由于本人知识有限,如有写错的地方,还请谅解并指出,谢谢!
1、梯度下降
预备知识
目标函数:f(x) = w*x+b ,在给定的训练集中有(X,Y),X为输入参数,Y为输出结果。我们需要找到一组w和b,使的w*x+b 的值接近Y,并且误差最小,那么f(x) = w*x+b 就是目标函数。根据已知的参数w和b,可以求的目标函数的值为多少。
损失函数:训练得到的结果与实际结果的误差。在训练中,我们是需要不断的调整参数w和b的值,使的结果更好,误差尽可能的小。一开始我们有初始值参数w和b,然后根据损失情况不断调整参数w和b。在已知输入参数x情况下,我们可得f(x) = w*x+b ,我们要使的损失函数L(Y, f(X)) = (Y - f(X))2尽可能的小就行,当然也不能太小了,不然会过拟合,也不能太大了,否则就会欠拟合。也有一些其他的损失函数,这里提到的是平方损失(Square Loss)。
1.1 损失函数可视化
在线性回归中,参数w常常是高维的,那么直接可视化就不太可能,我们需要将它投射到一维或二维上,才方便可视化。以一维线性回归为例,y = w1x1+b1。损失函数可能为如下图所示:
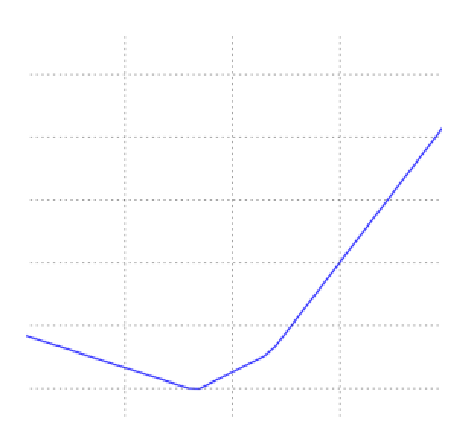
如果有两个维度,损失函数可能入下两图所示:
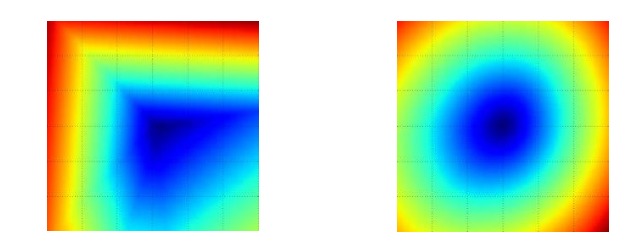
蓝色越深表示损失函数越低,红色越深表示损失函数越高。
1.2 最优化
但损失函数是凸函数时,能得到全局最低点,如果是一个非凸函数,那么进行梯度下降时得到的可能是局部最小点,而不是全局最小点。
1.3 梯度下降
2、反向传播
2.1 梯度与偏导
2.2 链式法则
2.3 直观理解
2.4 Sigmod例子