目录
1.梯度是什么?
梯度:是一个向量,导数+变化最快的方向(学习的前进方向)
回顾机器学习
收集数据x,构建机器学习模型f,得到
判断模型好坏的方法:
(回归损失)
(分类损失)
目标:通过调整(学习)参数w,尽可能的降低loss,那么我们该如何调整w呢?

随机选择一个起始点wo,通过调整wo,让loss函数取到最小值

w的更新方法
1.计算w的梯度(导数)
2.更新w
其中:
1.意味着w将增大
2.意味着w将减小
总结:梯度就是多元函数参数的变化趋势(参数学习的方向),只有一个自变量时称为导数
2. 偏导数的计算
2.1 常见的导数计算

2.2 多元函数求偏导
一元函数,即有一个自变呈。
类似f(a)多元函数,即有多个自变呈。
类似f(t,y,2),三个自变量t,y,2多元函数求偏导过程中:对某一个自变量求导,其他自变量当做常量即可

3. 反向传播算法
3.1 计算图和反向传播
计算图:通过图的方式来描述函数的图形
在上面的练习中,J(a,b,c)=3(a+bc),令u=a+v,v=bc,把它绘制成计算图可以表示为:

绘制成为计算图之后,可以清楚的看到向前计算的过程之后,对每个节点求偏导可有:

那么反向传播的过程就是一个上图的从右往左的过程,自变量a,b,c各自的偏导就是连线上的梯度的乘积:
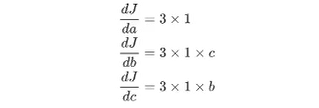
3.2 神经网络中的反向传播
3.2.1神经网络的示意图
wl,w2,....wn表示网绛第n层权重
w_n[i,j]表示第n层第i个神经元,连接到第n+1层第i个神经元的权重

3.2.2神经网络的计算图

其中
1.out是根据损失函数对预测值进行求导得到的结果
2.函数可以理解为激活函数
问题:那么此时w1[1,2]的偏导该如何求解呢?
通过观察,发现从out到w[1,2]的来连接线有两条

结果如下:

公式分为两部分:
1.括号外:左边红线部分
2.括号内
1.加号左边:右边红线部分
2.加号右边:蓝线部分
但是这样做,当机型很大的时候,计算量非常大。所以反向传播的思想就是对其中的某一个参数单独求梯度,之后更新,如下图所示!

计算过程如下:

继续反向传播

计算过程如下:
![]()
通用的描述如下:

4. 前向计算
对于pytorch中的一个tensor,如果设置它的属性 requires_grad为True,那么它将会追踪对于该张量的所有操作。或者可以理解为,这个tensor是一个参数,后续会被计算梯度,更新该参数。
4.1 计算过程
假设有以下条件(1/4 表示求均值,Xi中有4个数),使用torch是完成其向前计算的过程

如果x为参数,需要对其进行梯度的计算和更新
那么,在最开始随机设置x的值的过程中,需要设置他的requires_grad属性为True,其默认值为False
import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)
'''
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
'''
y = x + 2
print(y)
'''
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
'''
z = y * y * 3
print(z)
'''
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>)
'''
out = z.mean()
print(out)
'''
tensor(27., grad_fn=<MeanBackward0>)
''' 从上述代码可以看出:
1.x的requires grad属性为True
2之后的每次计算都会修改其grad_fn 属性,用来记录做过的提作
通过这个函数和grad fn能够组成一个和前一小节类似的计算图
4.2 requires_grad和grad_in
a = torch.randn(2, 2)
a = ((a * 3) / (a - 1))
print(a.requires_grad)
'''False'''
a.requires_grad_(True)
print(a.requires_grad)
'''True'''
b = (a * a).sum()
print(b.grad_fn)
'''<SumBackward0 object at 0x0000027BF85D96D0>'''
with torch.no_grad():
c = (a * a).sum()
print(c.requires_grad)
'''False'''注意:
为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch,no_grad():中。在评估模型时特别有用,因为横型可能具有requires_grad = True 的可训练的参效,但是我们不需要在此过程中对他们进行梯度计算。
5. 梯度计算
对于前向计算中的out而言,我们可以使用backward方法来进行反向传播,计算梯度out.backward(),此时便能够求出导数调用x.gard能够获取导数值
得到
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])因为:
在等于1时,其值为4.5。
注意:
在输出为一个标量的情况下,我们可以调用输出tensor的backword()方法,但是在数据是一个向量的时候,调用backward()的时候还需要传入其他参数。
很多时候我们的损失函数都是一个标量,所以这里就不再介绍损失为向量的情况。
loss.backward()就是根损失函数,对参数(requires_grad=True)的去计算他的梯度,并且把它累加保存到x.gard,此时还并未更新其梯度。
注意点:
1. tensor.data:
- 在tensor的require_grad=False,tensor.data和tensor等价。
- require_grad=True时,tensor.data仅仅是获取tensor中的数据,不带属性
2. tensor.numpy():
- require_grad=True不能够直接转换,需要使用tensor.detach().numpy() 能够实现对tensor中的数据进行深拷贝,转换为ndarray类型。
相关推荐: