作者:liuz_notes
来源:CSDN
原文:https://blog.csdn.net/liuz_notes/article/details/99228814
版权声明:本文为博主原创文章,转载请附上博文链接!
目录
0 写在前面
本博客为博主阅读完Michael Nielsen的《Neural Networks and Deep Learning》后所摘录的知识骨架,和相关笔记。作为我自己学习深度学习的入门书籍,比较推荐这本书,有需要电子版书籍和随书代码的兄dei可以在博客留下自己的邮箱,或根据本博客的参考部分自行下载。话不多说,进入正题!
1 感知机
作为人工神经元的基本单元,它根据权重与输入的乘积、阈值输出0或1。(阈值移到方程左边就变成了偏置)。


2 神经网络的架构
输入层、输出层、隐藏层(输入与输出之间的神经元,层数非常多时称为深度神经网络)

3 反向传播算法
Core: ,

该神经元的激活值是由上一层所有神经元的激活值乘以到该神经元的权重的和,再加上该神经元自身的偏置,作为激活函数的输入所得到的。(该输入称为带权输入 )。
3.1 反向传播的四个基本方程(利用链式求导法则证明)
称为在第 层第 个神经元上的误差。
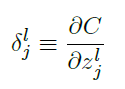
反向传播将给出计算误差 的流程,然后将其关联到计算 和 上。

3.2 反向传播算法流程(反向传播误差得以修正权重和偏置)

3.3 梯度下降学习算法流程

更新的权重和偏置影响输出层激活函数的输出值,从而导致代价函数输出的变化。代价函数只是输出激活函数值的函数,目标输出值为常量。

4 改进神经网络的方法
4.1 代价函数的选择
二次代价函数的定义及其偏导:


交叉熵代价函数的定义及其偏导:

柔性最大值函数的定义及其偏导:
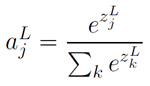
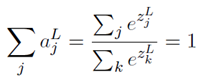

结果:避免了⼆次代价函数中 项导致的学习缓慢。
4.2 四种正则化技术
-
L2正则化:在代价函数中加上正则化项

可以称为正则化参数,正则化项里并不包含偏置。 -
L1正则化:在未正则化的代价函数上加上⼀个权重绝对值的和

惩罚大的权重,倾向于让网络优先选择小的权重。
在L2正则化中,权重通过⼀个和 成⽐例的量进⾏缩小的。L1正则化倾向于聚集⽹络的权重在相对少量的⾼重要度连接上,而其他权重就会被驱使向0接近。 -
弃权
随机(临时)地删除⽹络中的⼀半的隐藏神经元开始,同时让输⼊层和输出层的神经元保持不变。⾸先重置弃权的神经元,然后选择⼀个新的随机的隐藏神经元的⼦集进⾏删除,估计对⼀个不同的小批量数据的梯度,然后更新权重和偏置。

弃权过程就如同⼤量不同⽹络的效果的平均那样。不同的⽹络会以不同的⽅式过拟合了,所以,弃权过的⽹络的效果会减轻过拟合。 -
⼈为扩展训练数据
通过对数据加噪声等操作扩展训练数据,做一个数据增强的工作。
4.3 权重初始化方法
不是简单用 高斯分布初始化权重输入。假设我们有 个输入权重的神经元,我们会使用 的高斯分布初始化这些权重。
4.4 启发式地超参数选择方法
正则化参数 :先不用正则化来确定 的值,尝试从 开始调整。
学习速率 :选择在训练数据上的代价⽴即开始下降而⾮震荡或者增加时作为 的阈值的估计。
小批量数据(minibatch)大小:选择最好的小批量数据⼤小也是⼀种折衷。太小了,你不会⽤上很好的矩阵库的快速计算。太⼤,你是不能够⾜够频繁地更新权重的。你所需要的是选择⼀个折衷的值,可以最⼤化学习的速度。
迭代期数量(epoch):依据分类准确率不再提升,提前停止训练。
4.5 其他技术
1、随机梯度下降的变化形式:如Hessian技术、momentum技术。
2、优化代价函数的方法。
3、其他的激活函数:如双曲正切函数、修正线性神经元(ReLU)
5 为什么神经网络难以训练
梯度的消失、梯度的激增、深度神经网络中的梯度不稳定性


该导数在
时达到最高,我们发现会有
,并且在我们进⾏了所有这些项的乘积时,最终结果肯定会指数级下降:项越多,乘积的下降的越快。从而,我们能理解为什么梯度会消失。

如果权重在训练中增长,项变得超过1,那么我们将不再遇到消失的梯度问题。实际上,这时候梯度会在我们反向传播的时候发⽣指数级地增⻓。也就是说,我们遇到了梯度激增的问题。
真实的问题就是神经⽹络受限于不稳定梯度的问题。所以,如果我们使⽤标准的基于梯度的学习算法,在⽹络中的不同层会出现按照不同学习速度学习的情况。
总结:结果表明了激活函数的选择,权重的初始化,甚⾄是学习算法的实现⽅式也扮演了重要的⻆⾊。当然,⽹络结构和其他超参数本⾝也是很重要的。因此,太多因⼦影响了训练神经⽹络的难度,理解所有这些因⼦仍然是当前研究的重点。
6 卷积神经网络
将输入看作一个二维方阵神经元,使用这个架构使得卷积网络能更快训练,非常擅长于进行图像处理。卷积神经⽹络采⽤了三种基本概念:局部感受野,共享权重,和池化。
6.1 局部感受野
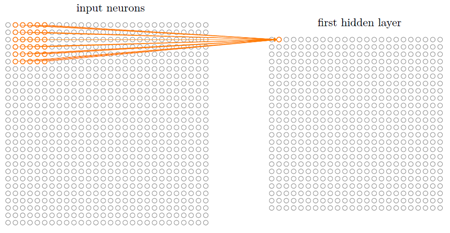
把输⼊像素连接到⼀个隐藏神经元层。但是我们不会把每个输⼊像素连接到每个隐藏神经元。相反,我们只是把输⼊图像进⾏小的,局部区域的连接。
说的确切⼀点,第⼀个隐藏层中的每个神经元会连接到⼀个输⼊神经元的⼀个小区域,例如,⼀个5X5的区域,对应于25个输⼊像素。所以对于⼀个特定的隐藏神经元,我们可能有看起来像这样的连接:

它是输⼊像素上的⼀个小窗口。每个连接学习⼀个权重。而隐藏神经元同时也学习⼀个总的偏置。

6.2 共享权重和偏置
每个隐藏神经元具有⼀个偏置和连接到它的局部感受野5X5的权重,对下一层隐藏神经元中的每⼀个使⽤相同的权重和偏置。这意味着第⼀个隐藏层的所有神经元检测完全相同的特征,只是在输⼊图像的不同位置。
因为这个原因,我们有时候把从输⼊层到隐藏层的映射称为⼀个特征映射。我们把定义特征映射的权重称为共享权重。我们把以这种⽅式定义特征映射的偏置称为共享偏置。共享权重和偏置经常被称为⼀个卷积核或者滤波器。
为了完成图像识别我们需要超过⼀个的特征映射,所以⼀个完整的卷积层由⼏个不同的特征映射组成:

下面,我们看一个具体的例子:

这20 幅图像对应于20 个不同的特征映射(或滤波器、核)。每个映射有⼀幅5X5块的图像表⽰,对应于局部感受野中的5X5权重。⽩⾊块意味着⼀个小(典型的,更小的负数)权重,所以这样的特征映射对相应的输⼊像素有更小的响应。更暗的块意味着⼀个更⼤的权重,所以这样的特征映射对相应的输⼊像素有更⼤的响应。⾮常粗略地讲,上⾯的图像显⽰了卷积层作出响应的特征类型。
共享权重和偏置的⼀个很⼤的优点是,它⼤⼤减少了参与的卷积⽹络的参数。对于每个特征映射我们需要25=5X5个共享权重,加上⼀个共享偏置。所以每个特征映射需要26个参数。如果我们有20个特征映射,那么总共有20X26=520个参数来定义卷积层。
6.3 池化
除了刚刚描述的卷积层,卷积神经⽹络也包含池化层(pooling layers)。池化层通常紧接着在卷积层之后使⽤。它要做的是简化从卷积层输出的信息。
详细地说,⼀个池化层取得从卷积层输出的每⼀个特征映射并且从它们准备⼀个凝缩的特征映射。例如,池化层的每个单元可能概括了前⼀层的⼀个(⽐如)2X2的区域。作为⼀个具体的例⼦,⼀个常⻅的池化的程序被称为最⼤值混合(max-pooling)。在最⼤值池化中,⼀个池化单元简单地输出其2X2输⼊区域的最⼤激活值。

我们将最⼤值池化分别应⽤于每⼀个特征映射:

最⼤值池化并不是⽤于池化的仅有的技术。另⼀个常⽤的⽅法是L2池化。这⾥我们取2X2区域中激活值的平⽅和的平⽅根,而不是最⼤激活值。
一个完整的基础网络架构如下:

7 结语
本书主要介绍了神经网络的基本原理,重点在反向传播算法的推导和理解,并通过NMIST数据给出训练Demo。在介绍改进神经网络性能的方法部分一直通过Demo进行实例分析,给出了提升神经网络性能的一般方法及启发探索方式。其中一章还专门通过可视化来证明神将网络可以用来拟合任何函数,无论是狭义上的函数还是广义上的函数。然后说明了神经网络之所以难以训练的重要原因在于其梯度的不稳定性,当然也与网络结构和超参数有关。最后迈向深度学习,介绍了CNN的基础、代码实现,以及CV领域利用CNN开展的研究。
作为深度学习的初学者,我觉得这本书还是可以的,比较详细、系统地介绍了神经网络的基础——梯度下降反向传播算法,还有代码实战,能很快的上手。同时,本书还给出了很多神经网络与深度学习的辩证思考,以及未来发展的前景和趋势,给了我很多启发,特别是对于我这样一个刚接触这个领域的小白来说。“知识结构形成了科学的社会组织关系。但这些社会关系反过来也会限制和帮助决定那些可以发现的事物。”目前该领域在不断的被细分和革新,距离像医学、物理学、数学、化学一样成熟的系统和体系还有很长一段路要走,所以现在开始踏入这个领域还不算太晚,有足够大的空间自由发挥、研究。这是令⼈兴奋异常的创造新事物的机遇!
参考
- Nielsen M A. Neural networks and deep learning[M]. San Francisco,
CA, USA:: Determination press, 2015. - http://neuralnetworksanddeeplearning.com/index.html
- https://github.com/nndl/nndl.github.io
