基于MATLAB GUI的人脸识别系统(包含传统/深度学习方法)

人脸检测与识别作为计算机视觉研究的核心内容之一,是一个不断发展的领域,并且还是模式识别、机器学习和数据挖掘等相关学科交叉研究的热点,已经发展成为计算智能的重要研究课题。本文是作者人脸识别系统V1.0,基于MATLAB平台,主要实现人脸识别功能,包含3种人脸识别算法,PCA-最近邻、PCA-SVM、以及深度学习的方法,都在ORL数据集上取得了较高的识别率。
00目录
1 应用背景
2 研究历程
3 ORL数据库介绍
4 人脸识别算法
5 系统实现
6 展望
01 应用背景
人脸识别技术就是以计算机为辅助手段,从静态图像或动态图像中识别人脸。问题一般可以描述为给定一个场景的静态或视频图像,利用已经存储的人脸数据库确认场景中的一个或多个人。一般来说,人脸识别研究一般分为3个部分:从具有复杂背景的场景中检测并分离出人脸所在的区域;抽取人脸识别特征;然后进行匹配和识别。
虽然人类从复杂背景中识别出人脸相当容易,但人脸的自动机器识别却是一个极具挑战性的课题。它跨越了模式识别,图像处理、计算机视觉以及神经生理学、心理学等诸多研究领域。
如同人的指纹一样,人脸也具有唯一性,可用来鉴别一个人的身份,人脸识别技术在商业、法律和其他领域有着广泛的应用。
02 研究历程
60 年代末,Chan 等人[1]发表了自动人脸识别(Automated Face Recognition,AFR)研究技术报告,以人脸特征点的间距、比率等作为特征,建成了一个人脸识别系统。以此为时间点,越来越多的学者致力于人脸识别的研究。
第一个阶段,是上世纪 60 年代到 90 年代。这一阶段的人脸识别研究主要是集中于人工设计的特征提取方法,典型的有基于几何特征和基于局部模式的方法。提取人脸几何特征,需要手动标定面部的一些特征点,如眼角、嘴角、鼻尖等部位,并对各特征点的距离进行归一化,刻画出人脸的关键轮廓,例如局部二值模式LBP。这类方法抗干扰能力不好,当采集到的人脸图像有些许偏移则识别失败。
第二个阶段,研究者们认为人工设计的特征提取方法过于单一,往往只能在约束条件下取得较好的结果,于是这一阶段出现了大量基于特征学习的方法。这类方法是从数据中学习种特征提取模型,只要训练数据和测试数据分布一致,就能取得非常高的识别精度,根据这类方法的学习模型是否为深度模型, 又可细分为深度特征学习(如深度卷积神经网络)和浅层特征学习(如PCA算法)。[2]
3 ORL数据库介绍
ORL人脸数据集 http://www.datatang.com/data/13501 共包含40个不同人的400张图像,是在1992年4月至1994年4月期间由英国剑桥的Olivetti研究实验室创建。
此数据集下包含40个目录,每个目录下有10张图像,每个目录表示一个不同的人。所有的图像是以PGM格式存储,每个图像都是是92x112x1像素、256级的灰度图。对每一个目录下的图像,这些图像是在不同的时间、不同的光照、不同的面部表情(睁眼/闭眼,微笑/不微笑)和面部细节(戴眼镜/不戴眼镜)环境下采集的。所有的图像是在较暗的均匀背景下拍摄的,拍摄的是正脸(有些带有略微的侧偏)。ORL人脸库部分图像如下:

4 人脸识别算法
4.1 基于PCA-最近邻的人脸识别算法
4.1.1 主成分分析PCA
PCA法是模式识别中的一种行之有效的特征提取方法。在人脸识别研究中,可以将该方法用于人脸图像的特征提取。
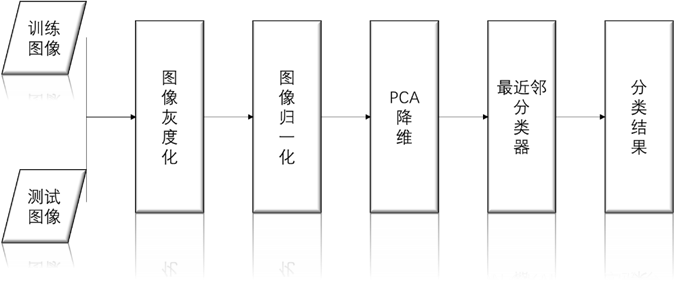
一个mn 的二维脸部图片将其按列首尾相连,可以看成是mn的一个一维向量。ORL人脸数据库中每张人脸图像大小是92×112,它可以看成是一个10304维的向量,也可以看成是一个10304维空间中一点。图像映射到这个巨大的空间后,由于人脸的构造相对来说比较接近,因此可以用一个相应的低维子空间来表示。我们把这个子空间叫做“脸空间”,我们对ORL数据库进行降维得到的特征脸如下:
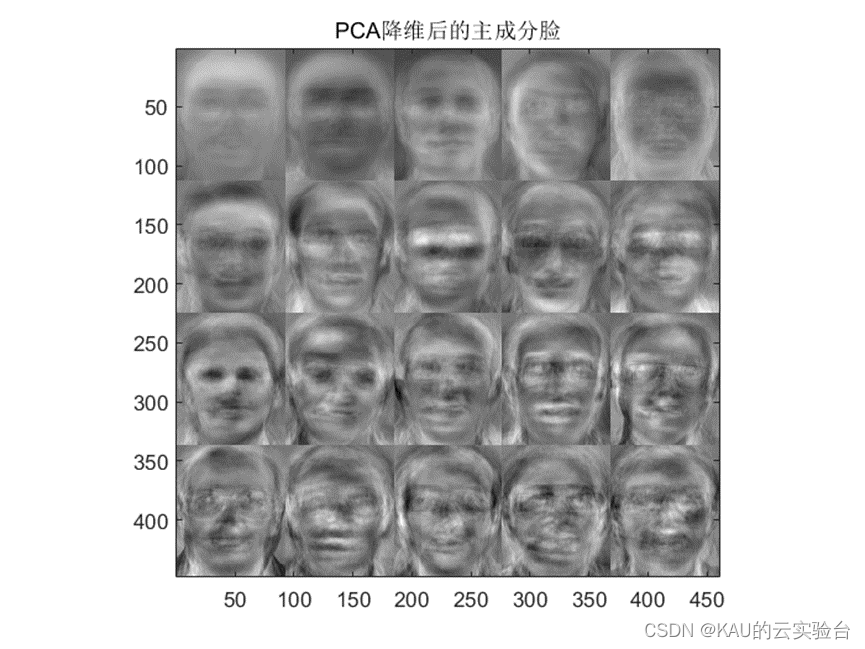
PCA的主要思想就是找到能够最好地说明图像在图像空间中的分布情况的那些向量,这些向量能够定义“脸空间”。 每个向量的长度为mn,描述一张mn的图像,并且是原始脸部图像的一个线性组合,称为“特征脸”。对于一副mn 的人脸图像,将其每列相连构成一个大小为D= mn维的列向量。D就是人脸图像的维数,也即图像空间的维数。设N是训练样本的数目;x,表示第j幅人脸图像形成的人脸向量;u为训练样本的平均图像向量,则所需样本的协方差矩阵为
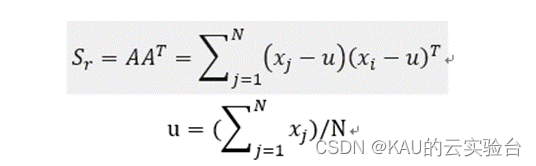
根据K-L变换原理,需要求得的新坐标系由矩阵AAT的非零特征值所对应的特征向量组成。直接计算的计算量比较大,所以采用奇异值分解(SVD)定理,来求解AAT的特征值和特征向量。依据SVD定理,令l.(i= 1 ,2,…,r)为矩阵AAT的r个非零特征值,v为AAT对应于4;的特征向量。由于特征值越大,与之对应的特征向量对图像识别的贡献越大,为此将特征值按大小排列,依照式;
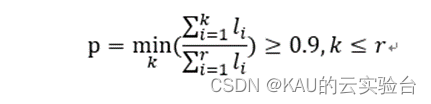
选取前p个特征值对应的特征向量,构成降维后的特征脸子空间。则AA^T的正交归一特征向量u,为
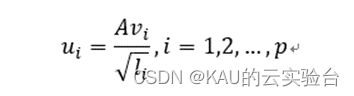
特征脸空间为
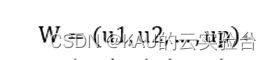
将训练样本y投影到“特征脸”空间W,得到一组投影向量Y =W^T y,构成人脸识别的训练样本数据库。
4.1.2 最近邻算法
m 维 空间中两点之间的实际距离,即是求两点间向量的 自然长度,即点到原点的距离。在三维空间以及二维空间中的距离就是空间两点之间的实际距离。将最近邻看作信号的相似程度,距离越短说明信号越相似。最近邻的计算公式为:
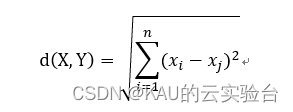
两幅图像之间的距离反映了图像的相似性,距离越近,图像的相似度越高。最近邻在数字图像处理中有着广泛的应用。将图像最近邻应 用于传统人脸识别算法,能提高人脸识别算法的效率。
在人脸识别系统 中,设有H个类别的训练样本。每类样本有L个参数,第i类样本可表示为Xi=(Xi1,Xi2,…,XiL)。对于任意测试样本X=(X1,X2,…,XL)由下式计算其距离:
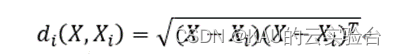
比较 X 到各类的距离,若满足:
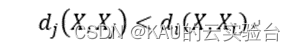
则判断X∈Xj
人脸分类识别器就是选择最小的距离作为最佳匹配的人脸的过程。采用最近邻法循环计 算测试样本与训练集里每类样本的距离,最终找出 与测试样本最近的训练集中的已知类别,并将其作 为判别输出。
4.2 基于PCA-SVM的人脸识别算法
4.2.1 主成分分析PCA
这部分与上一节相同,不再赘述。
4.2.2 SVM分类器
1、理论基础
分类器的工作分两步 :训练和测试。先对样本进行学习,将样本进行预判别,将提取的特征向量进行学习和分类,将类分好后,再将测试对象经过分类器即可将测试对象进行分类判别,对于本实验来说,也就实现了人脸的识别。传统的分类器只考虑对训练样本的拟合情况,以最小化训练集上的分类错误为目标,通过提供充足训练样本来提高分类器在测试集上的识别率。因此在训练样本有限的情况下,即在小训练样本时,传统分类器并不能保证有效的分类精度。支持向量机(Support Vector Machine, SVM)是一种二分类模型,最早由 Cortes和 Vapnik[57]在 1995 年提出。其求解目标在于确定一个分类的超平面,以最大化特征空间上的间隔。分类超平面的确定只取决于少数的样本信息,这些关键的样本被称之为支持向量 Support Vector,这也是 SVM—支持向量机名称的由来。
SVM 的分类思想是以结构化风险最小化为基础,兼顾训练误差与测试误差的最小化,具体体现在分类模型和模型参数的选择上。可以在小样本问题方面有效地保障分类精度。非线性 SVM(非性线支持向量机)的思路是 :寻找一个从低维到高维的映射空间,使得原来低维空间不易区分的特征,投射到高维度空间使其可分性更高。而在高维特征空间中求解支持向量机的超平面,投影回原低维空间时就呈现出一个非线性的曲面,因此称之为非线性支持向量机。非线性支持向量机的关键是如何从低维度映射到高维度,该映射关系被称为核函数,理论上需要满足 Mercer 定理(任何半正定的函数都可以作为核函数)。本文使用目前主流的 RBF(径向基核函数),即实现的是基于 RBF 的支持向量机分类器。
2、libsvm软件包简介
libsvm工具箱是**台湾大学林智仁(C.JLin)**等人开发的一套简单的,易于使用的SVM模式识别与回归机软件包(详情请见官方网址: http:/ / www.csie.ntu.edu.tw/ ~cjlin/libsvm/index.html,本书配套光盘中也有该工具箱及其安装说明的详细介绍),该软件包利用收敛性证明的成果改进算法,取得了很好的结果。libsvm共实现了5种类型的SVM;C - SVC,u -sVC,One Class - sVC,e-SVR和v-SVR等。下面将详细介绍libsvm 软件包中主要函数的调用格式及其注意事项。
2.1.SVM训练函数svmtrain
函数svmtrain用于创建一个SVM模型,其调用格式为
model = svmtrain(train _label,train_matrix, ’ libsvm _options’);
其中, train_label为训练集样本对应的类别标签; train_matrix为训练集样本的输入矩阵;
libsvm_options为SVM模型的参数及其取值(具体的参数,意义及其取值请参考libsvm 软件包的参数说明文档,此处不再赘述) ; model为训练好的SVM模型。值得一提的是,与BP神经网络及RBF神经网络不同, train_label及 train_matrix为列向量(矩阵),每行对应一个训练样本。
2.2.SVM预测函数svmpredict
函数svmpredict用于利用已建立的SVM模型进行仿真预测,其调用格式为
[predict _label,accuracy]= svmpredict(test _label,test_matrix, model);
其中, test_label为测试集样本对应的类别标签; test_matrix为测试集样本的输入矩阵;
model 为利用函数svmtrain训练好的SVM模型; predict_label为预测得到的测试集样本的类别标签; accuracy为测试集的分类正确率。
需要说明的是,若测试集样本对应的类别标签test_label未知,为了符合函数svmpredict调用格式的要求,随机填写即可,在这种情况下,accuracy便没有具体的意义了,只需关注预测的类别标签predict_label 即可。
3、训练SVM
在训练SVM时应考虑核函数及相关参数对模型性能的影响。本文采用默认的RBF核函数。首先利用交叉验证方法寻找最佳的参数c(惩罚因子)和参数g(RBF核函数中的方差),然后利用最佳的参数训练模型。值得一提的是,当模型的性能相同时,为了减少计算时间,优先选择惩罚因子c比较小的参数组合,这是因为惩罚因子c越大,最终得到的支持向量数将越多,计算量越大,经过训练后的SVM模型就可以直接用于人脸图像分类了。
4.3 基于卷积神经网络的人脸识别算法
人工智能领域研究的一个重要部分就是神经网络的研究,由于精确的准确度和良好的表现力,深度卷积神经网络已经是最流行的神经网络,它在多种领域的应用原理都可以总结为:从一些数据中自主学习事物特征,然后将学习成果向其他数据泛化。
4.3.1 卷积神经网络的组成
卷积神经网络主要有卷积层、激活函数、池化层、全连接层几种结构,将它们通过不同的方式连接起来,就可以拼接出一个常见的卷积神经网络。应用到图像处理的领域,经过卷积层的输出就是不同图像的特定特征空间,卷积层输出的特征空间即为全连接网络的输入,后者将会完成输入到数据标签的映射,在整个流程中,最重要的步骤是要在不断的训练数据迭代中达到调整网络权重的目的,神经网络预测的准确度基本都由其保证。目前常见的深层卷积网络基本都由上述结构连接组合、调整优化而来,例如 VGG 网络、残差网络等常见经典算法都由基础的卷积、池化等结构组合而来。
通用形式的神经网络如下图所示。这是一个“深度学习”神经网络,因为它具有多个内部层。
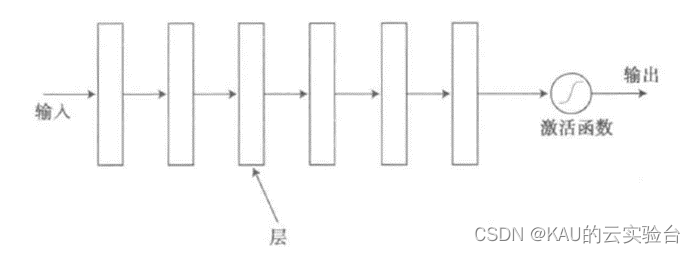
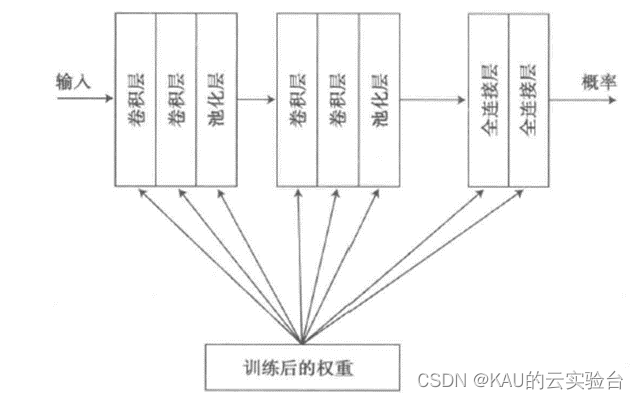
卷积神经网络是一种具有多个处理阶段的流水线方式的神经网络模型。在人脸识别的应用中,人脸图像从一端进入神经网络,然后图像是某人的概率值从另一端输出。卷积神经网络中有三种类型的层:
●卷积层(“卷积神经网络”的名称正是由此而来)
●池化层
●全连接层
卷积神经网络的结构如下图所示。这也是一个“深度学习”神经网络,因为它同样包含多个内部层,但现在这些内部层具有上面描述的三种类型之一。
可以在神经网络中设置任意多数目的中间层。神经网络中的神经元可以用下式来表示
y=σ(wx+b)
其中,w是权重,b是偏置,σ()是对神经元输入wx + b进行计算的非线性函数,也就是激活函数。激活函数有多种可选形式,通常使用S形或双曲正切作为激活函数
4.3.2 设计CNN网络结构
MATLAB提供了丰富的卷积网络设计函数,并支持通过交互界面 deepNetworkDesigner进行拖拽式设计,使得我们可以像搭建积木一样进行网络搭建。

为了快速进行简单的网络设计,这里直接利用网络层函数进行组合搭建,本文所搭建的CNN结构如下:

其余参数的设置如下:

4.3.3 网络训练
通过matlab的trainNetwork()对自定义的CNN网络进行训练,训练结果如下:
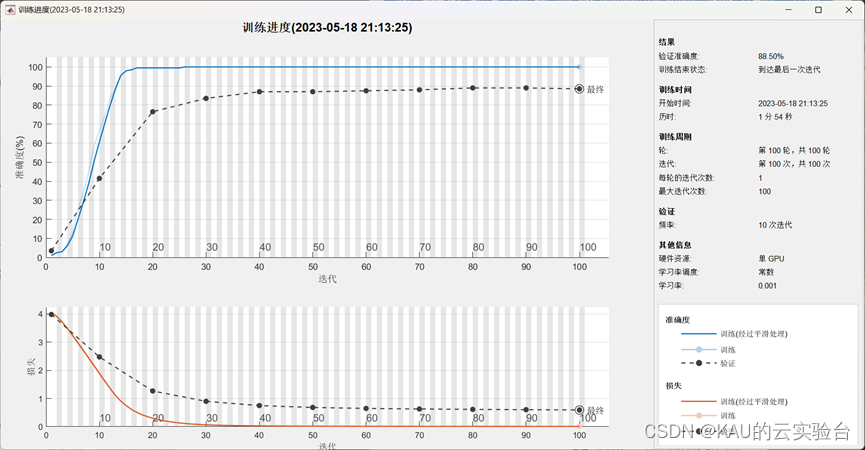
可以发现,随着训练迭代步数的增加,准确率曲线呈现明显的上升趋势,Loss曲线呈现明显的下降趋势,这也说明了网络模型的有效性。在相同的硬件条件下,自定义CNN 的最后识别率在88%左右,训练耗时1分54秒。
05 系统实现
可关注作者公主号查找相关内容获取源码:KAU的云实验台
本文利用MATLAB GUI将3种人脸识别算法集成,设计出如下的人脸识别系统:
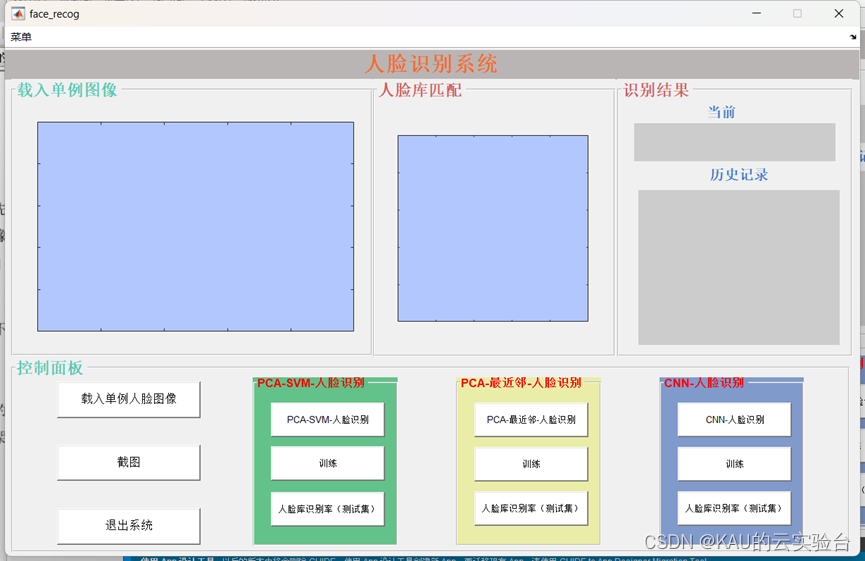
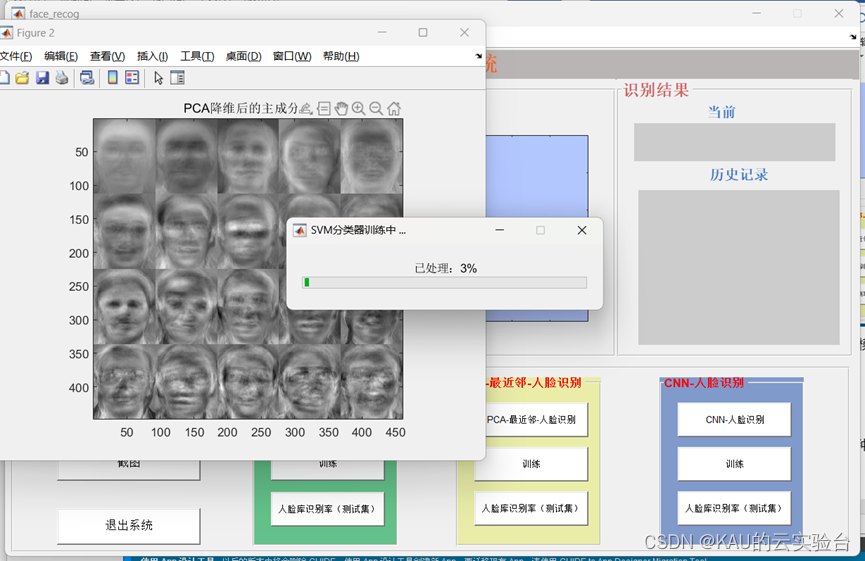
首次使用时,先依次点击三个算法的“训练“,得到对应模型和数据,
如:PCA-SVM
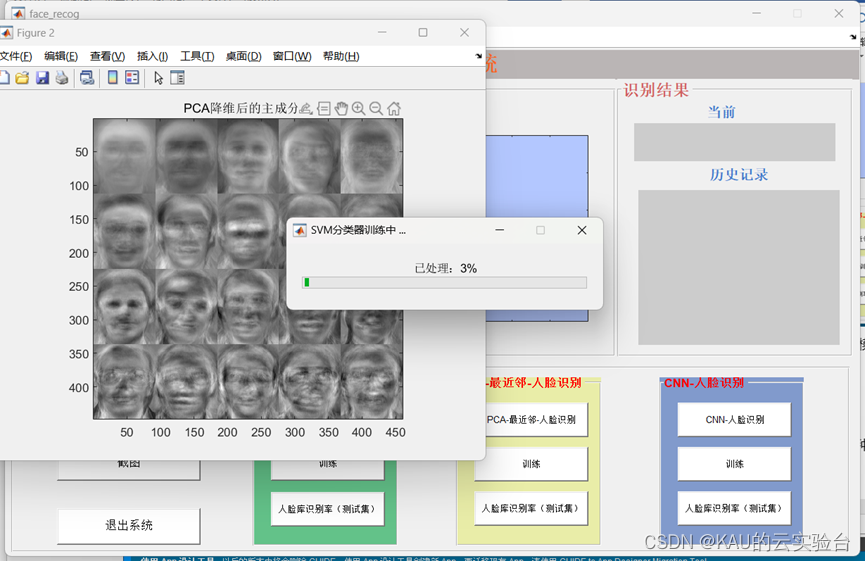
训练完成后会有相应结果显示:
完成训练后,就可以点击各算法的人脸库识别率或点击载入单例人脸图像进行识别。
在“历史记录“栏中,总共可显示10条识别记录。
注意,该系统因为会用到深度学习工具箱,所以对版本有要求,作者的是2020a。
06 展望
本文实现的功能只是人脸识别的功能,在完整的人脸识别流程中,还包括人脸检测部分,如果涉及遮挡、姿态变换等,那么识别的方法可能仍需要调整,这也是作者往后将改进的方向,欢迎持续关注~
参考文献
[1] Bonnen K, Klare B F, Jain A K.Component-based representation in automated face recognition[J].IEEE Transactions on Information Forensics & Security, 2013, 8(1): 239-253.
[2]孙伟杰. 基于特征学习的人脸识别研究[D].杭州电子科技大学,2022.DOI:10.27075/d.cnki.ghzdc.2022.000617.