第三章 优化神经网络的学习过程
作者: Michael Nielsen
为什么正则化可以减少过拟合现象
假设现在有这样一个例子:
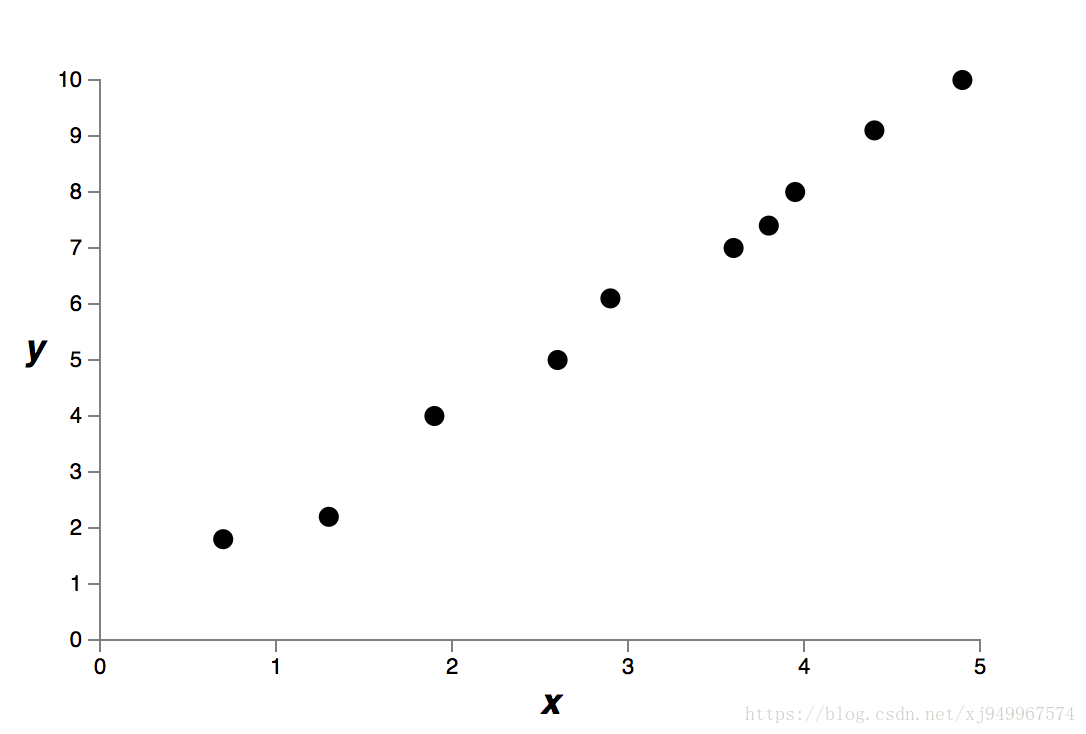
现在需要找一个适当的多项式函数来拟合它,文章中给出了两个选择:
一个是九次多项式
另一个线性的
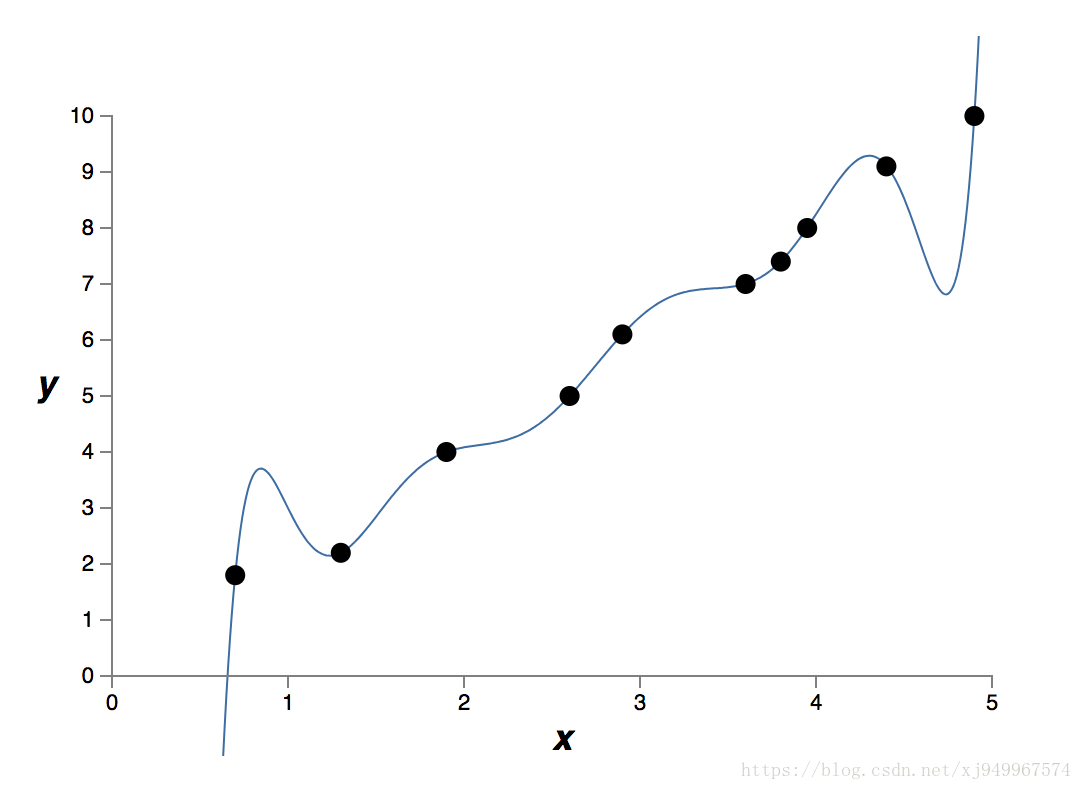
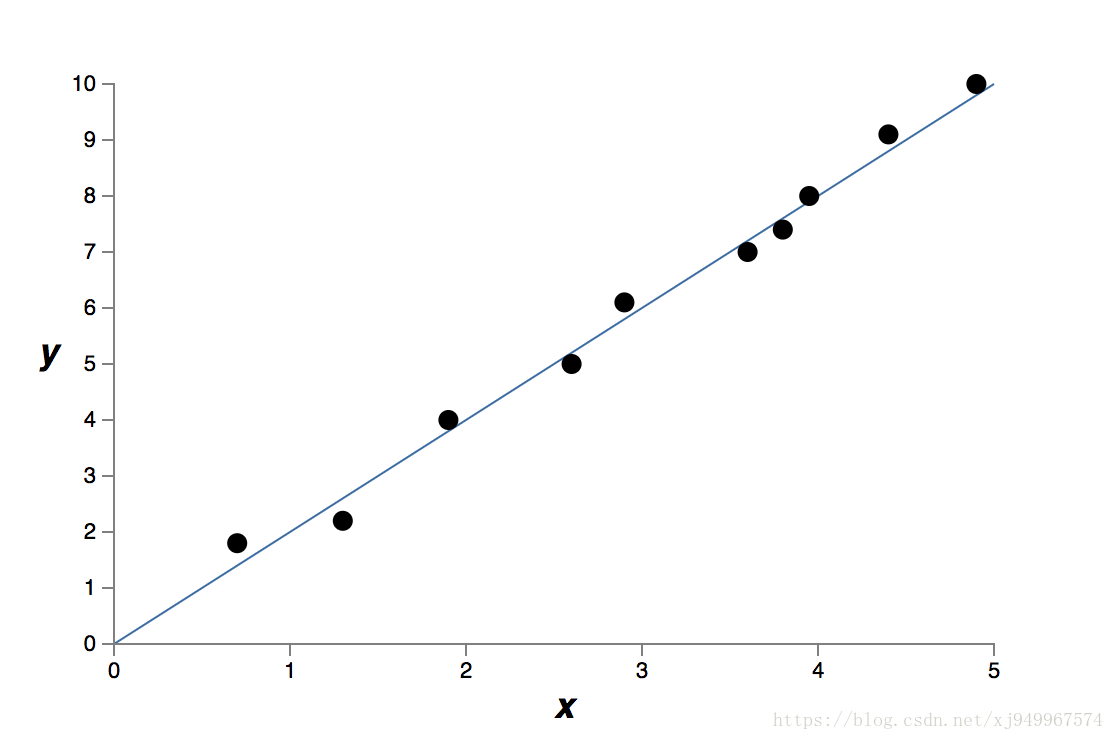
可以看到第一个图像很好地拟合了数据点,第二个图像只是较好地拟合了数据点,其中还有一些可能是测量误差引起的噪声。
回到这一节的问题,加入正则化项,意味着神经网络将避免一些权值较大的影响因素。权值大的结果就是网络容易因为一些小噪声从而产生巨大的变化,这是我们不愿意看到的。在这个例子中,我们更愿意相信
的结果是正确的,因为它对于噪声并不敏感,拥有较好的泛化能力。对于同一个问题,人们更倾向于较简单的形式,这也被称为“奥卡姆剃刀“准则,但是这也不是绝对的,有相当多的情况,更复杂的形式反而是正确的,如同相对论对于万有引力定律的修正一样。
本节的结论是,在任何情况下都应该考虑正则化项,这将使我们的神经网络表现得更好。
其他的正则化方法
L1正则化
从而,它的权值更新方式为:
将之于L2正则化方式相比较,可以看出,它更新权值时每次都是减去一个固定值,而L2正则化时减少的数目是于w有关的。所以L1正则化会使得网络中留下重要的连接,其他的权值会趋于0。
Dropout
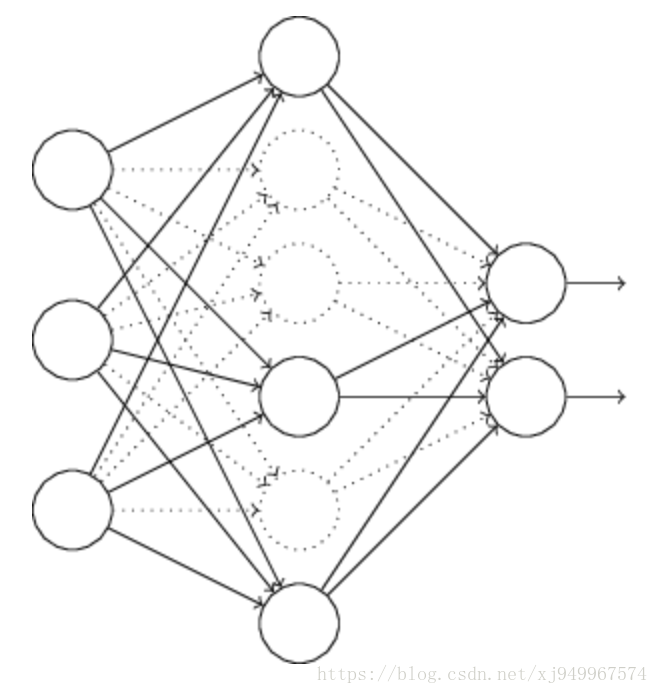
在训练网络之前,我们随机地在网络中去除掉一半的神经元,然后再正常地开始训练,更新权值。一轮训练结束后,我们恢复那些被去除的神经元,随后再次随机地去除一半的神经元,继续训练。当我们需要使用整个网络训练时,我们需要将隐层的输出处以2,因为之前训练时每次都只使用一半的网络。这样做有效的原因是,我们去除一半的网络,等于使用了多个不同的网络来进行训练,多次训练下来结果一平均就可以在一定程度上消除过拟合带来的负面效果。
人为扩展训练集
从各项实验我们可以知道,拥有更多的训练数据可以使得神经网络的训练效果更好,但是现实是我们的训练数据量是有限的,所以我们需要人为地扩展数据集。例如在MNIST中,对于手写数字,我们可以对数字进行小幅度的旋转,放大缩小,然后把它们加入到训练集中,这样也可以减少过拟合对于网络性能的影响。还有在语音识别的任务中,我们同样可以在训练样本中人为加入噪声,提升辨识系统的鲁棒性。