链接:http://acm.hdu.edu.cn/showproblem.php?pid=4656
脑子抽了做叉姐200题,一道题上午续到晚上。。
这道题不仅式子贼难推(推了几个小时弃疗),推完还不能直接上fft,要用什么任意模数fft(代码又调几个小时)。。
part1:推式子
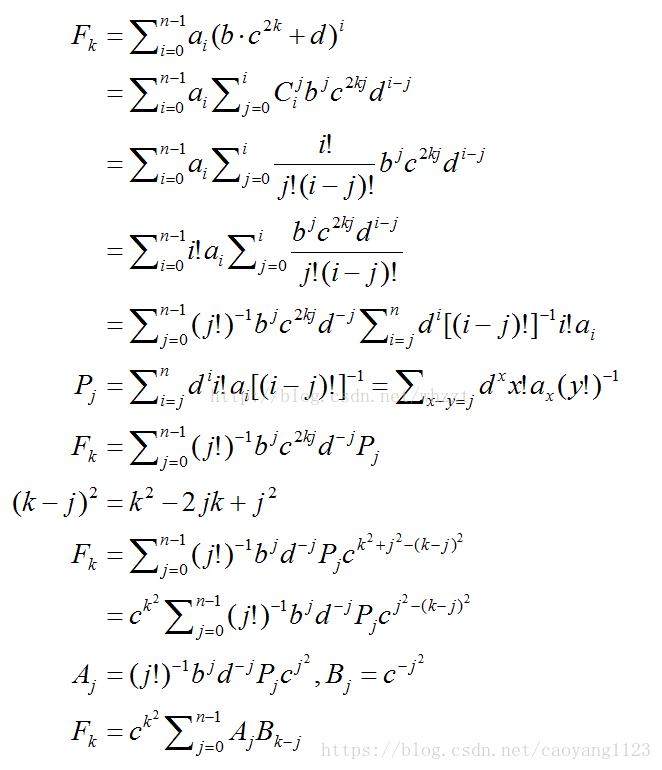
----转载自https://blog.csdn.net/whzzt/article/details/70880091(Orz)
个人认为比较高妙的两步是将枚举顺序交换,然后先处理掉一部分化简式子,还有一步就是(k-j)^2那个吊炸天的操作了(推了上午搞不出来就是因为c^2kj这个玄学东西)。
part2:任意模数fft
之后因为ai在10^6,而且模数不是ntt模数(实际上我也不会ntt),所以要用什么任意模数fft,强行学了一波,其实是一种解决子问题在合并的思想,将模数拆到根号级别,得到任意一个数可表示为a*k+b形式,把两个要进行卷积的数组中每个数都拆成a,b,一共四个数组,都做一次DFT,然后发现实际上(a1*k+b1)*(a2*k+b2)==a1*a2*k*k+(a1*b2+a2*b1)*k+b1*b1,k是一个常数提到fft过程完成后乘,所以这样按乘k的次数分3组最后合并,就能保证fft时数的大小转变为根号n级,不会爆精度了。。
代码:
#include<bits/stdc++.h>
#define ll long long
#define db double
using namespace std;
const ll mod=1e6+3,mo=sqrt(mod);
const int N=5e5+10,M=2e5+10;
const db pi=acos(-1);
struct cp{
db r,i;
cp(){r=0,i=0;}
cp(db x,db y):r(x),i(y){}
}omg[N],mp[4][N];
cp operator +(const cp x,const cp y)
{return cp(x.r+y.r,x.i+y.i);}
cp operator -(const cp x,const cp y)
{return cp(x.r-y.r,x.i-y.i);}
cp operator *(const cp x,const cp y)
{return cp(x.r*y.r-x.i*y.i,x.r*y.i+x.i*y.r);}
int n,wh[N],lim,cnt,tp1[N],tp2[N],tax1[N],tax2[N],tax3[N];
int jc[M],inv[mod+10],ijc[M],bb[M],dd[M],idd[M];
int b,c,d,a[M];
ll p[N],ans[N];
ll qpow(ll x,ll y)
{
ll res=1;
while(y)
{
if(y&1)res=1LL*res*x%mod;
x=1LL*x*x%mod,y>>=1;
}
return res;
}
void init()
{
jc[0]=1,ijc[0]=1,inv[1]=1;
for(int i=2;i<mod;i++)inv[i]=1LL*(mod-mod/i)*inv[mod%i]%mod;
for(int i=1;i<=n;i++)
jc[i]=1LL*jc[i-1]*i%mod,ijc[i]=1LL*ijc[i-1]*inv[i]%mod;
bb[0]=dd[0]=idd[0]=1;
for(int i=1;i<=n;i++)
{
bb[i]=1LL*bb[i-1]*b%mod;
dd[i]=1LL*dd[i-1]*d%mod;
idd[i]=1LL*idd[i-1]*inv[d]%mod;
}
for(int i=1;i<=lim;i++)
wh[i]=(wh[i>>1]>>1)|((i&1)<<(cnt-1));
for(int i=0;i<lim;i++)
omg[i]=cp(cos(2*pi*i/lim),sin(2*pi*i/lim));
omg[lim]=omg[0];
}
void fft(cp *a,bool inv)
{
int mid;cp t;
for(int i=0;i<lim;i++)
if(i<wh[i])swap(a[i],a[wh[i]]);
for(int l=2;l<=lim;l<<=1)
{
mid=l>>1;
for(int i=0;i<lim;i+=l)
{
for(int j=0;j<mid;j++)
{
t=a[i+j+mid]*(inv?omg[lim-lim/l*j]:omg[lim/l*j]);
a[i+j+mid]=a[i+j]-t;
a[i+j]=a[i+j]+t;
}
}
}
}
void mtt(int *x,int *y)
{
static cp t1,t2,t3;
for(int i=0;i<lim;i++)
{
mp[0][i]=cp(x[i]/mo,0),mp[1][i]=cp(x[i]%mo,0);
mp[2][i]=cp(y[i]/mo,0),mp[3][i]=cp(y[i]%mo,0);
}
fft(mp[0],0),fft(mp[1],0),fft(mp[2],0),fft(mp[3],0);
for(int i=0;i<lim;i++)
{
t1=mp[0][i]*mp[2][i],t2=mp[1][i]*mp[2][i]+mp[3][i]*mp[0][i];
t3=mp[1][i]*mp[3][i],mp[0][i]=t1,mp[1][i]=t2,mp[2][i]=t3;
}
fft(mp[0],1),fft(mp[1],1),fft(mp[2],1);
for(int i=0;i<lim;i++)
{
mp[0][i].r/=lim,mp[1][i].r/=lim,mp[2][i].r/=lim;
x[i]=(((ll)(mp[0][i].r+0.5)%mod*mo*mo%mod)+((ll)(mp[1][i].r+0.5)%mod*mo%mod)+((ll)(mp[2][i].r+0.5)%mod))%mod;
}
}
main(void)
{
scanf("%d",&n);
scanf("%d%d%d",&b,&c,&d);b%=mod,c%=mod,d%=mod;
for(int i=0;i<n;i++)
scanf("%d",&a[i]),a[i]%=mod;
lim=1,cnt=0;
while(lim<=2*n)lim<<=1,cnt++;
init();
for(int i=0;i<n;i++)
{
tp1[i]=1LL*dd[i]*jc[i]*a[i]%mod;
tp2[i]=ijc[i];
}
for(int i=0;i<n;i++)
if(i<n-i)swap(tp1[i],tp1[n-i]);
mtt(tp1,tp2);
for(int i=0;i<n;i++)p[i]=tp1[n-i];
for(int i=0;i<=lim;i++)
tp1[i]=tp2[i]=0;
tp2[n]=1;
for(ll i=0;i<n;i++)
{
tp1[i]=1LL*bb[i]*qpow(c,i*i)*p[i]%mod*idd[i]*ijc[i]%mod;
tp2[n+i]=inv[qpow(c,i*i)],tp2[i]=inv[qpow(c,(n-i)*(n-i))];
}
mtt(tp1,tp2);
for(int i=0;i<n;i++)ans[i]=tp1[n+i],ans[i]=1LL*ans[i]*qpow(c,1LL*i*i)%mod;
for(int i=0;i<n;i++)
printf("%lld\n",ans[i]);
}