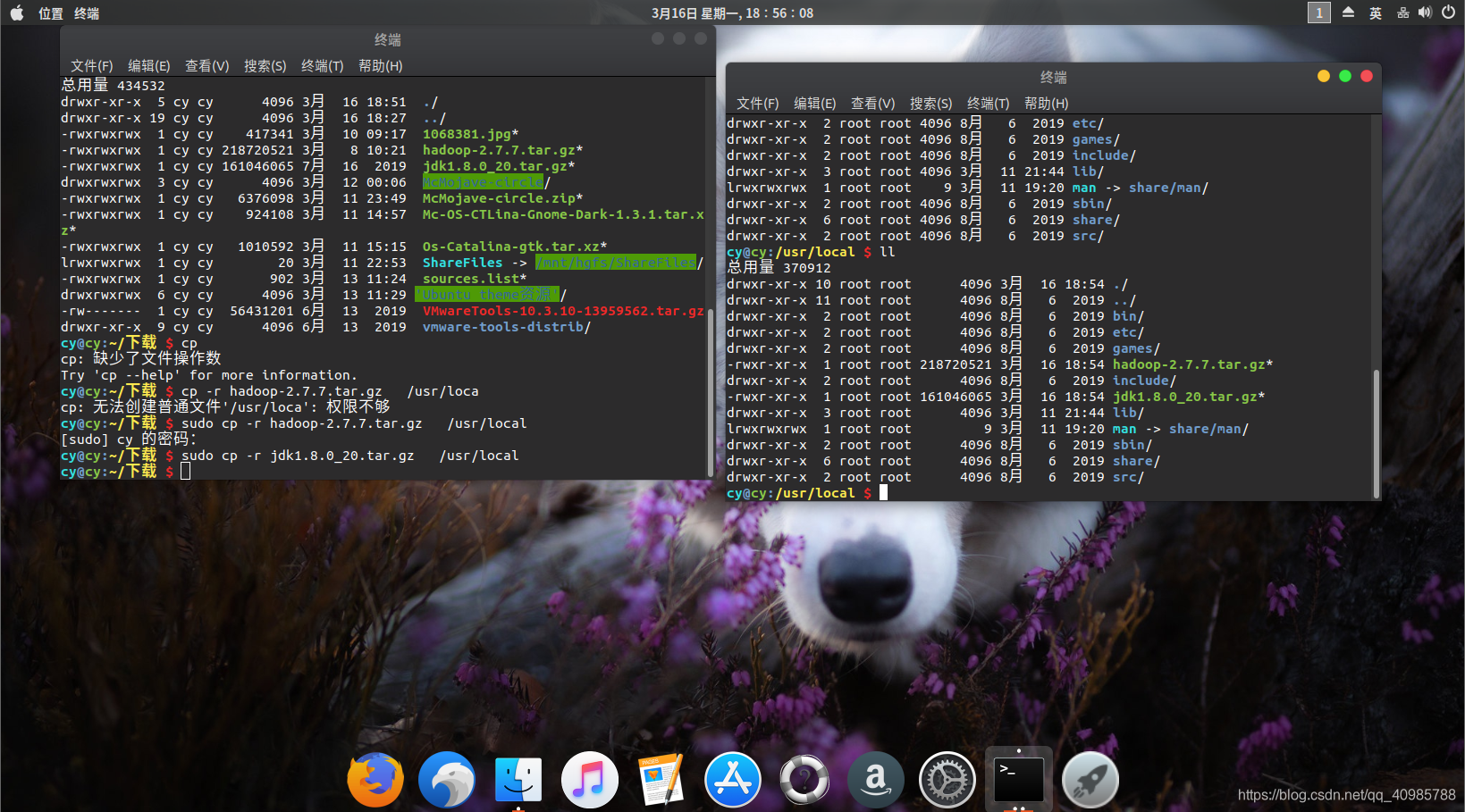
安装VMware Tools、与Windows共享文件夹、建立软连接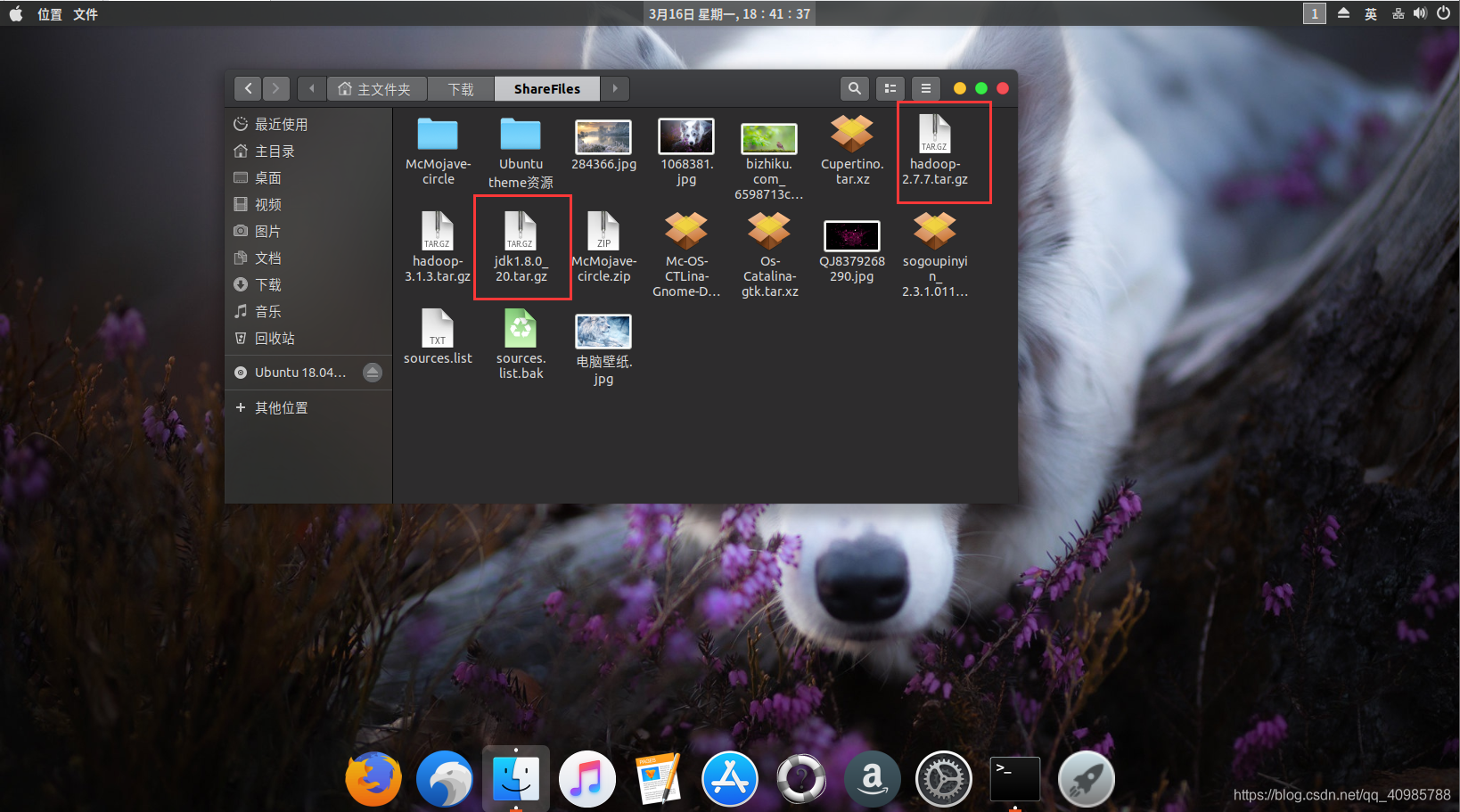 然后将jdk,hadoop压缩包全部复制到/usr/local目录下面
然后将jdk,hadoop压缩包全部复制到/usr/local目录下面cp ***** -r /usr/local ***是你的安装包
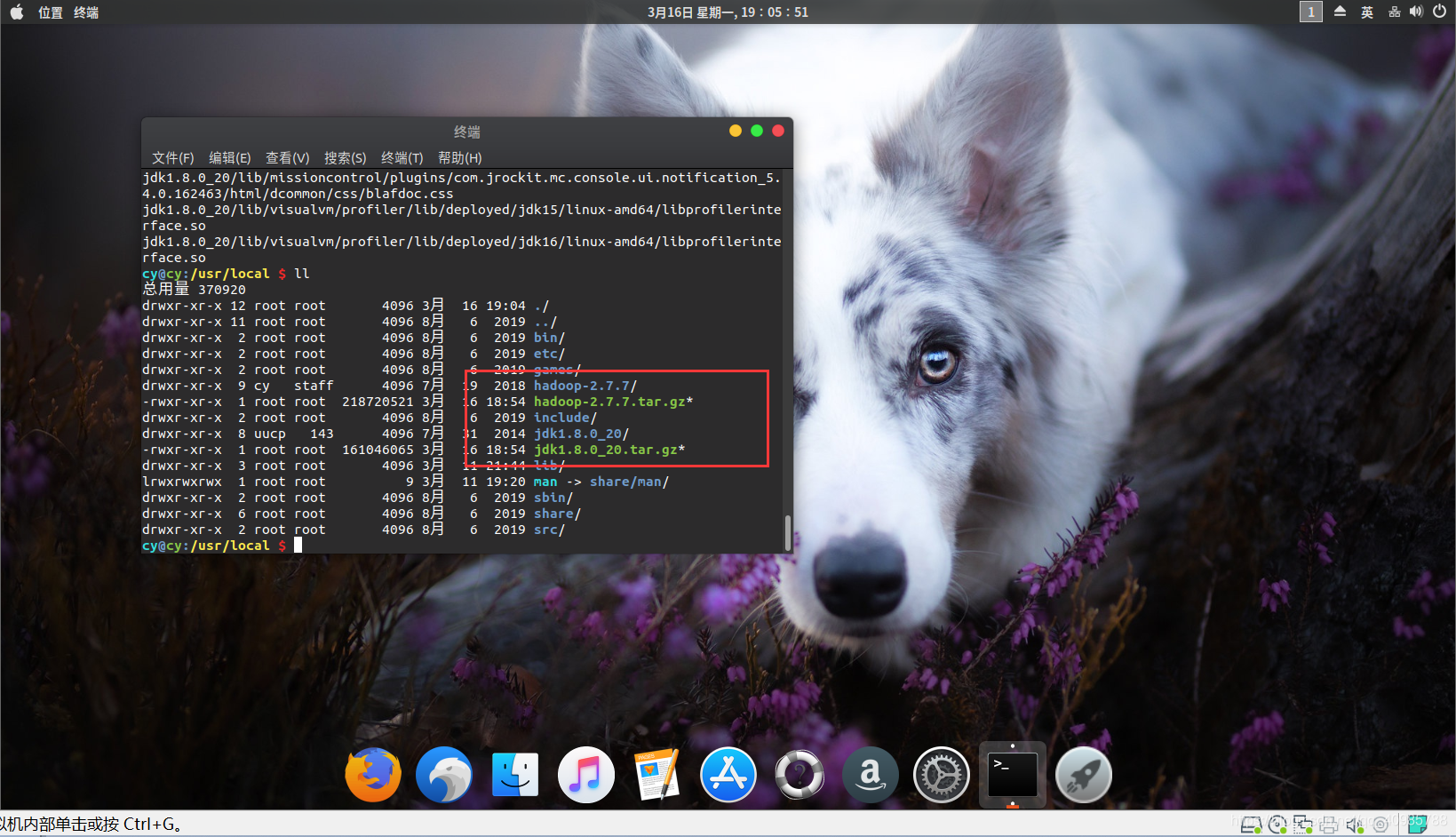
- 分别解压两个压缩包
sudo tar -zxvf hadoop-2.7.7.tar.gz
sudo tar -zxvf jdk1.8.0_20.tar.gz
- 配置java环境
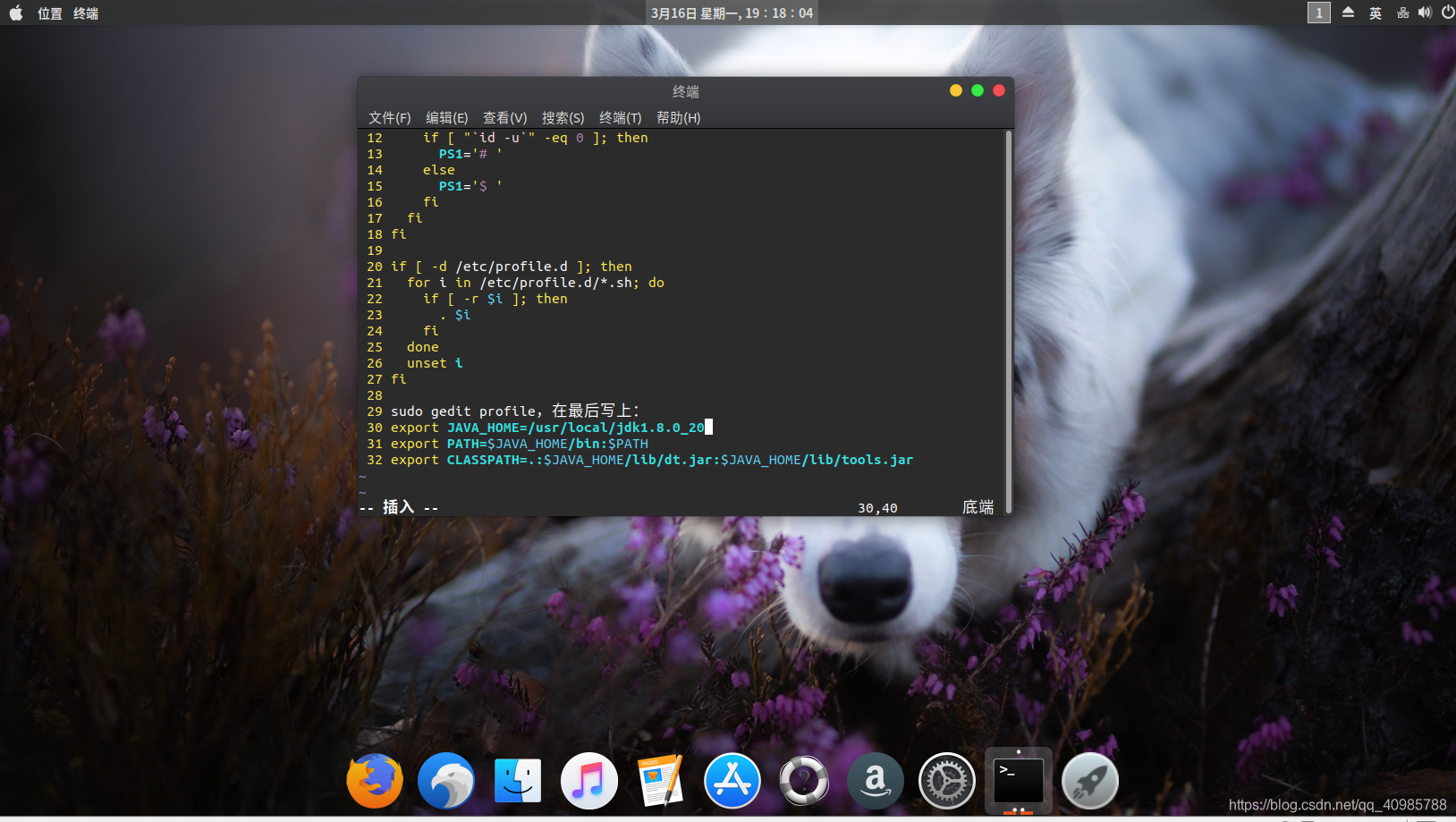
sudo vim /etc/profile
在后面添加以下
export JAVA_HOME=/usr/local/jdk1.8.0_20
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
注意你自己jdk的目录
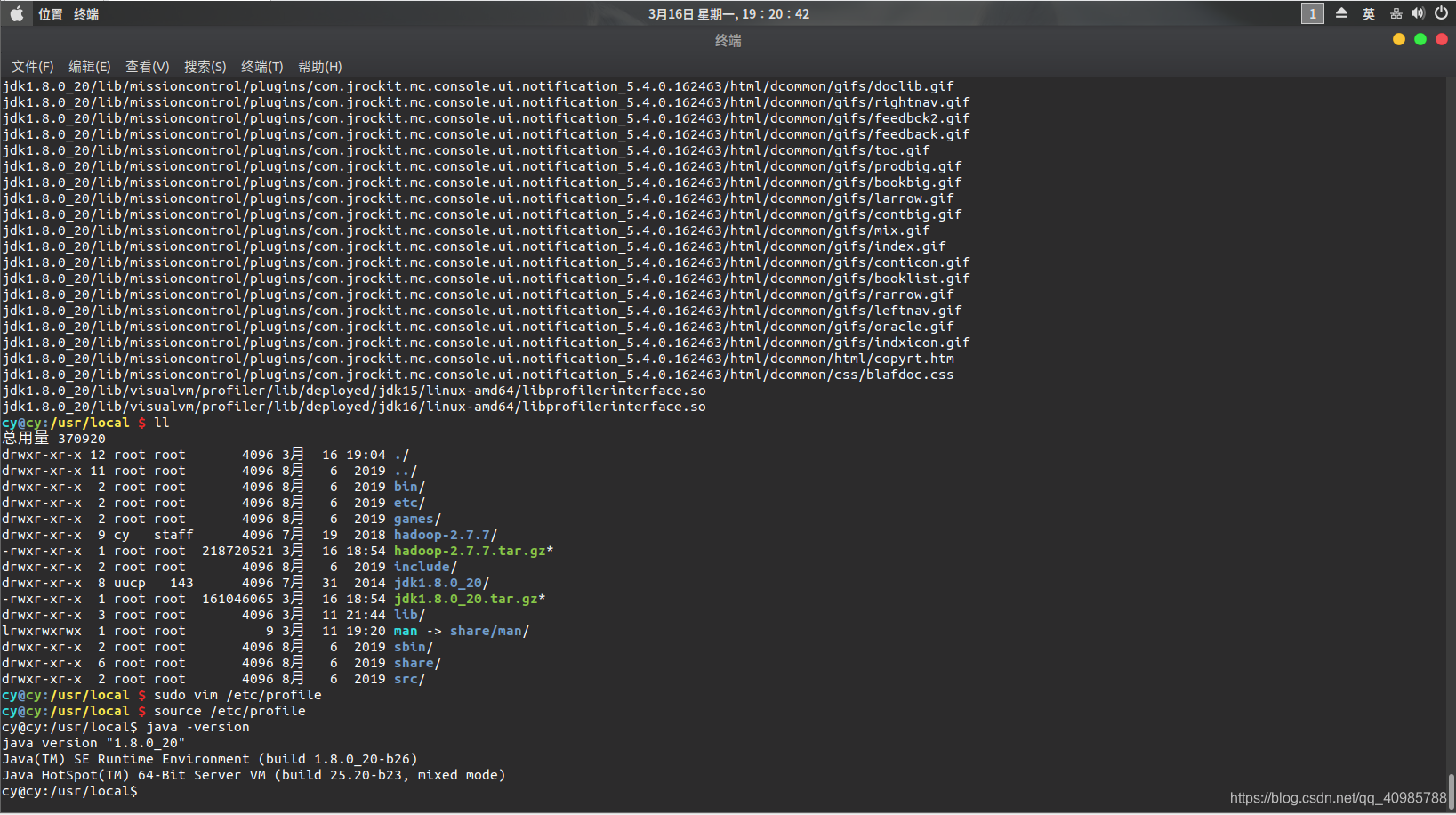
然后 source /etc/profile 使环境生效
- 配置hadoop环境
修改配置文件,设置环境变量
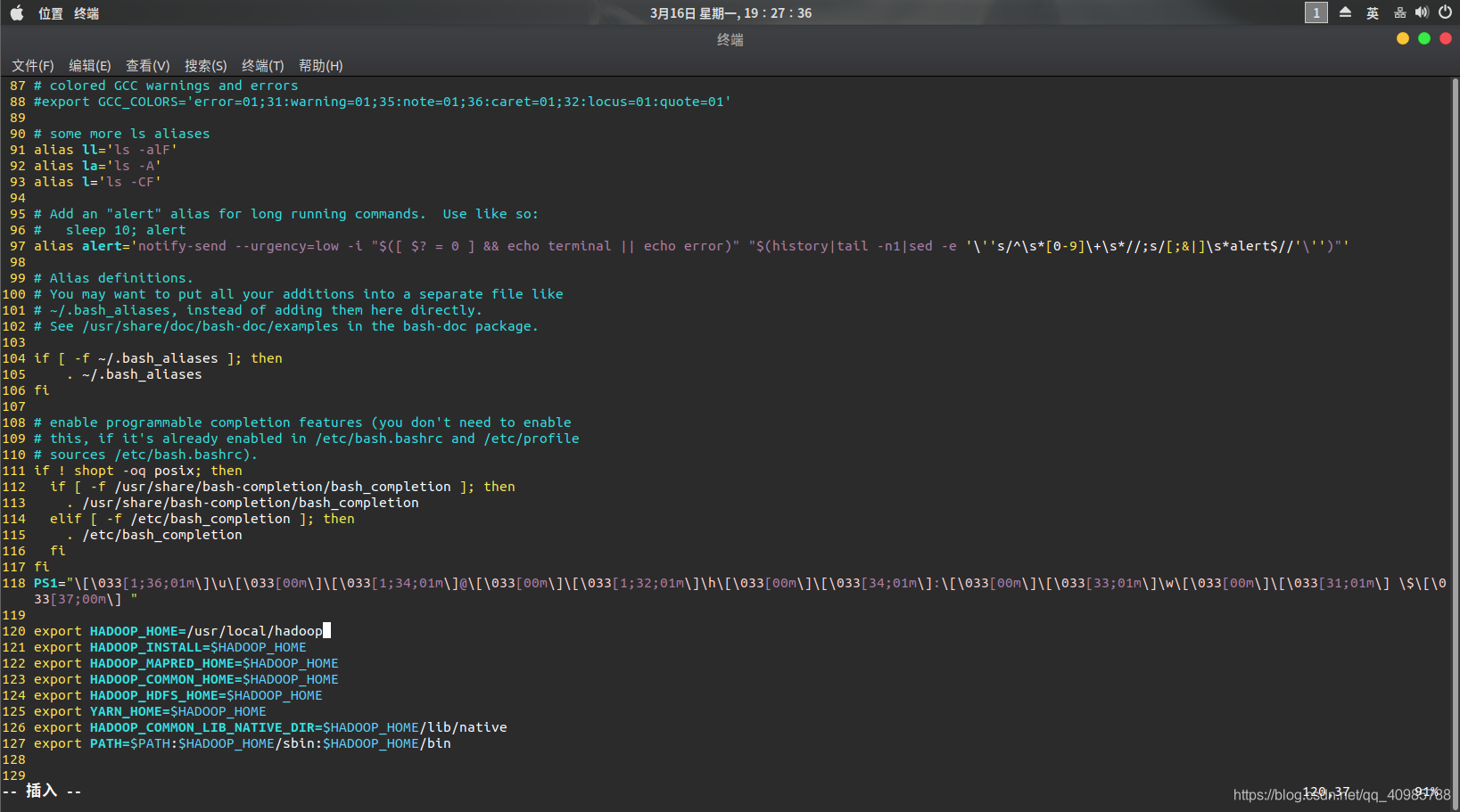
vim ~/.bashrc
在结尾添加以下:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
注意自己hadoop的路径
使得配置文件生效 source ~/.bashrc
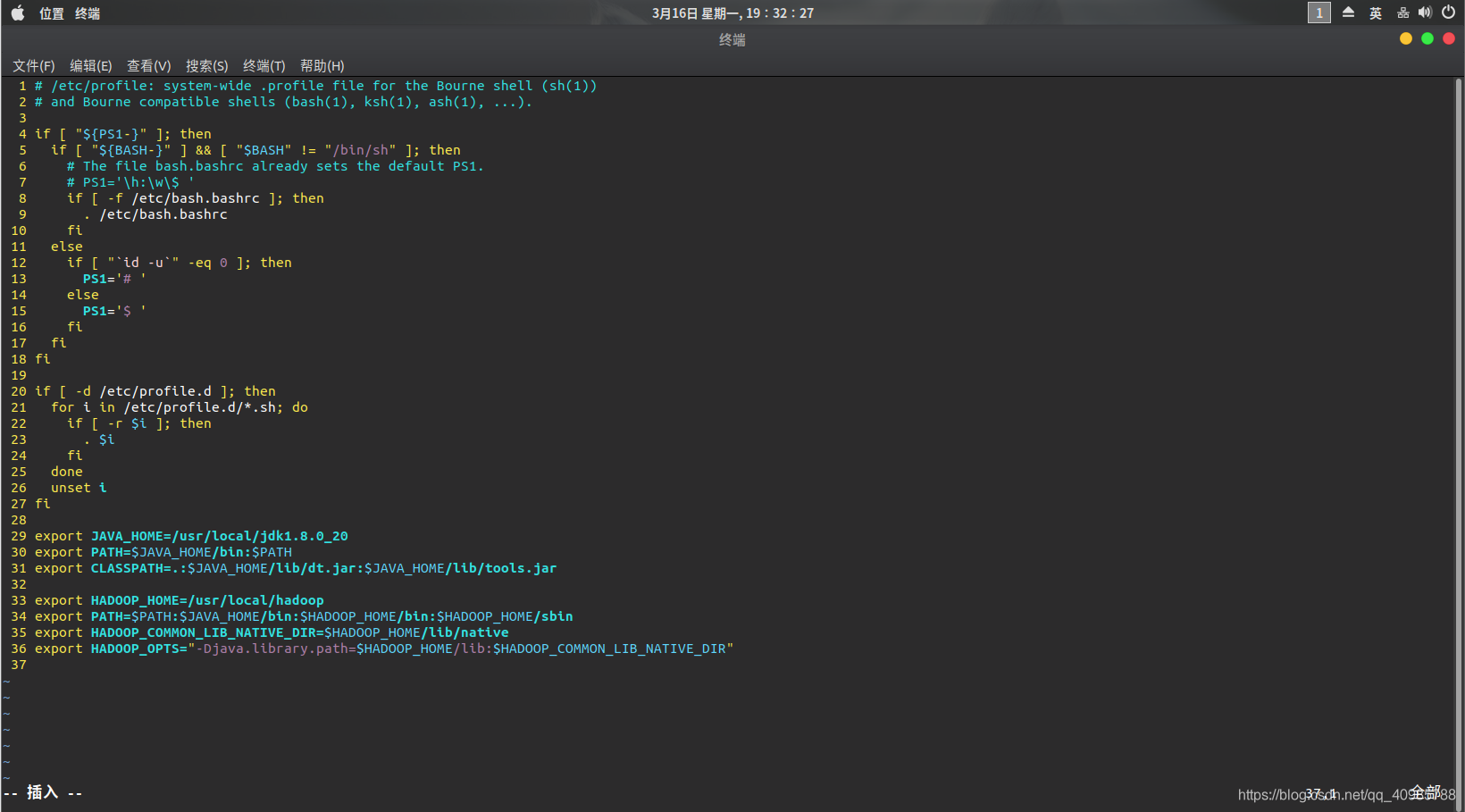
- vim /etc/profile
结尾添加以下,注意自己的hadoop路径
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
- 修改hadoop-env.sh
cd /usr/local/hadoop/etc/hadoop
sudo vim hadoop-env.sh
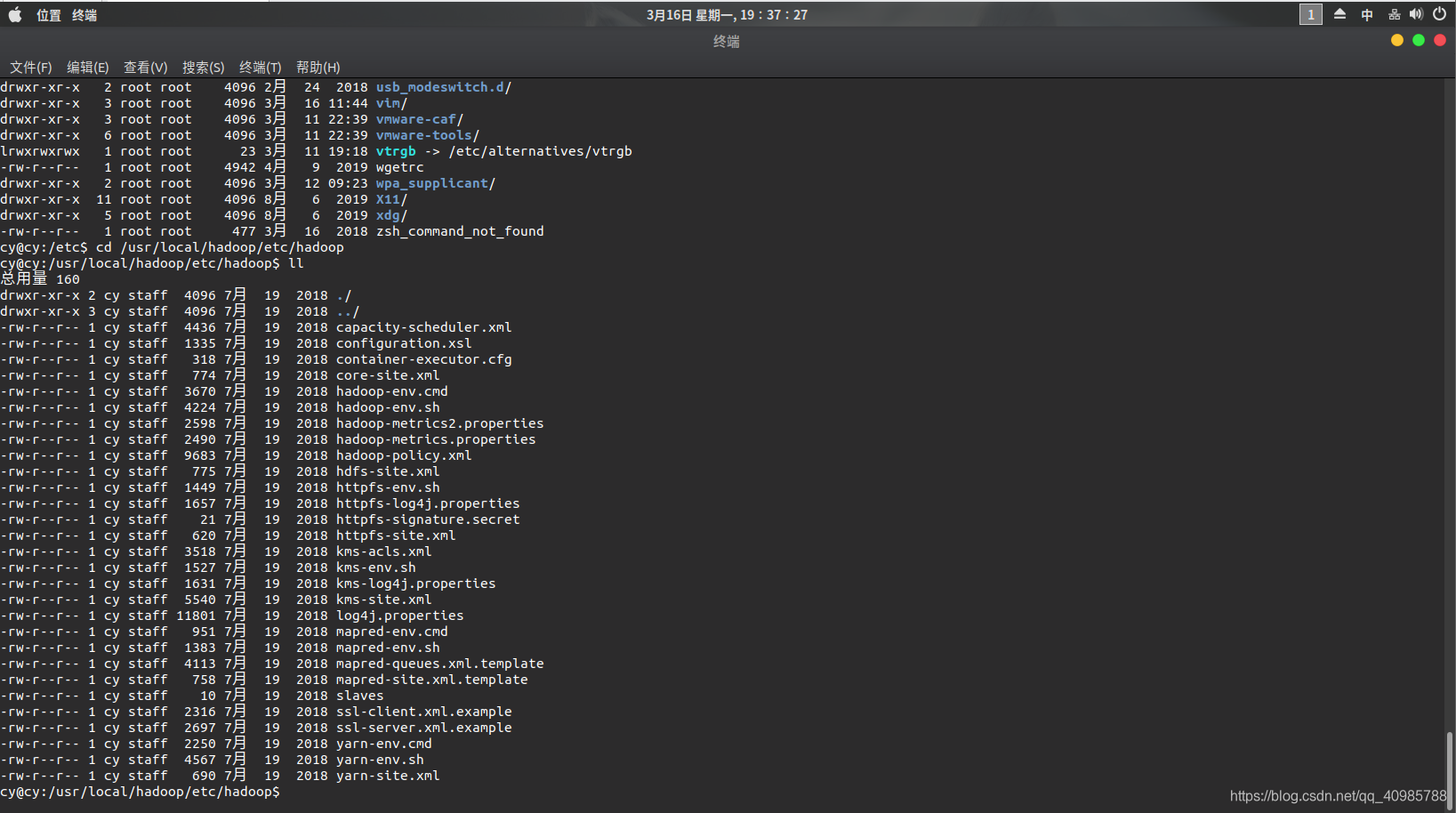
首先修改java_home路径
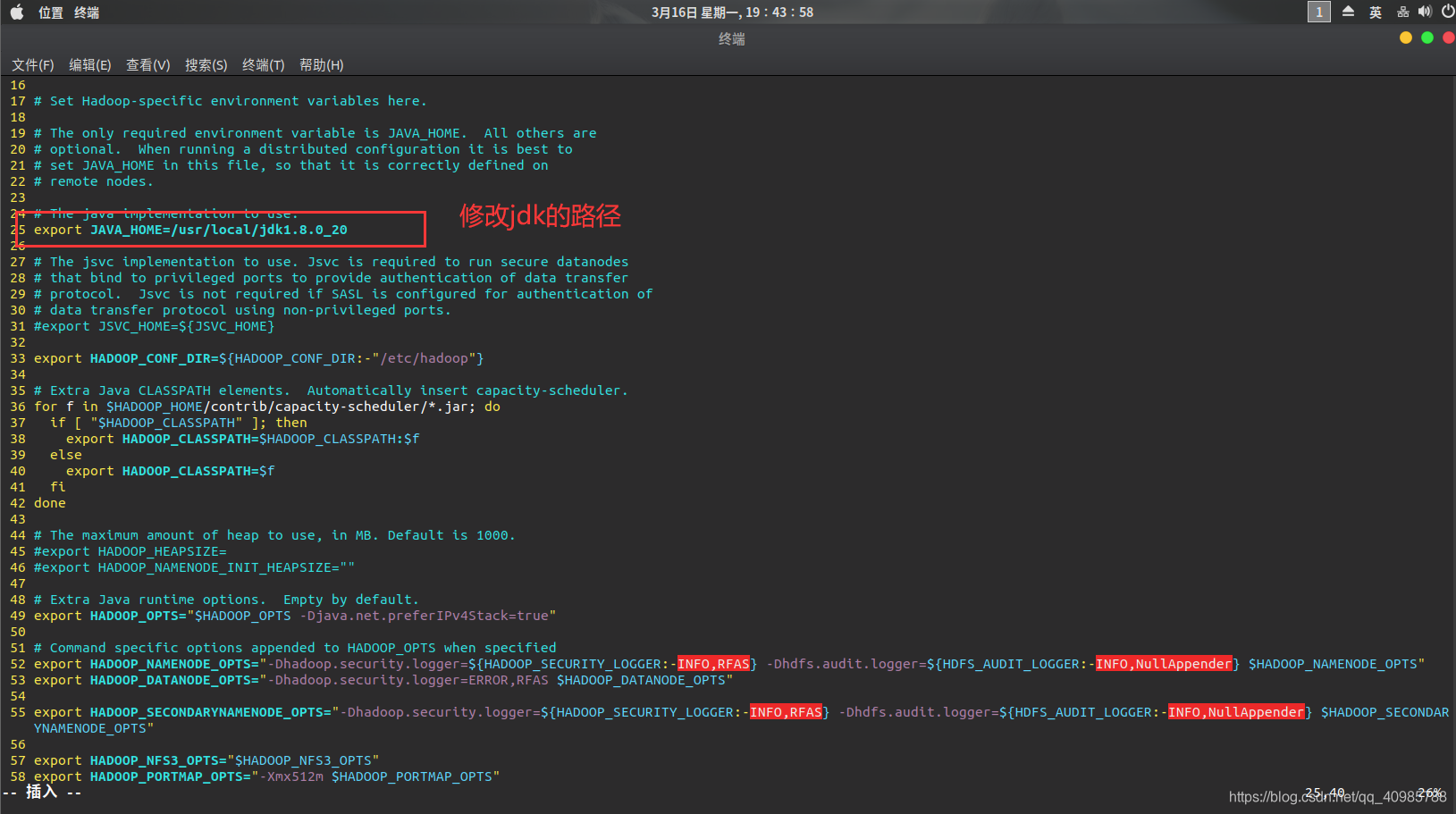
然后在结尾添加以下:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
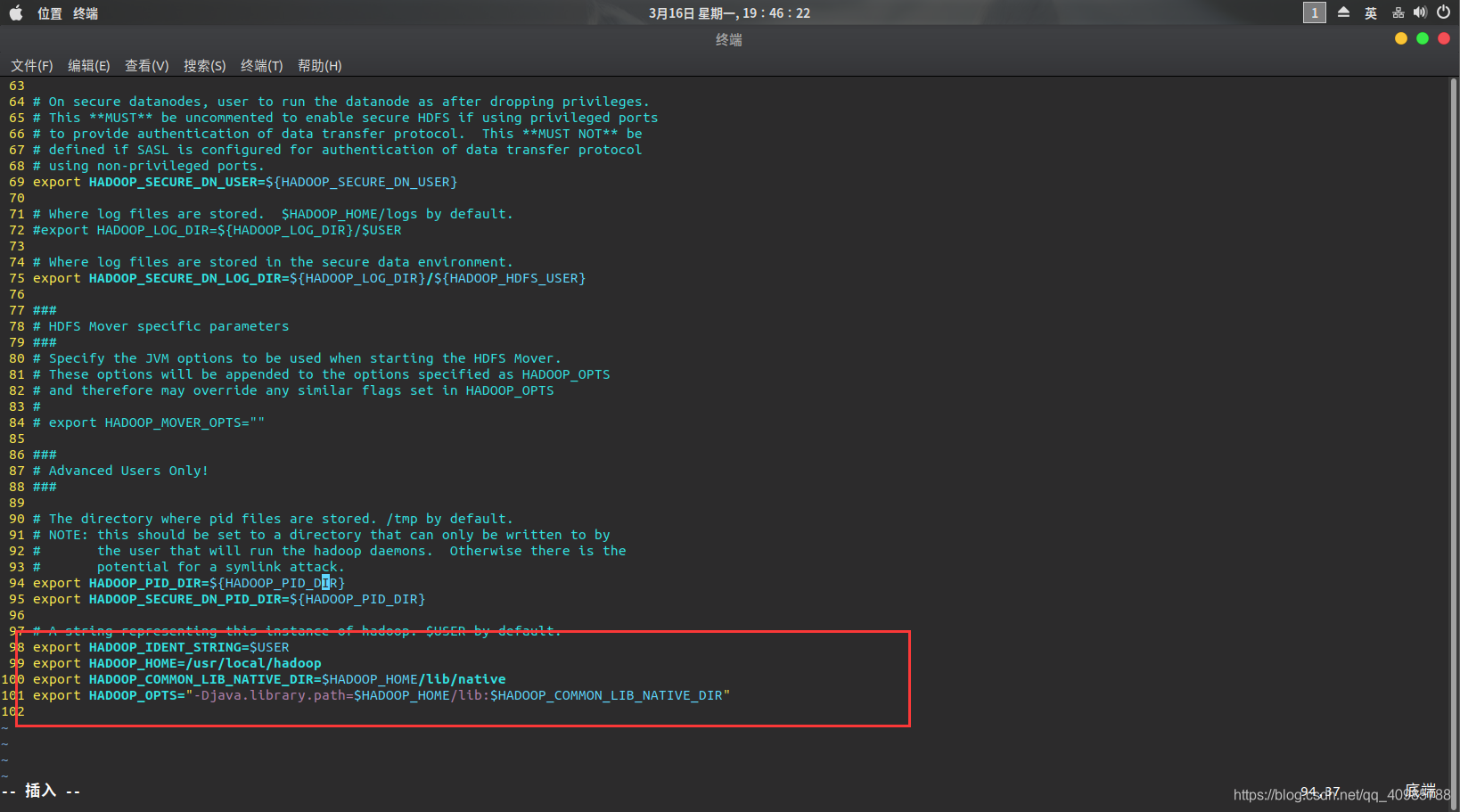
- 修改core-site.xml
在结尾添加以下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
其中我们需要在hadoop目录下新建一些文件夹。
tmp文件夹:/usr/local/hadoop/tmp
然后在tmp下面新建dfs
然后在dfs下面分别新建两个文件夹 name data
注意各个目录之间的结构是什么。
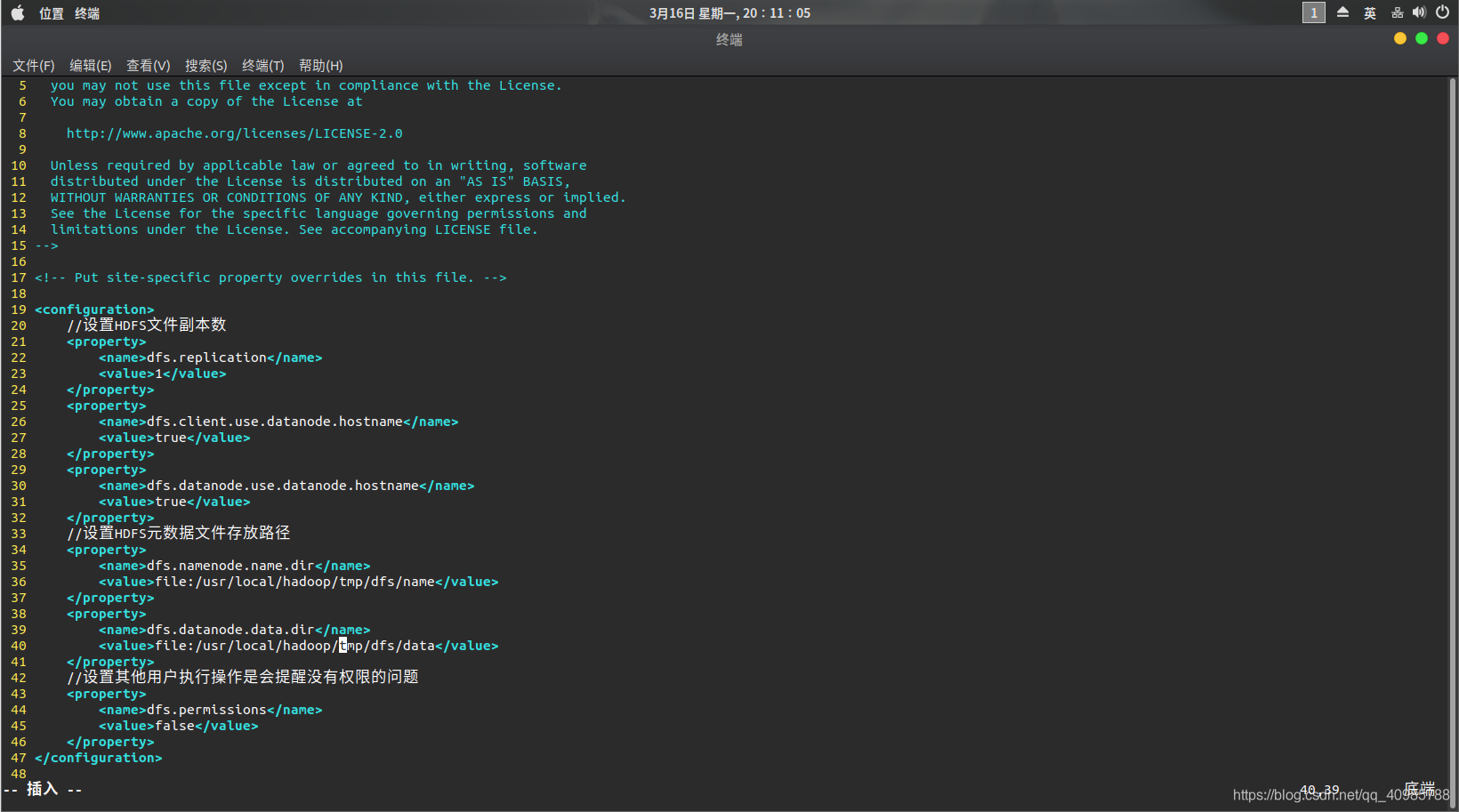
- 修改hdfs-site.xml
<configuration>
//设置HDFS文件副本数
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
//设置HDFS元数据文件存放路径
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
//设置其他用户执行操作是会提醒没有权限的问题
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
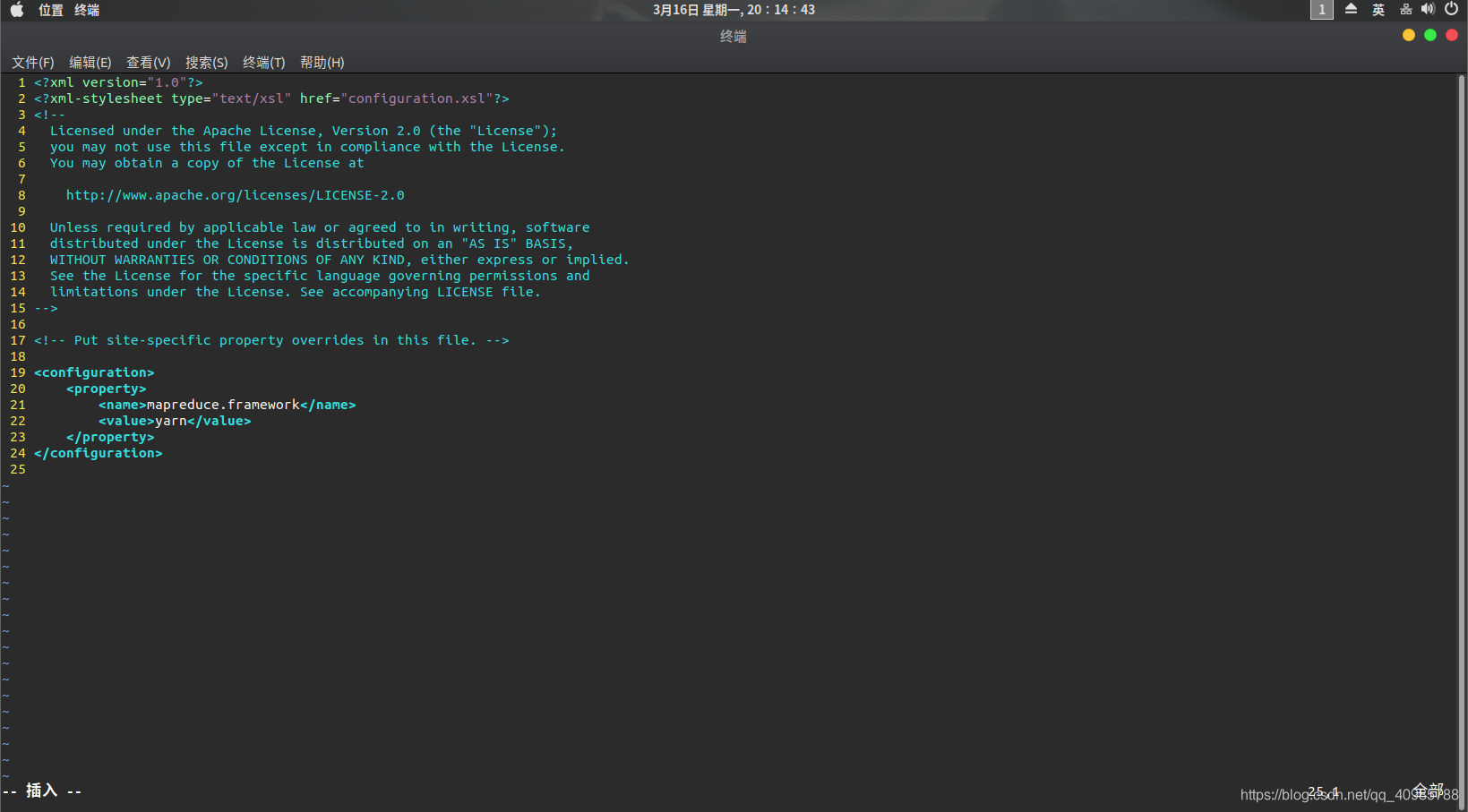
- 修改mapred-site.xml
将/usr/local/hadoop/etc/hadoop/mapred-site.xml.template的后缀.template去掉。然后
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
在结尾添加以下:
<configuration>
<property>
<name>mapreduce.framework</name>
<value>yarn</value>
</property>
</configuration>
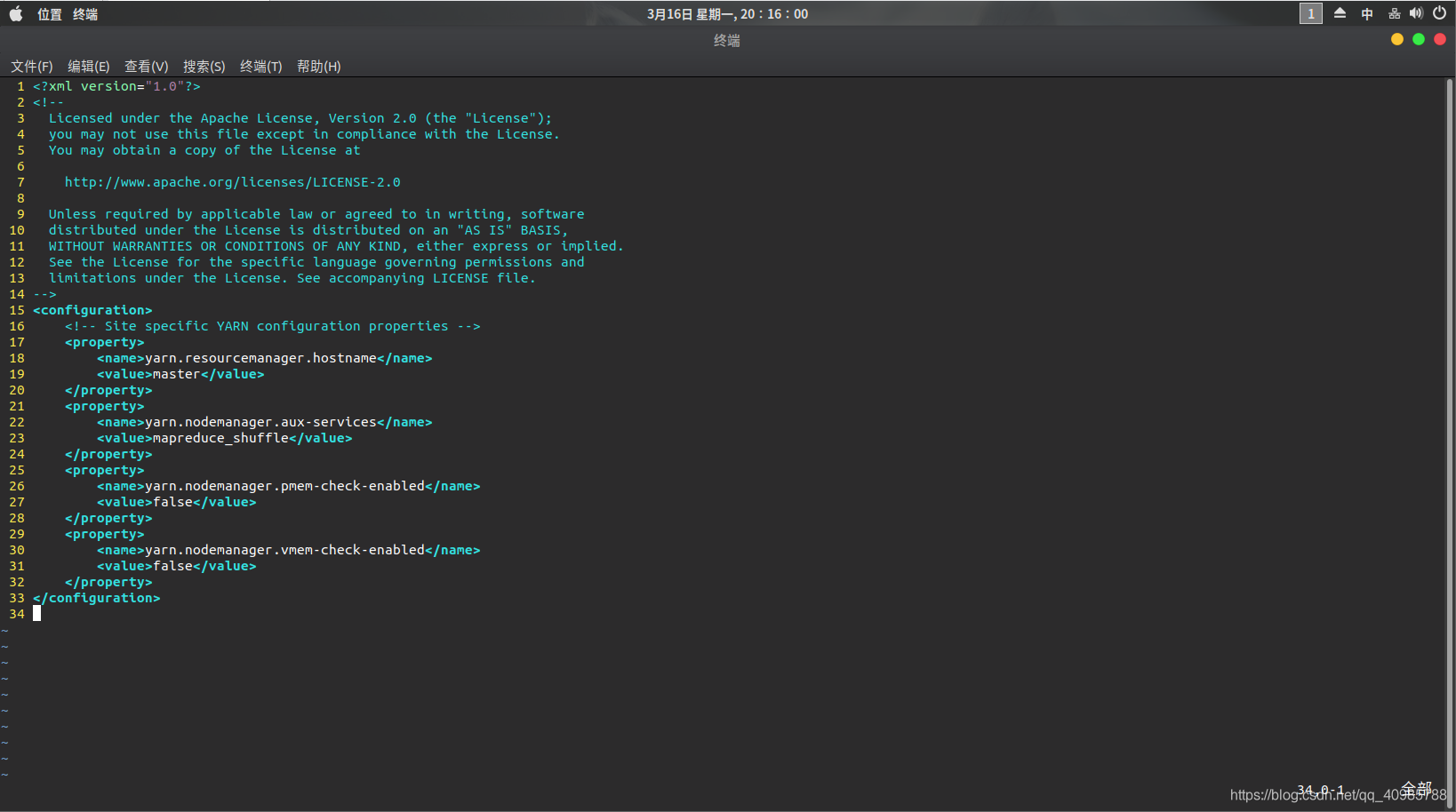
15. yarn-site.xml
在结尾添加以下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
16. 修改slaves文件
将localhost直接改成主机名(这里为master),然后再添加节点主机名:我这里为Slave1 Slave2
这里截图只截了一半,master后面还有Slave1 Slave2
这里必须要三个都写,不然后面克隆的时候另外的两台节点主机还要回来重新配置slave文件。
三、克隆master搭建完全分布式
- 右键master–>管理–>克隆–>虚拟机中当前状态–>创建完整的克隆
如下图所示,克隆了两台分别为Slave1 Slave2
- 重命名主机
启动三台虚拟主机,分别对两台节点主机命名为Slave1 Slave2
sudo vim /etc/hostname
然后分别查看虚拟机的ip
ifconfig
我的ip分别为
192.168.31.31
192.168.31.14
192.168.31.163
前三段必须要相同,不然无法搭建,只要在相同的环境即可。
然后分别在Xshell上连接三台虚拟主机。这样做的目的是防止直接在虚拟机上操作造成卡顿。
- 验证三台主机之间能否ping通
由于之前的master主机上我们已经配置了ssh免密登陆了,所以克隆出来的两台节点主机理论上也是可以的。
我们在master主机上
ssh Slave1
ssh Slave2
然后在一台节点主机上的操作以此类推,如果三台主机之间都可以相互连接即可。
由于电脑太卡,就不在这里截图了。
四、将mater的java hadoop环境变量复制到节点主机上
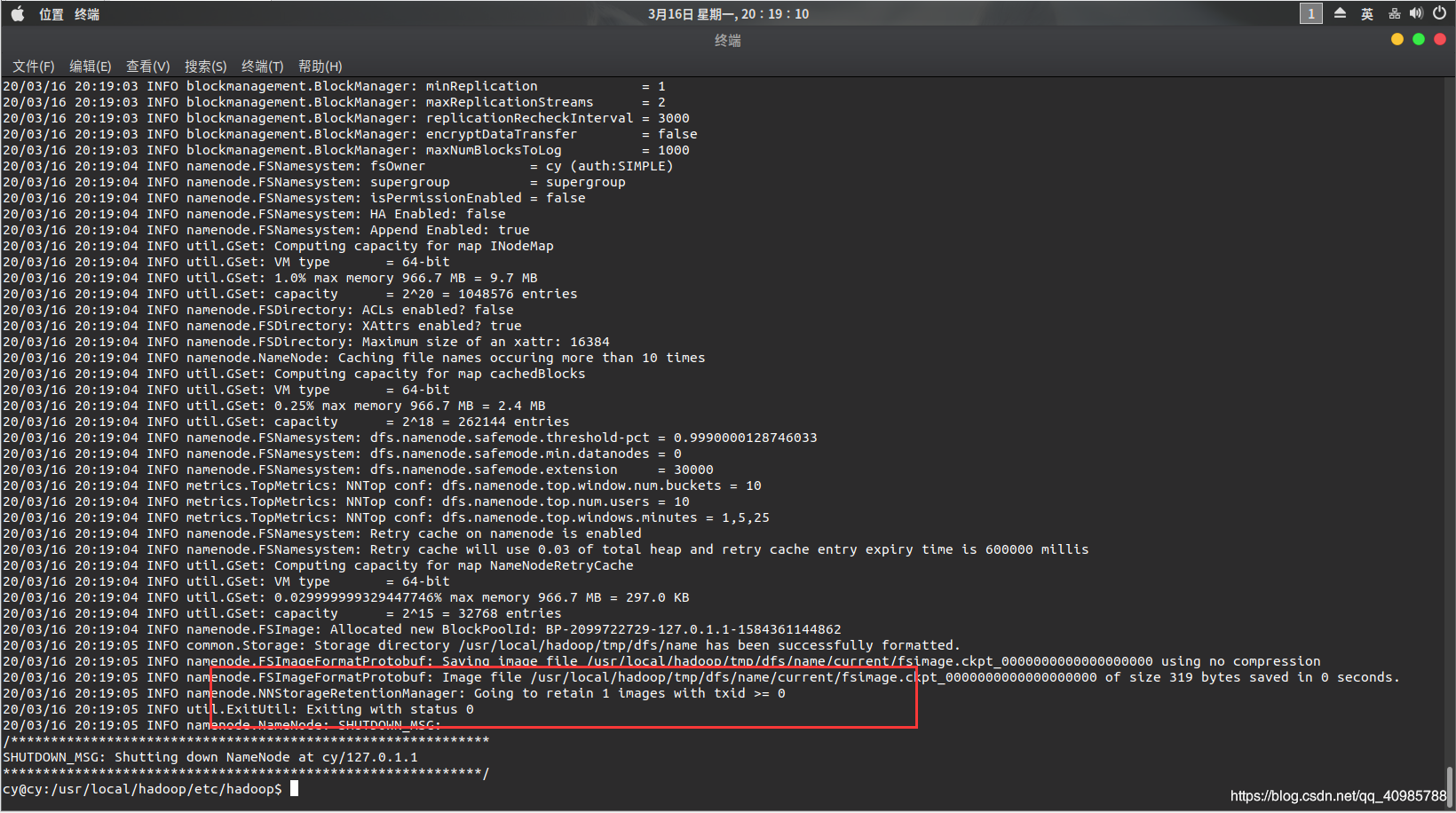
- 格式化master主机hadoop环境
/usr/local/hadoop/bin/hdfs namenode -format
注意:只能格式化一次,再次格式化的时候需要将tmp文件夹恢复到初始状态。
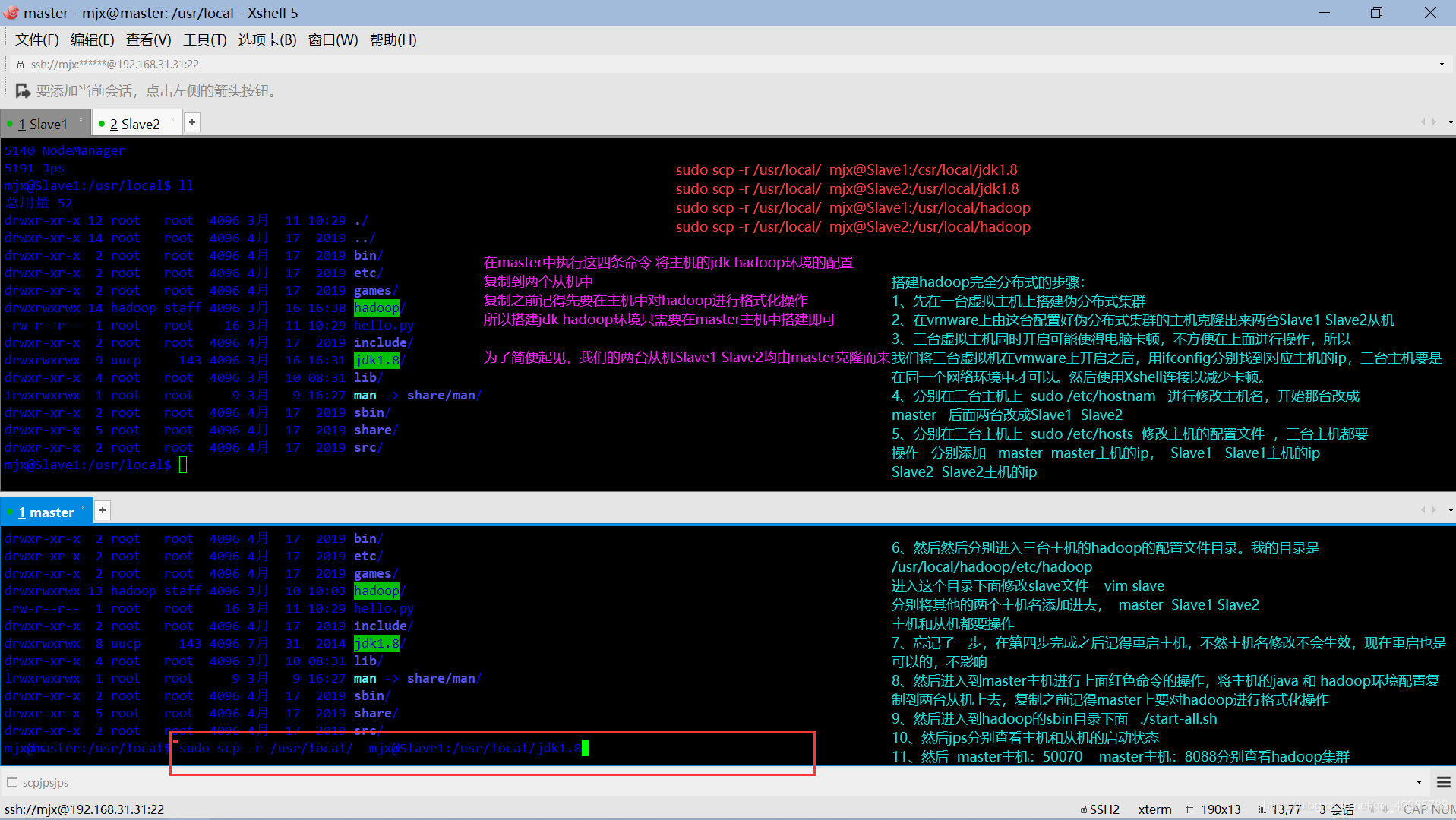
- 克隆环境
sudo scp -r /usr/local mjx@Slave1:/usr/local/jdk1.8
sudo scp -r /usr/local mjx@Slave2:/usr/local/jdk1.8
sudo scp -r /usr/local mjx@Slave1:/usr/local/hadoop
sudo scp -r /usr/local mjx@Slave2:/usr/local/jdk1.8
其中的参数说明:
/usr/local 是节点主机上jdk 和 hadoop的安装目录,/usr/local/jdk1.8是master主机的jdk1.8目录
/usr/local/hadoop是master主机的hadoop目录。
mjx是用户名,三台主机的用户名都是mjx。
-
进入到master 启动hadoop集群
只需要在master中启动即可。
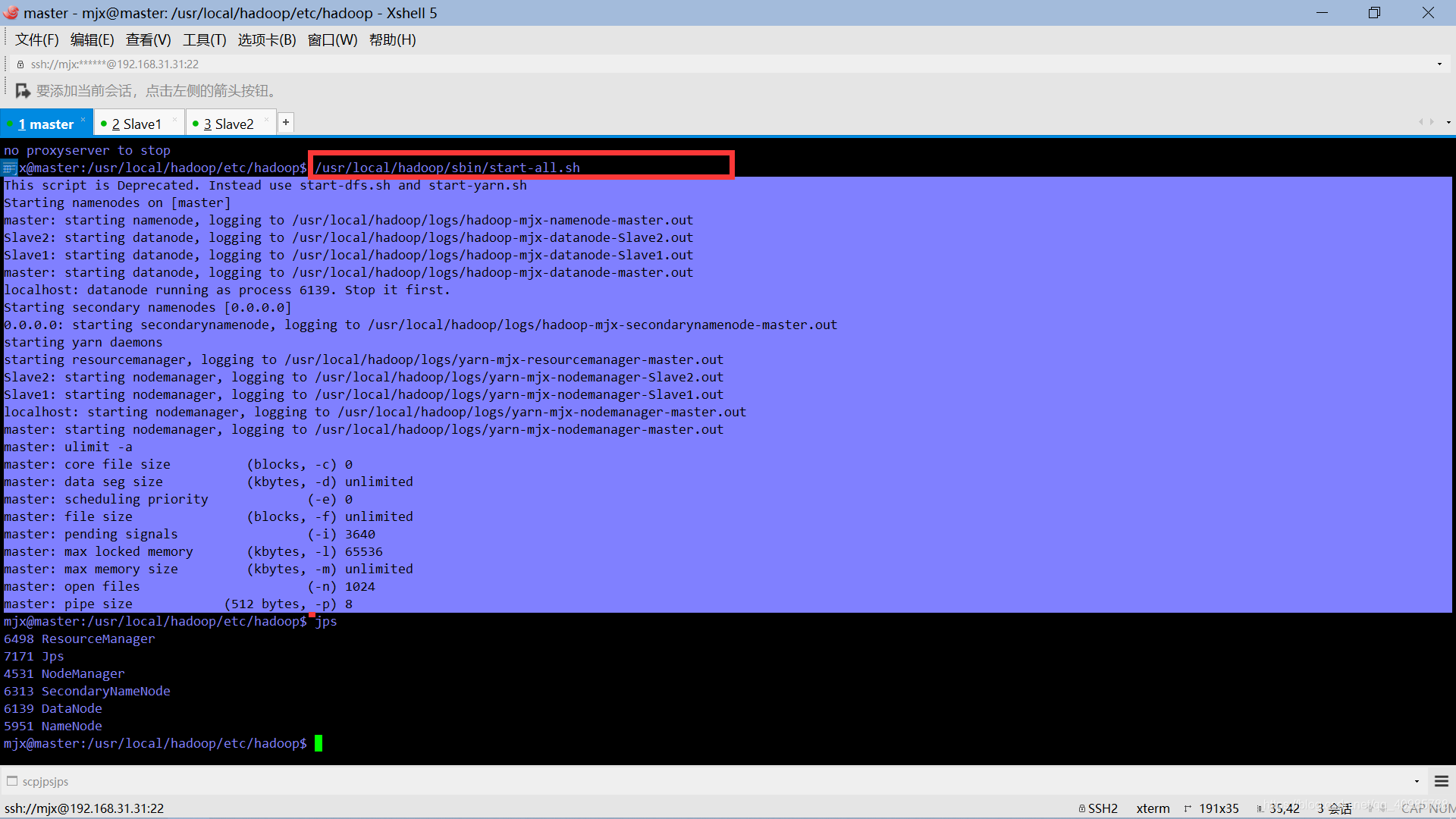
然后分别查看三台虚拟机的启动状态。
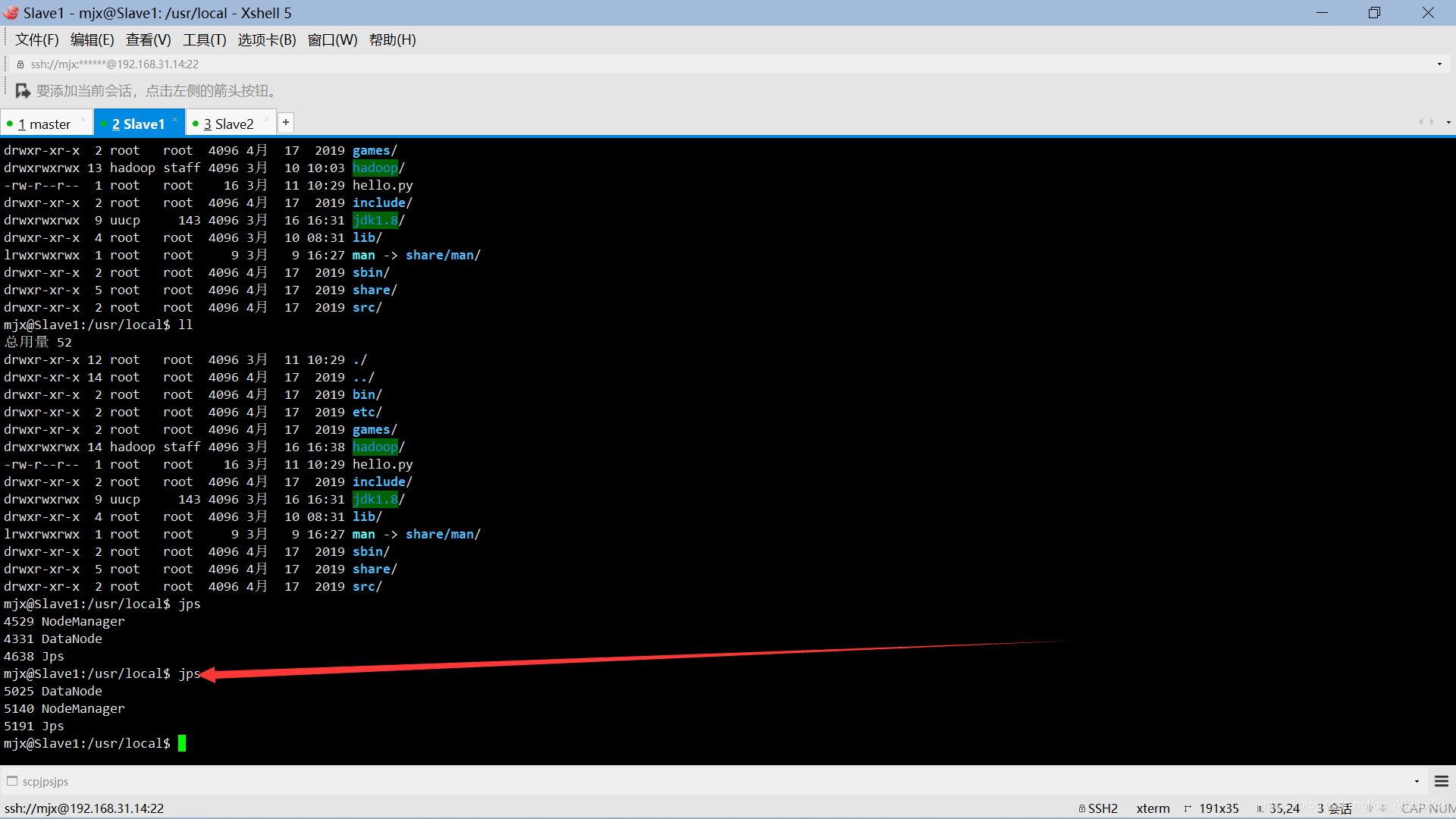
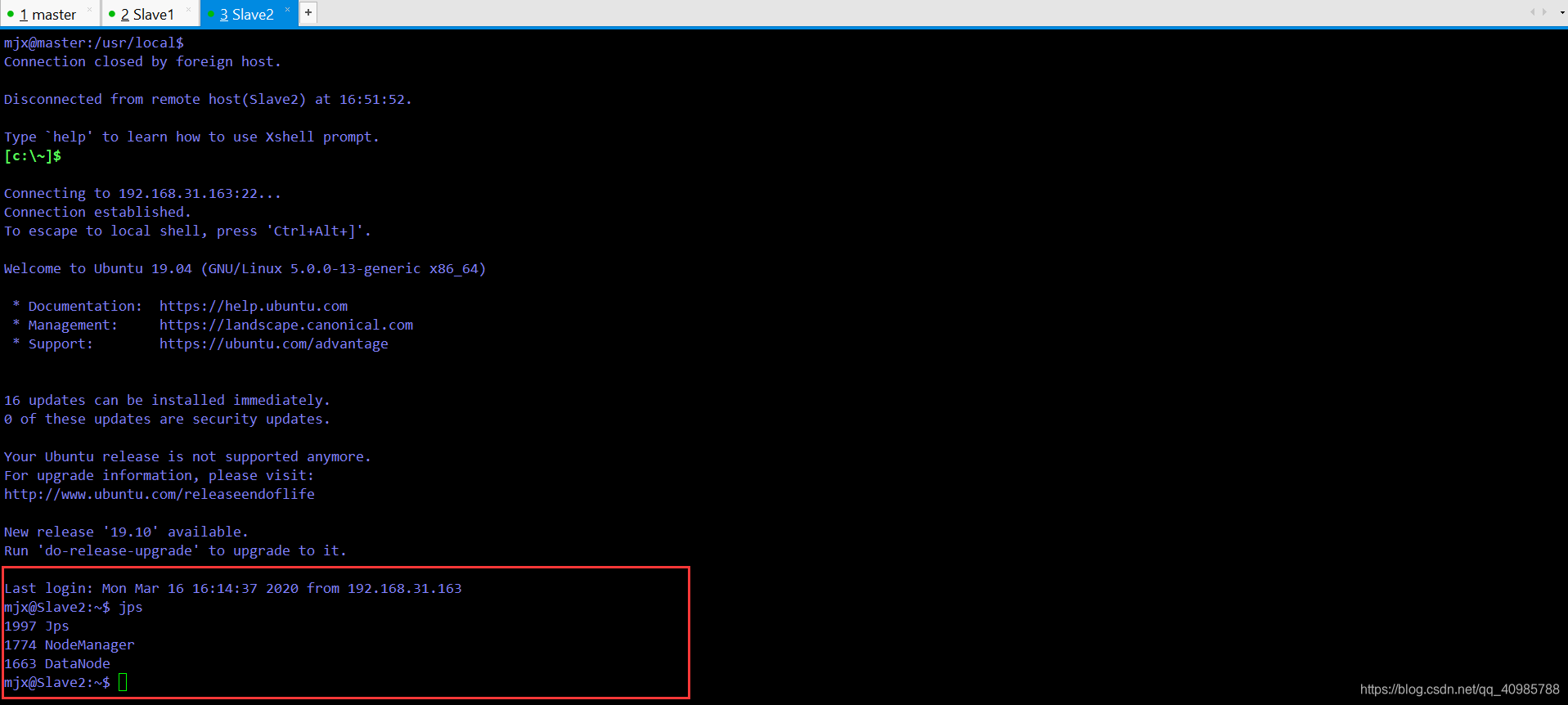
可以看到master和两台节点主机都正常启动。- 浏览器可视化管理Hadoop集群
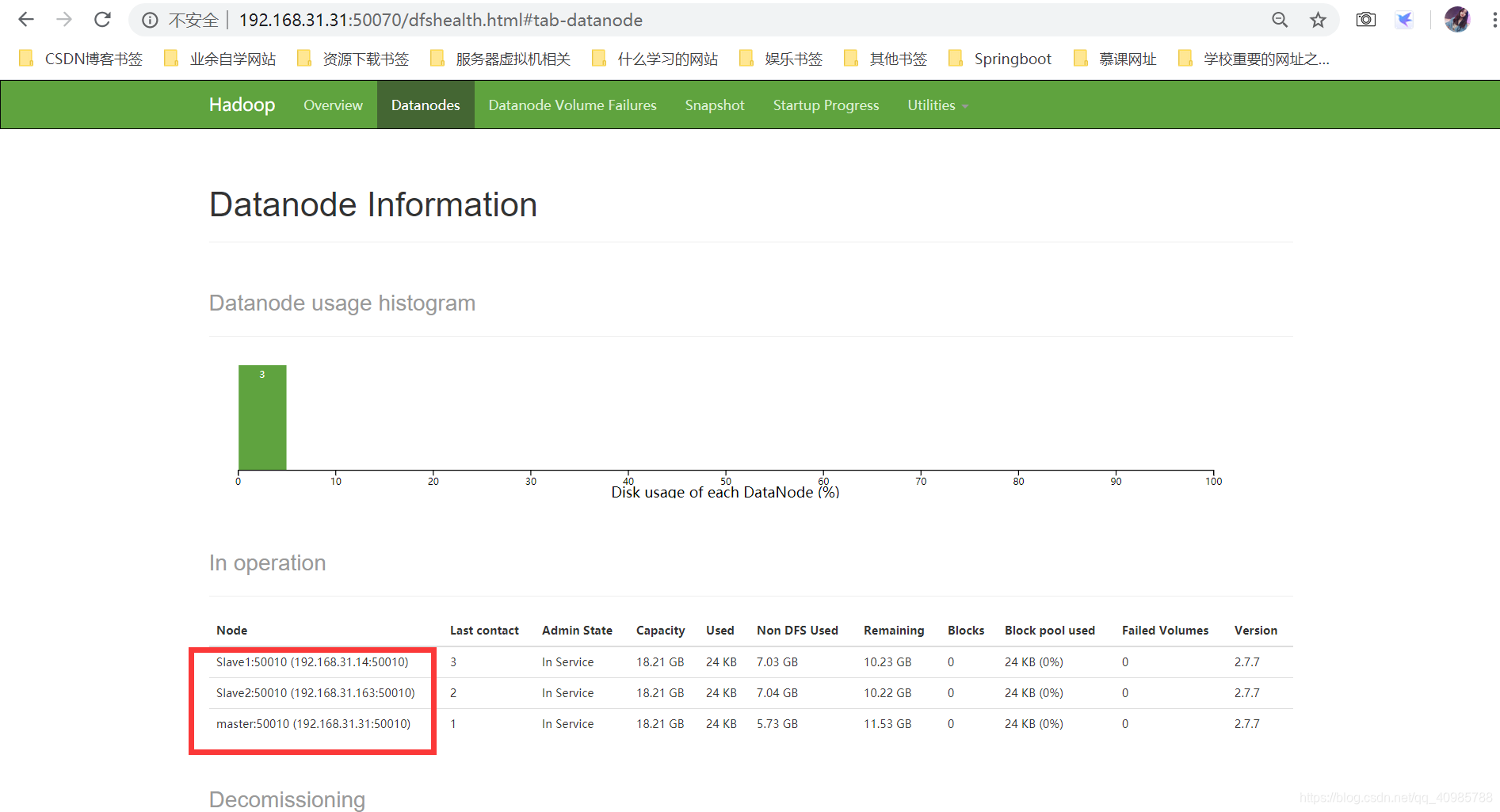
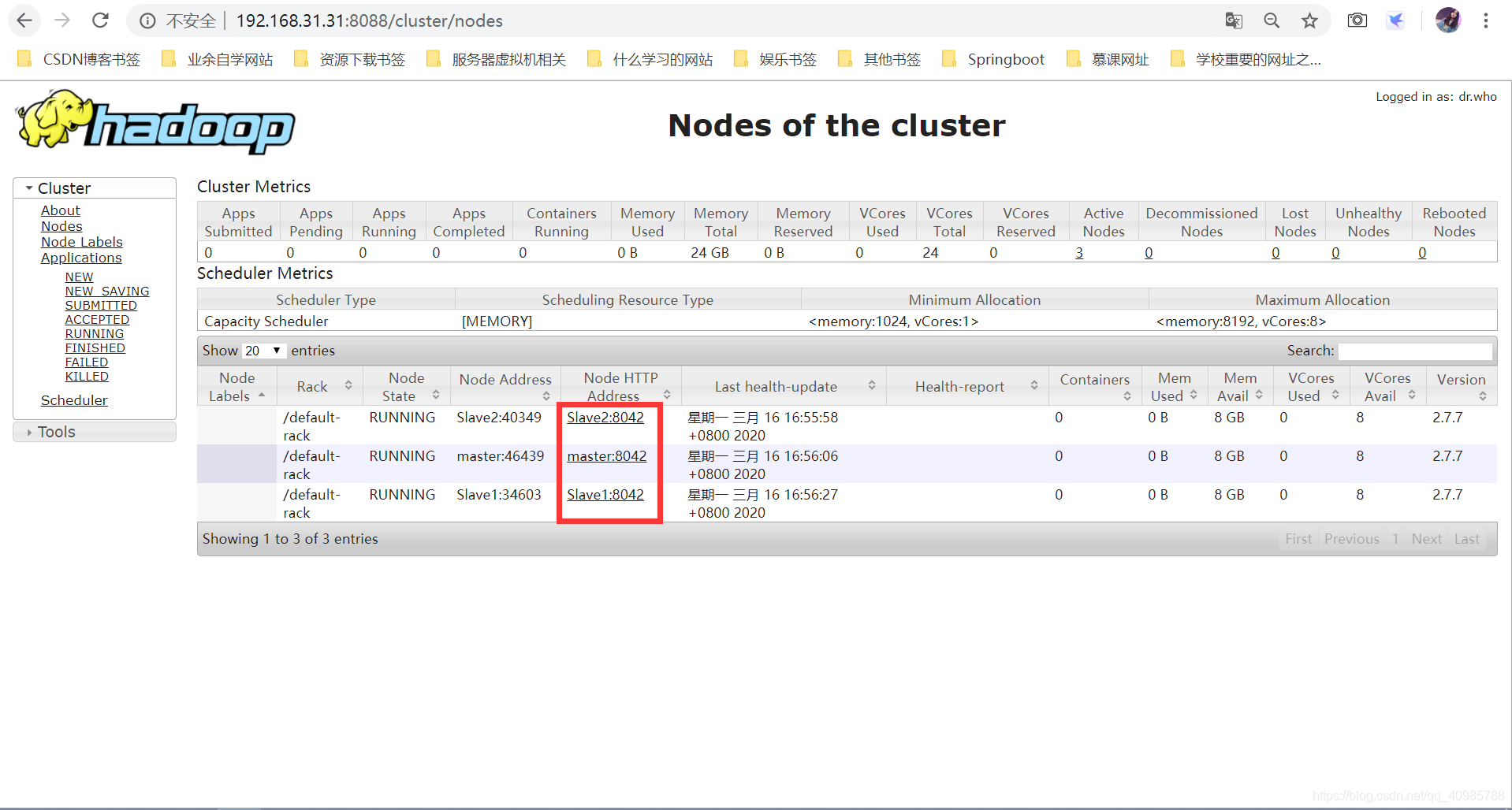
到此完毕!
- 浏览器可视化管理Hadoop集群
