Topic:
尝试加载一个真实数据集,并使用 scikit-learn 构建预测模型,实现多项式回归预测
以世界麻疹疫苗接种率
基础篇详看:多项式回归
步骤:
- 加载数据集
- 定义训练和测试使用的自变量和因变量
- 建立线性回归模型
- 线性回归误差计算
- 多项式回归预测次数选择
MSE
# 1. 下载数据集
# !wget http://labfile.oss.aliyuncs.com/courses/1081/course-6-vaccine.csv
# 2. 用 Pandas 加载数据集
import pandas as pd
df = pd.read_csv("course-6-vaccine.csv", header=0)
df
# 3. 绘制图像
from matplotlib import pyplot as plt
# 从原数据集中分离出需要的数据集(DataFrame)
x = df['Year']
y = df['Values']
# 绘图
plt.plot(x, y, 'r')
plt.scatter(x, y)
# 4. 训练集和测试集划分
# 首先划分 dateframe 为训练集和测试集
train_df = df[:int(len(df)*0.7)]
test_df = df[int(len(df)*0.7):]
# 定义训练和测试使用的自变量和因变量
train_x = train_df['Year'].values
train_y = train_df['Values'].values
test_x = test_df['Year'].values
test_y = test_df['Values'].values
# 5. 线性回归预测
# 建立线性回归模型
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(train_x.reshape(len(train_x),1), train_y.reshape(len(train_y),1))
results = model.predict(test_x.reshape(len(test_x),1))
results # 线性回归模型在测试集上的预测结果
# 6. 线性回归误差计算
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
print("线性回归平均绝对误差: ", mean_absolute_error(test_y, results.flatten()))
print("线性回归均方误差: ", mean_squared_error(test_y, results.flatten()))
# 7. 二次多项式预测
from sklearn.preprocessing import PolynomialFeatures
# 2 次多项式回归特征矩阵
poly_features_2 = PolynomialFeatures(degree=2, include_bias=False)
poly_train_x_2 = poly_features_2.fit_transform(train_x.reshape(len(train_x),1))
poly_test_x_2 = poly_features_2.fit_transform(test_x.reshape(len(test_x),1))
# 2 次多项式回归模型训练与预测
model = LinearRegression()
model.fit(poly_train_x_2, train_y.reshape(len(train_x),1)) # 训练模型
results_2 = model.predict(poly_test_x_2) # 预测结果
results_2.flatten() # 打印扁平化后的预测结果
print("2 次多项式回归平均绝对误差: ", mean_absolute_error(test_y, results_2.flatten()))
print("2 次多项式均方根误差: ", mean_squared_error(test_y, results_2.flatten()))
# 8. 更高次多项式回归预测
from sklearn.pipeline import make_pipeline
train_x = train_x.reshape(len(train_x),1)
test_x = test_x.reshape(len(test_x),1)
train_y = train_y.reshape(len(train_y),1)
for m in [3, 4, 5]:
model = make_pipeline(PolynomialFeatures(m, include_bias=False), LinearRegression())
model.fit(train_x, train_y)
pre_y = model.predict(test_x)
print("{} 次多项式回归平均绝对误差: ".format(m), mean_absolute_error(test_y, pre_y.flatten()))
print("{} 次多项式均方根误差: ".format(m), mean_squared_error(test_y, pre_y.flatten()))
print("---")
# 9. 多项式回归预测次数选择
# 计算 m 次多项式回归预测结果的 MSE 评价指标并绘图
mse = [] # 用于存储各最高次多项式 MSE 值
m = 1 # 初始 m 值
m_max = 10 # 设定最高次数
while m <= m_max:
model = make_pipeline(PolynomialFeatures(m, include_bias=False), LinearRegression())
model.fit(train_x, train_y) # 训练模型
pre_y = model.predict(test_x) # 测试模型
mse.append(mean_squared_error(test_y, pre_y.flatten())) # 计算 MSE
m = m + 1
print("MSE 计算结果: ", mse)
# 绘图
plt.plot([i for i in range(1, m_max + 1)], mse, 'r')
plt.scatter([i for i in range(1, m_max + 1)], mse)
# 绘制图名称等
plt.title("MSE of m degree of polynomial regression")
plt.xlabel("m")
plt.ylabel("MSE")
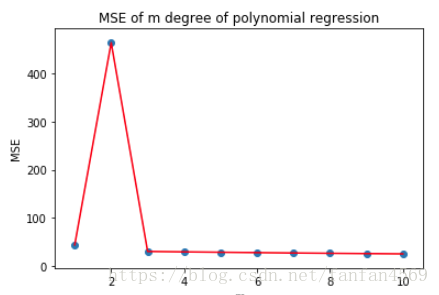
如上图所示,MSE 值在 2 次多项式回归预测时达到最高点,之后迅速下降。而 3 次之后的结果虽然依旧呈现逐步下降的趋势,但趋于平稳。一般情况下,我们考虑到模型的泛化能力,避免出现过拟合,这里就可以选择 3 次多项式为最优回归预测模型。