简介
使用许多互联网数据,我们都可以构建出这样的网络,其节点为某一种信息资源,如图片,视频,帖子,新闻等,连边为用户在资源之间的流动。对于这样的网络,使用社区划分算法可以揭示信息资源之间的相关性,这种相关性的发现利用了用户对信息资源的处理信息,因此比起单纯使用资源本身携带的信息来聚类(例如,使用新闻包含的关键词对新闻资源进行聚类),是一种更深刻的知识发现。
网络社区划分的两种主要思路
社区划分的算法比较多,大致可以分为两大类:拓扑分析和流分析。前者一般适用于无向无权网络,思路是社区内部的连边密度要高于社区间。后者适用于有向有权网络,思路是发现在网络的某种流动(物质、能量、信息)中形成的社区结构。这两种分析各有特点,具体应用取决于网络数据本身描述的对象和研究者想要获得的信息。
我们可以将已知的一些算法归入这两类:
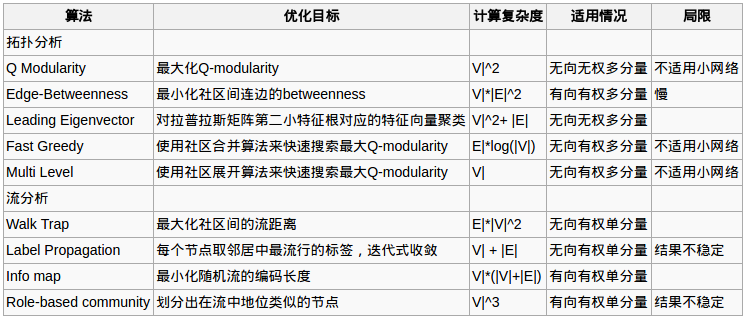
拓扑分析
计算网络的模块化程度Q-Modularity
Q-Modularity是一个定义在[-0.5,1)区间内的指标,其算法是对于某一种社区结构,考虑每个社区内连边数与期待值之差。实际连边越是高于随机期望,说明节点越有集中在某些社区内的趋势,即网络的模块化结构越明显。Newman在2004年提出这个概念最初是为了对他自己设计的社区划算法进行评估,但因为这个指标科学合理,而且弥补了这个方面的空白,迅速成为一般性的社区划分算法的通用标准。 Q的具体计算公式如下:
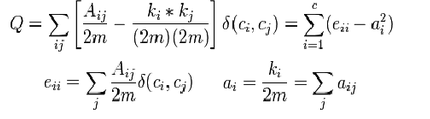
其中A是网络G对应的邻接矩阵,如果从i到j存在边,则Aij=1,否则为0。m是总连接数,2m是总度数,Aij/2m是两节点之间连接的实际概率。Ki和kj分别是i和j的度数。如果我们保持一个网络的度分布但对其连边进行随机洗牌,任意一对节点在洗牌后存在连接的概率为kikj/(2m)2。上式中中括号表达的就是节点之间的实际连边概率高于期待值的程度。后面跟着一个二元函数,如果节点ij属于同一个社区,则为1,否则为0,这就保证了我们只考虑社区内部的连边。刚才这个定义是以节点为分析单位。实际上,如果以社区为分析单位看Q指标,可以进一步将其化简为eii和ai之间的差。其中eii是在第i个社区内部的link占网络总link的比例,ai是第i个社区和所有其他社区的社区间link数。
上式已经清楚定义了Q,但在实际计算里,上式要求对社区及其内部节点进行遍历,这个计算复杂度是很大的。Newman(2006)对上式进行了化简,得到矩阵表达如下: 我们定义Sir为n * r的矩阵,n是节点数,r是社区数。如果节点i属于社区r,则为1,否则为0。
于是有
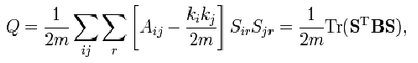
其中B是modularity matrix,其元素为
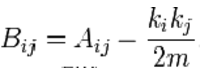
该矩阵的行列和都是0,因为实际网络和随机洗牌后的网络度分布是不变的。特别地,在仅仅有两个社区的情况下(r=2),可以s定义为一个n长的向量,节点属于一个社区为1,属于另一个社区为-1,Q可以写成一个更简单的形式:
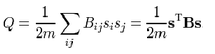
通过对社区的划分可能空间进行搜索,可以得到最大化Q值的社区划分。在这个过程会涉及数值优化的部分,例如表一中的fast greedy和multilevel就是用不同方法进行快速搜索的例子。以fast greedy为例Newman(2006),它通过不断合并社区来观察Q的增加趋势,得到了一个在最差的情况下复杂度约为O( |E|*log(|V|) ),在最好的情况下接近线性复杂度的算法。
计算网络的连边紧密度Edge betweenness
这个思路出现得比较早(Newman, 2001)。Freeman (1975) 提出过一个叫betweenness的指标,它衡量的是网络里一个节点占据其他n-1节点间捷径的程度。具体而言,首先对每一对节点寻找最短路径,得到一个n * (n-1)/2的最短路径集合S,然后看这个集合中有多少最短路径需要通过某个具体的节点。Newman借鉴了这个标准,但不是用来分析节点而是分析连边。一个连边的edge betweenness就是S集合里的最短路径包含该连边的个数。 定义了连边的betweenness后,就可以通过迭代算法来进行社区划分了。具体做法是先计算所有连边的betweenness,然后去除最高值连边,再重新计算,再去除最高值连边,如此反复,直到网络中的所有连边都被移除。在这个过程中网络就逐渐被切成一个个越来越小的component。在这个过程中,我们同样可以用Q-modularity来衡量社区划分的结果。这种算法定义比较清晰,也不涉及矩阵数学等运算,但问题是计算复杂度比较大。
计算网络拉普拉斯矩阵的特征向量Leading eigenvector
一个有n个节点的网络G可以被表达为一个n x n的邻接矩阵(adjacency matrix)A。在这个矩阵上,如果节点i和j之间存在连边,则Aij=1,否则为0。当网络是无向的时候,Aij=Aji。另外我们可以构造n x n的度矩阵(degree matrix)D。D对角线上的元素即节点度数,例如Dii为节点i的度数,所有非对角线的元素都是0。无向网的分析不存在度数的选择问题,有向网则要根据分析目标考虑使用出度还是入度。将度数矩阵减去邻接矩阵即得到拉普拉斯矩阵,即L = D-A。
L的特征根lambda_0 <= lambda_1 <= …<= lambda_{n-1} 存在一些有趣性质。首先,最小的特征根总等于0。因为如果将L乘以一个有n个元素的单位向量,相当于计算每一行的和,刚好是节点的度的自我抵消,结果等于0。其次,特征根中0 的个数即无向网G中分量的个数。这意味着如果除了最小特征根,没有别的特征根为0,则整个网络构成一个整体。
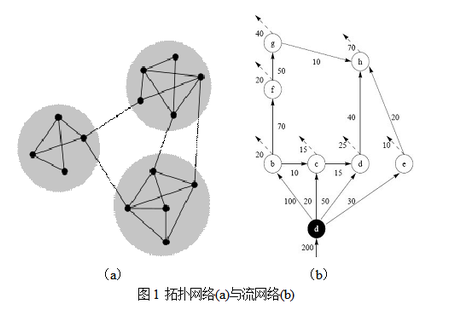
在这些特征根里,第二小的特征根(或者最小的非零特征根)lambda_1 又叫做代数连通性(algebraic connectivity),其对应的特征向量叫做Fidler vector。当lambda_1 >0,说明网络是一个整体。lambda_1 越大,说明网络彼此间的链接越紧密。从这个定义来看,非常像前面讨论的Q-Modularity,实际上在Newman2006的文章里,确实讨论了二者在数学上的对应关系。例如对示例网络所对应的进行分析,可以得到拉普拉斯矩阵如下:
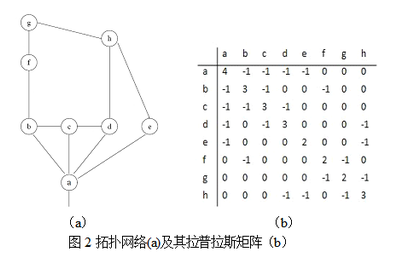
这个矩阵的特征根如下:{5.5, 4.5, 4.0, 3.4, 2.2, 1.3, 1.0, 0}。取lambda_1 =1时, Fidler vector={0.29, 0.00, 0.29, 0.29, 0.29, -0.58, -0.58, 0.00}。因为Fidler vector的值分别对应着图里的节点,于是可以写成{a:0.29, b: 0.00, c:0.29, d:0.29, e:0.29, f:-0.58, g:-0.58, h:0.00}。仅仅从元素的正负号就可以看出,该分析建议我们把f和g节点与其他节点分开,更细致的,对元素值大小的考察则建议把矩阵分成三个社区,{{a, c, d, e}, {b, h}, {e, f}}。回到图中考察,我们发现这个社区分类基本是合理的。
流分析
随机游走算法Walk Trap
P. Pons 和 M. Latapy 2005年提出了一个基于随机游走的网络社区划分算法。他们提出可以使用两点到第三点的流距离之差来衡量两点之间的相似性,从而为划分社区服务。其具体过程如下:首先对网络G所对应的邻接矩阵A按行归一化,得到概率转移矩阵(transition matrix)P。使用矩阵计算表达这个归一化过程,可以写作
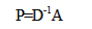
其中A是邻接矩阵,D是度矩阵。利用P矩阵的马可夫性质可知,它的t次方的元素Pijt就代表着随机游走的粒子经过t步从节点i到j的概率。其次,定义两点ij间的距离如下:
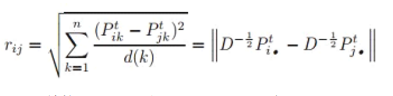
其中t是流的步长。步长必须恰当选择,因为如果t太小,不足以体现网络的结构特征,如果t太大,则Pijt趋近于与j的度数d(j)成正比, 随机游出发点i的拓扑信息被抹去。作者建议的t经验值为3到5之间。k是某一个目标节点。所以这个公式描述的是经过t步,ij到目标节点k的平均流转移概率(因为这个概率与中间节点k的度数d(k)成正比,所以要除以d(k)来去除这个影响)。ij到网络所有其他点之间的距离差别越小,说明ij很可能位于及其类似的位置上,彼此之间的距离也越接近。值得注意的是,这个思路如果只考虑一个或少数的目标节点,是不合适的。因为rij实际上只是结构对称性。有可能ij在网络的两端,距离很远,但到中间某个节点的距离是相等的。但因为公式要求k要遍历网络中除了ij以外的所有节点,这个时候ij如果到所有其他节点的流距离都差不多,比较可能是ij本身就是邻居,而不仅仅是结构上的对称。如公式所示,rij表达可以写成矩阵表达,其中Pti•是第P的t次方后第i行。
定义了任意两点之间的距离rij后,就可以将其推广,得到社区之间的距离rc1c2了
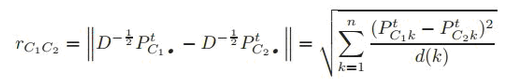
容易看出,这个距离与节点之间的距离很相似,只不过这次是计算两个社区分别到目标节点k的流距离,而计算单个社区C到节点k的流距离时,又是对社区C内所有节点到k流距离取平均。
一旦从流结构中提取了节点相似性,社区划分就是一个比较简单的聚类问题。例如可以采取合并式聚类法如下:先将每个节点视为一个社区,然后计算所有存在连边的社区之间的流距离。然后,取两个彼此连接且流距离最短社区进行合并,重新计算社区之间的距离,如此不断迭代,直到所有的节点都被放入同一个社区。这个过程社区的数目不断减小,导致出现一个树图分层(dendrogram)结构。在这个过程中,可以使用Q-modularity的变化来指导搜索的方向。
标签扩散算法label propagation
这种算法的思路源于冯诺依曼在50年代提出的元胞自动机模型(cellular automata)和Bak等人在2002年左右做的沙堆模型。该算法的基本原理如下:首先,给全网每个节点分配一个不重复的标签(label);其次,在迭代的每一步,让一个节点采用在它所有的邻居节点中最流行的标签(如果最佳候选标签超过一个,则在其中随机抽一个),;最后,在迭代收敛时,采用同一种标签的节点被归入同一个社区。 这个算法的核心是通过标签的扩散来模拟某种流在网络上的扩散。其优势是算法简单,特别适用于分析被流所塑造的网络。在大多数情况下可以快速收敛。其缺陷是,迭代的结果有可能不稳定,尤其在不考虑连边的权重时,如果社区结构不明显,或者网络比较小时,有可能所有的节点都被归入同一个社区。
总结
本文中我们总结了构建点击流网络之后,使用社区划分算法来对点进行聚类的不同思路。主要可以分为拓扑分析和流分析两种,从数学角度看,前者以频谱分析(Spectral analysis)为主要手段,后者以马可夫链(Markov chain)为主要建模工具