本篇主要介绍如何用pandas来分析一份刚拿到的数据集,即做数据挖掘或清洗的工作。
这里以贷款申请预测的数据来作为例子
一、查看基本信息
拿到数据首先看看大致结构,查看行列数,dataframe数据结构的通用信息,和基本数据类型信息
方法:pandas.head(), pd.info(), pd.shape
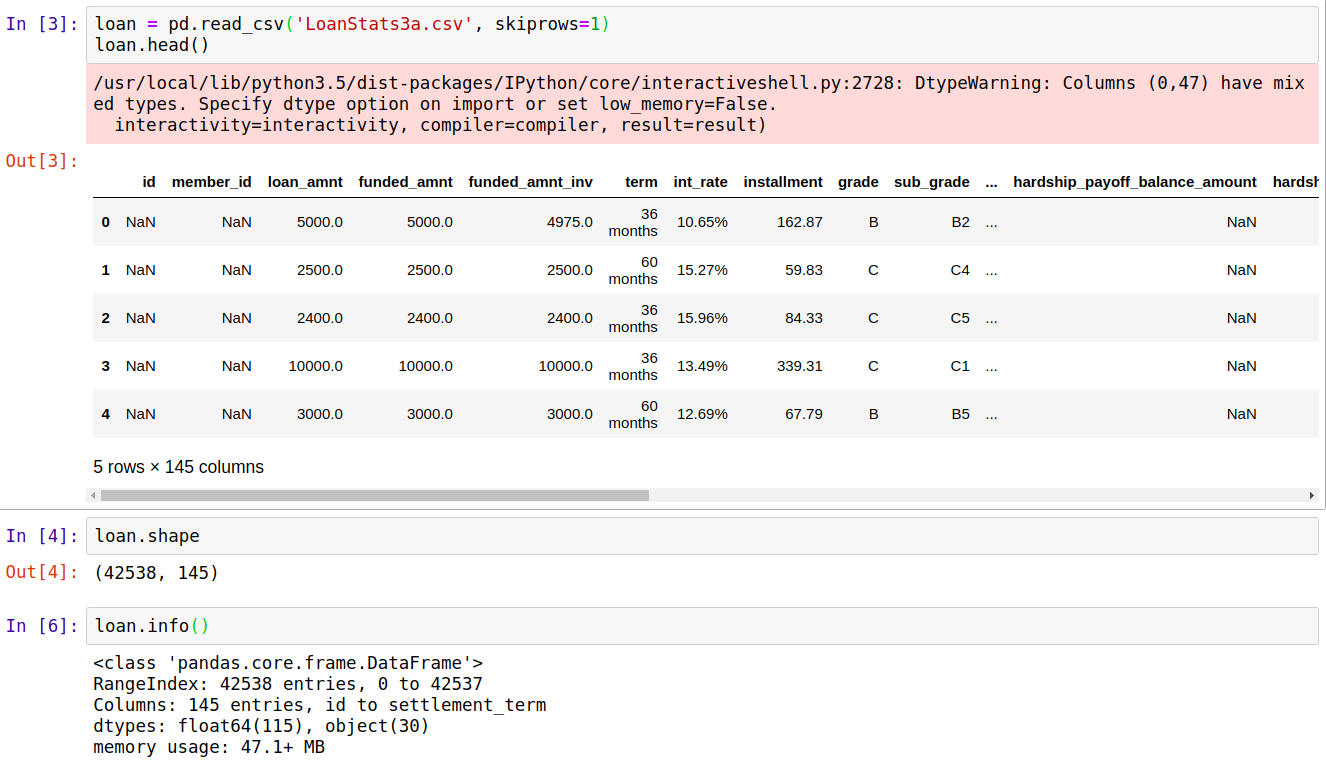
这里特征太多,只做了统计,如果特征量不多一般是列表,会对每一项标出诸如bool,int64,float64和object的数据的类型特征,最后会统计各个类型特征有几个。同样地,我们还可以很容易地查看数据中是否存在缺失值。
二、初步删除大缺失值的项,重复样本
缺失值一般从列看,如果某一个特征缺失值过多,那么也没有多大的作用了,可以删除,比如缺失值过半。从横向看,然后是某些样本是重复的,应该删除重复项。
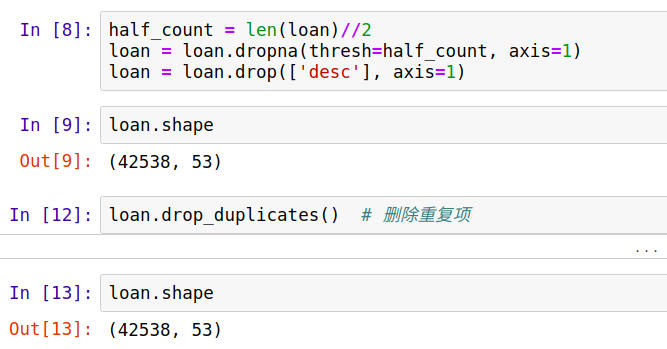
可见我们的数据特征项缺失很严重,样本没有重复。 dropna()中shresh的意思时样本中某一列的缺失值要达到thresh值才删除该列。
三、确定label
有时候,数据不一定会有明显的label,需要自己处理,比如这里,我们没有哪一项是明确的到底给某个样本是贷款还是没贷款。根据我们的项目,有一项可以作为label,不过还需要先处理一下。
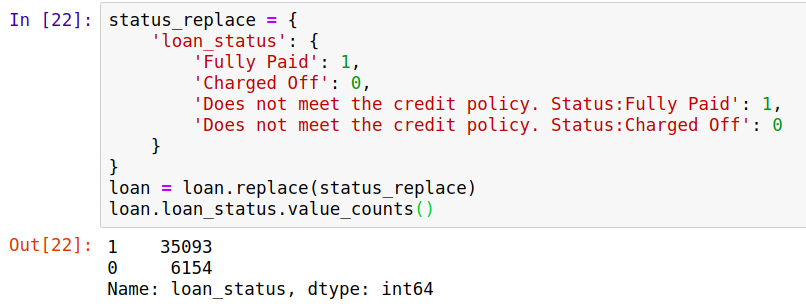
可见我们的label把贷款取为1,没贷款取为0. 且样本不均衡,这是后面考虑的问题,这里不作讨论
四、根据不同项目,决定删除无用的特征
1、pd.columns可以查看所有特征项名
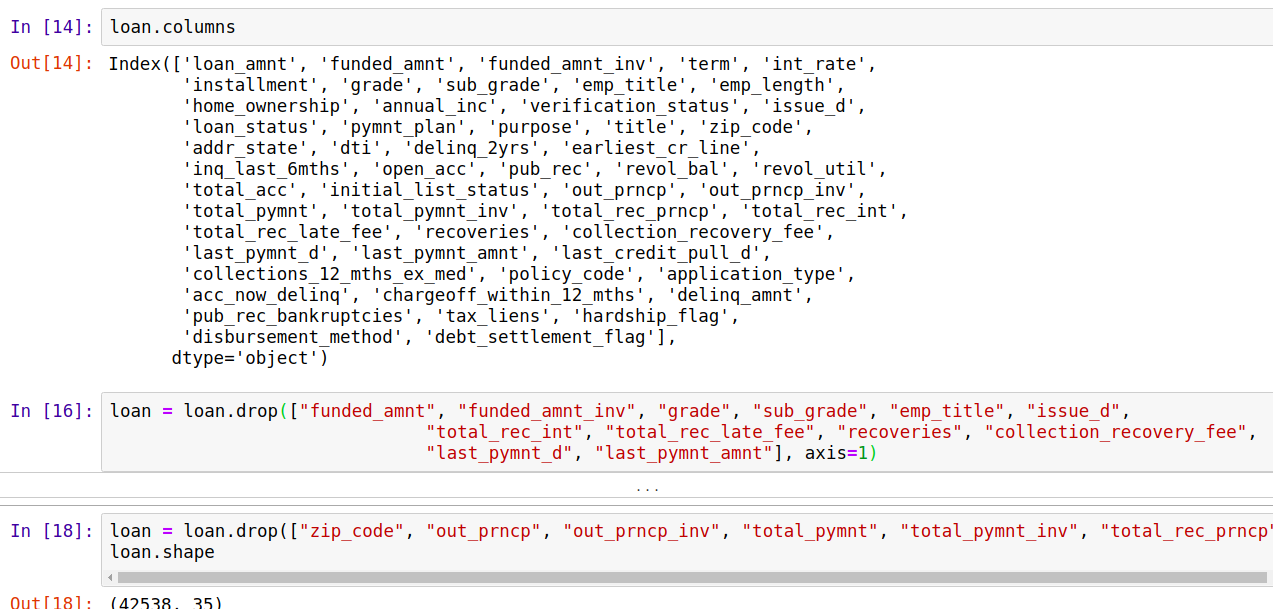
2、还有一种情况是某个特征一直是一个值,比如如果统计中国人身高,出现国籍一栏,那肯定都是中国,对结果没有什么参考价值,这种情况也应该删除

五、开始对每一个特征项进行处理
1、比如根据缺失值的多少来选择不同的应对方式,填充还是删除。如果缺失值相对总样本来说比较小可以直接删除这些样本行或者填充。如果构成一定的比例,可以直接填充为某一个值,当做该特征的一个值。
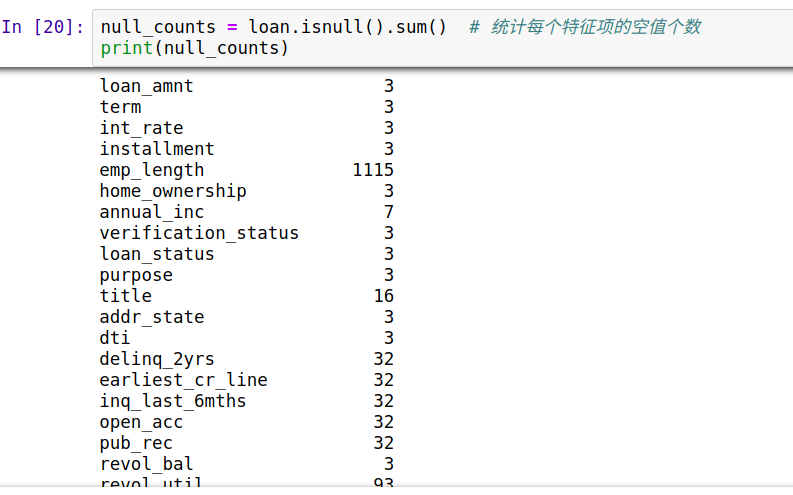

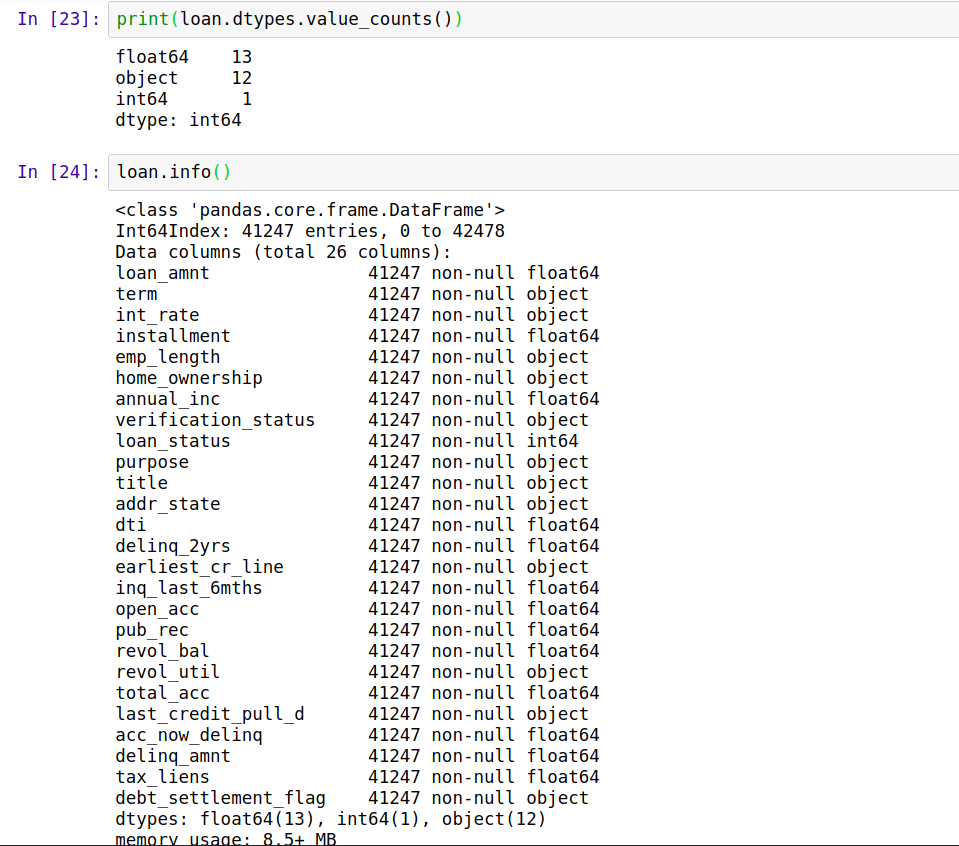
2、计算机只认识数值型特征,对于非数值型特征(object,bool),需要转化为数值型特征。可以用loan.dtypes.value_counts()查看有多少种数据类型,可以用loan.info()来看具体每一项特征的数据类型,可以看到还可以看到数据是否有缺失。
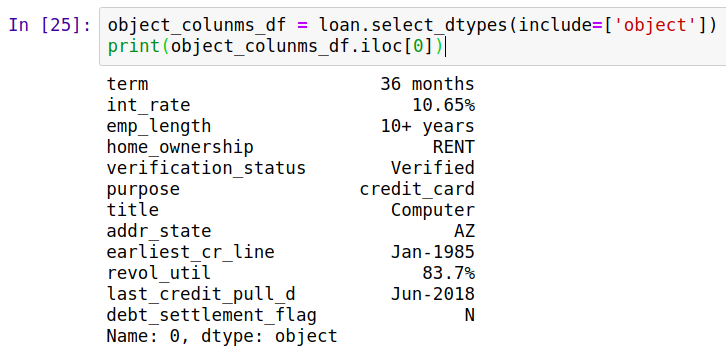
列出所有object类型,并查看数据
3、接下来对每一个object类型数据分别转换为数值型。可以自己命名,也可以用one-hot encoding 编码。什么时候用one-hot encoding呢,如果某个非数值型特征本身不存在大小之分,自己转换为数值后,计算机分析时默认会以大小来衡量,这样是不妥的。比如有三种颜色,红绿蓝,如果用数字1/2/3来表示,有大小之分就不合适,适合用独热编码来处理。比如下面的年龄,本来就有大小之分。
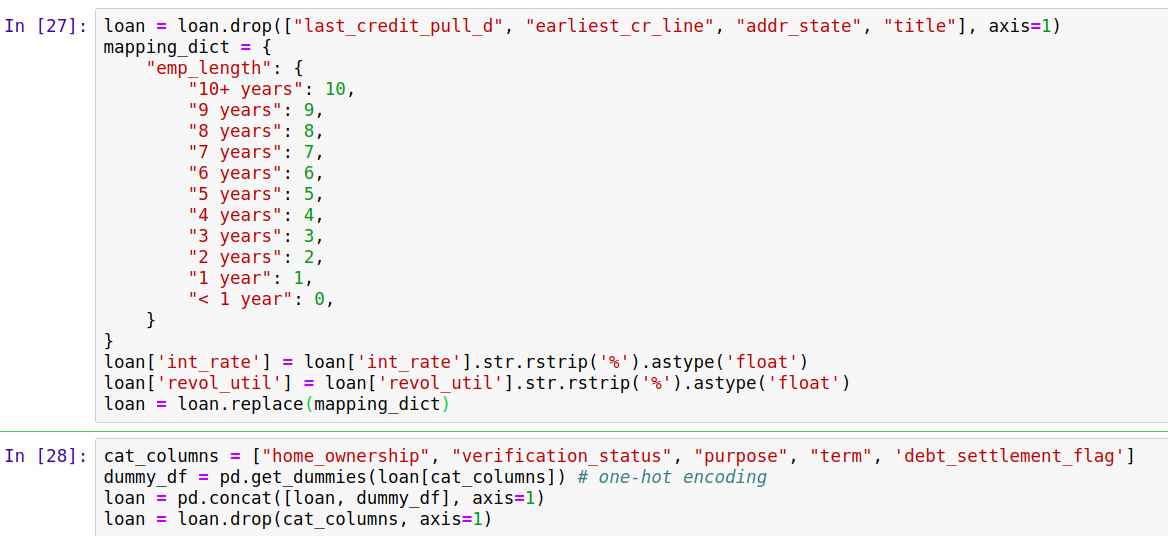
4、我们用astype()方法来改变数据的列类型,如上。应用这种方法,我们也可以直接将bool数据类型转化为int64类型:(我们数据里没有bool类型数据)
df['Churn'] = df['Churn'].astype('int64') # 假设Churn为bool特征
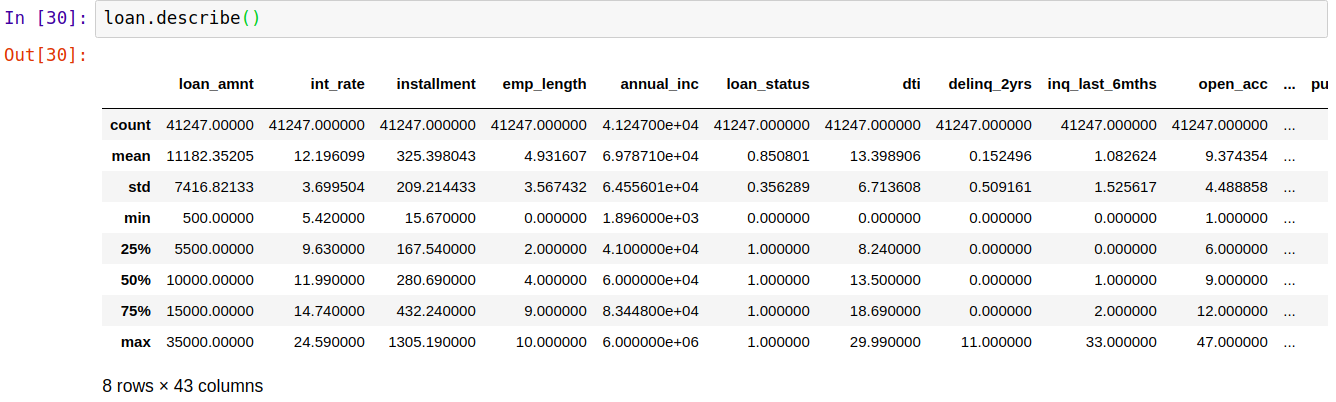
5、至此,我们已经将所有数据转换为数值型,可以用describe()方法用来描述每个数字特征(int64和float64类型)的基本统计信息:包括非缺失值的数量,均值,标准差,范围,中位数,0.25和0.75四分位数。
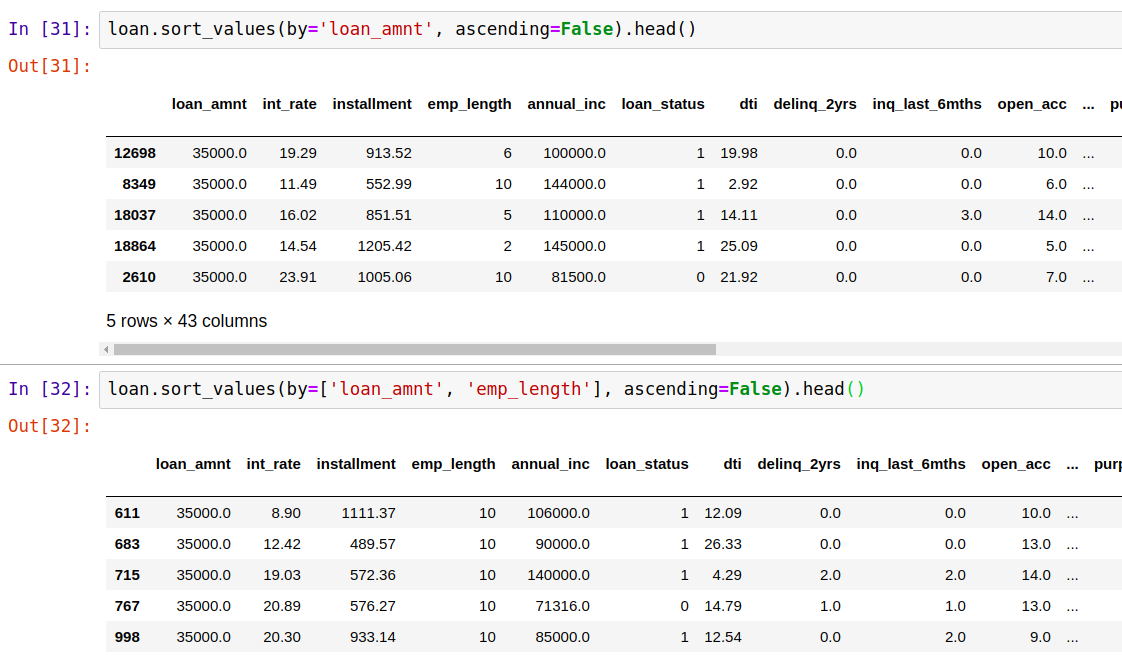
六、排序
DataFrame数据结构可以对一个特定变量的值(如列)进行排序。例如,我们可以按某一列排序(设置参数ascending= False,按降序排序),我们还可以对多列进行排序:
七、时间序列
pandas可以直接,时间数值转换为标准的datetime时间格式,然后可以对时间序列做相应的操作。这里以纽约州某一个区的不同时间用电量统计来举例。
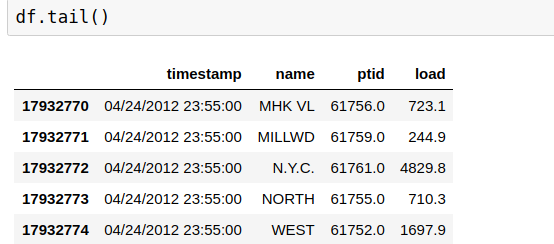
一开始我们的时间表示是这样的,而且它是一个str类型
pandas.to_datetime()可以直接把时间数值转换为标准的datetime时间格式,注意转换时,加上format格式说明,如果数据量很大可以节省很多时间。

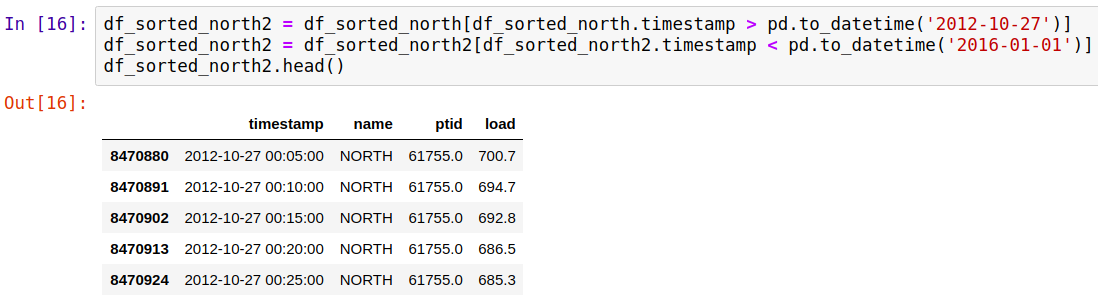
接下来就可用> 、< 或 == 来选择数据某几行数据了,也可以按时间排序。
![]()
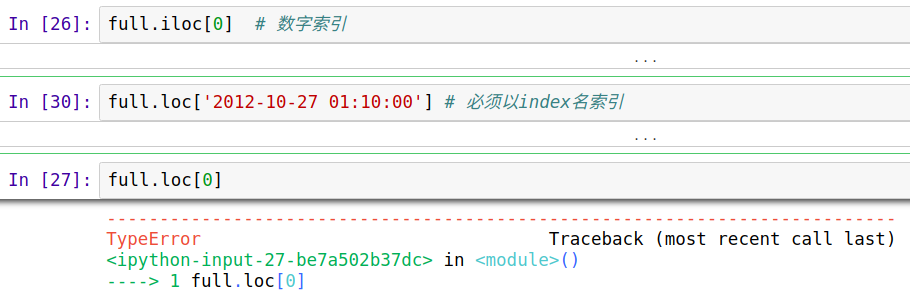
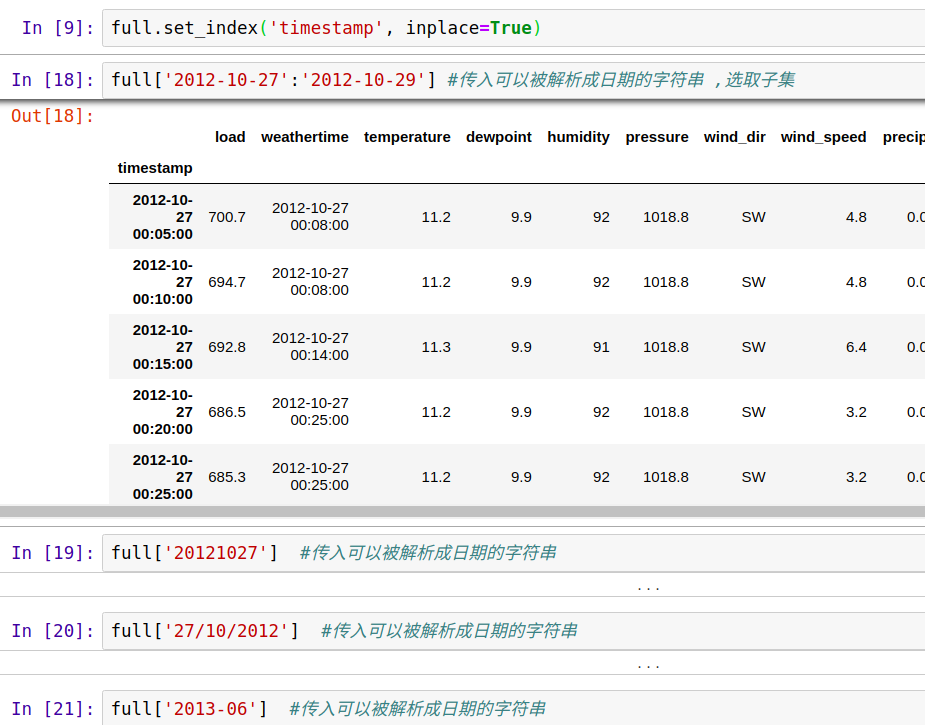
把timestamp设为index, 可以很方便做数据索引,选取以及子集构造
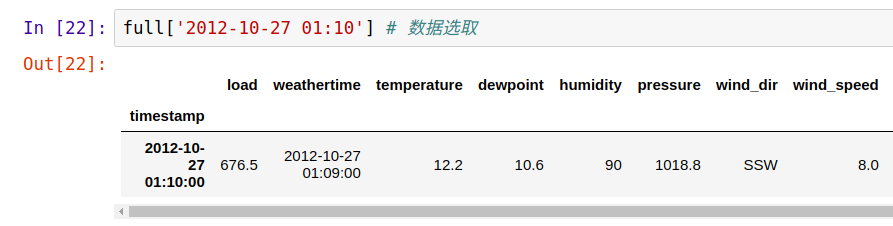
这里我们可以借机看看iloc和loc的区别,如果dataframe有给定index,对于loc必须要以index名称索引,而,iloc任何时候都可以用数字索引,如df.iloc[0] 。