版权声明:欢迎转载,转载需要明确表明转自本文 https://blog.csdn.net/u012442157/article/details/80309088
一、Background
在学会了用deeplearning做情感分类之后,如何评价自己的模型有效果呢?如果没有评价指标的话,别人也没法知道你的方法好不好,那么你所做的一切都是浮云。
最简单的评价指标就是准确率(Accuracy),常用的还有精确率(Precision)、召回率(Recall)、F值、宏平均与微平均等等。并且现在的分类基本上都是多分类问题,我就直接按照多分类来阐述。
二、评价指标
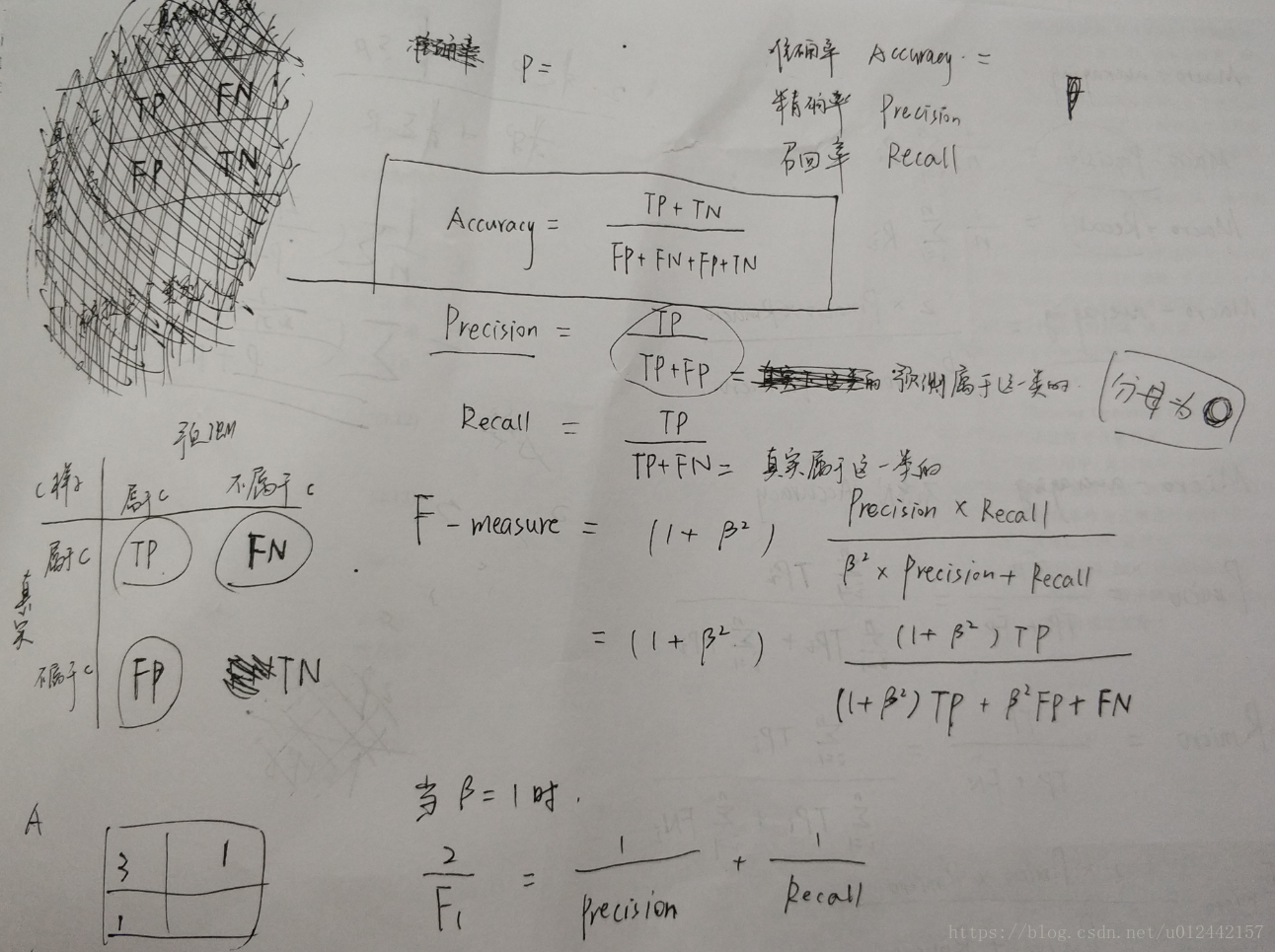
多类分类问题中,分类结果一般有4种情况:
- 属于类C的样本被正确分类到类C,记这一类样本数为TP
- 不属于类C的样本被错误分类到类C,记这一类样本数为FP
- 属于类别C的样本被错误分类到类C的其他类,记这一类样本数为FN
- 不属于类别C的样本被正确分类到了类别C的其他类,记这一类样本数为TN
1、Accuracy
准确率
2、Precision
精确率
3、Recall
召回率
4、F-measure
F值
通常情况下, 取为1。
5、Macro-averaging
宏平均是指所有类别的每一个统计指标值的算数平均值,也就是宏精确率

三、Demo
四、Reference
不得不说这个有很多错误,但还是有值得借鉴的地方
https://sanmisanfan.github.io/2017/08/16/mulitlable-classification/
http://www.cnblogs.com/robert-dlut/p/5276927.html
https://zhuanlan.zhihu.com/p/30953081