本文主要讲解如何将网页上的数据写入到excel表中,因为我比较喜欢看小说,我们就以笔趣阁的小说数据为例,来说明怎么把笔趣阁的小说关键信息统计出来,比如:小说名、字数、作者、网址等。
根据之前的几次爬虫实例分析笔趣网源代码知道,小说名在唯一的标签h1中,因此可以通过h1.get_txt()得到小说名,作者在meta标签,property=”og:novel:author”中,可以通过html.find_all(‘meta’,property=”og:novel:author”)获取到包含该信息的列表,其他信息也可同样得到。
这里要用到的BeautifulSoup库、处理读excel的xlrd库、写入excel的xlwt库、负责excel复制的xlutils库。
代码:
#coding:utf-8
import os
import sys
import re
from bs4 import BeautifulSoup
from urllib import request
import xlrd
# from xlwt import *
import xlwt
from xlutils.copy import copy
#from datetime import datetime
url = 'http://www.biqiuge.com/book/37708/'
url = 'http://www.biqiuge.com/book/'
def getHtmlTree(url):
webPage = request.urlopen(url)
htmlCode = webPage.read()
htmlTree = BeautifulSoup(htmlCode,'html.parser')
return htmlTree
# xlsName = r'2.xls'
#判断网页是否存在
def adjustExist(url):
try:
htmlTree=getHtmlTree(url)
title = htmlTree.h1.get_text()
author = htmlTree.find_all('meta',property="og:novel:author")
author = author[0]['content']
txtSize = htmlTree.find('div',id='info')
txtSize = txtSize.find_all('p')
txtSize = str(txtSize)
flag1 = txtSize.find('共')
flag2 = txtSize.find('字')
if -1 == flag1 or -1 == flag2:
txtSize = ''
else:
txtSize = txtSize[flag1:flag2+1]
if u'出现错误!-笔趣阁' == title:
print(url + ' 不存在!')
else:
print(url)
except:
author = 'fbl'
txtSize = '0 bytes'
title = 'Unknow'
pass
finally:
return (author,txtSize ,title)
def main():
reWriteFlag = False
start_url = 6000
end_url = 30000
if start_url > end_url:
(end_url,start_url) = (start_url,end_url)
# start_url = 40000
# end_url = 40001
#init = [u'序号',u'小说名',u'字数',u'作者',u'路径']
# workbook = xlwt.Workbook(encoding = 'utf-8')
# data_sheet = workbook.add_sheet(u'笔趣阁小说')
fileName = u'笔趣阁.xls'
workbook = xlrd.open_workbook(fileName,formatting_info=True)
# newBook = copy(workbook)
# data_sheet = newBook.get_sheet(u'笔趣阁小说')
if reWriteFlag:
# old_sheet = workbook.sheet_by_name(u'笔趣阁小说')
newBook = copy(workbook)
data_sheet = newBook.get_sheet(u'笔趣阁小说')
for i in range(len(init)):
data_sheet.write(0,i,init[i])
newBook.save(fileName)
for j in range(start_url,end_url):
workbook = xlrd.open_workbook(fileName,formatting_info=True)
table = workbook.sheets()[0]
try:
cell_value = table.cell(j,0).value
# print(type(cell_value))
if cell_value != '':
print(cell_value)
continue
except:
print('NLL')
pass
url_tmp = url + str(j)
(author,size,title) = adjustExist(url_tmp)
tmp = [j,title,size,author,url_tmp]
newBook = copy(workbook)
data_sheet = newBook.get_sheet(u'笔趣阁小说')
# data_sheet = newBook.sheet_by_name(u'笔趣阁小说')
# print(cell_value)
for k in range(len(tmp)):
data_sheet.write(j,k,tmp[k])
newBook.save(fileName)
main()
效果图展示:
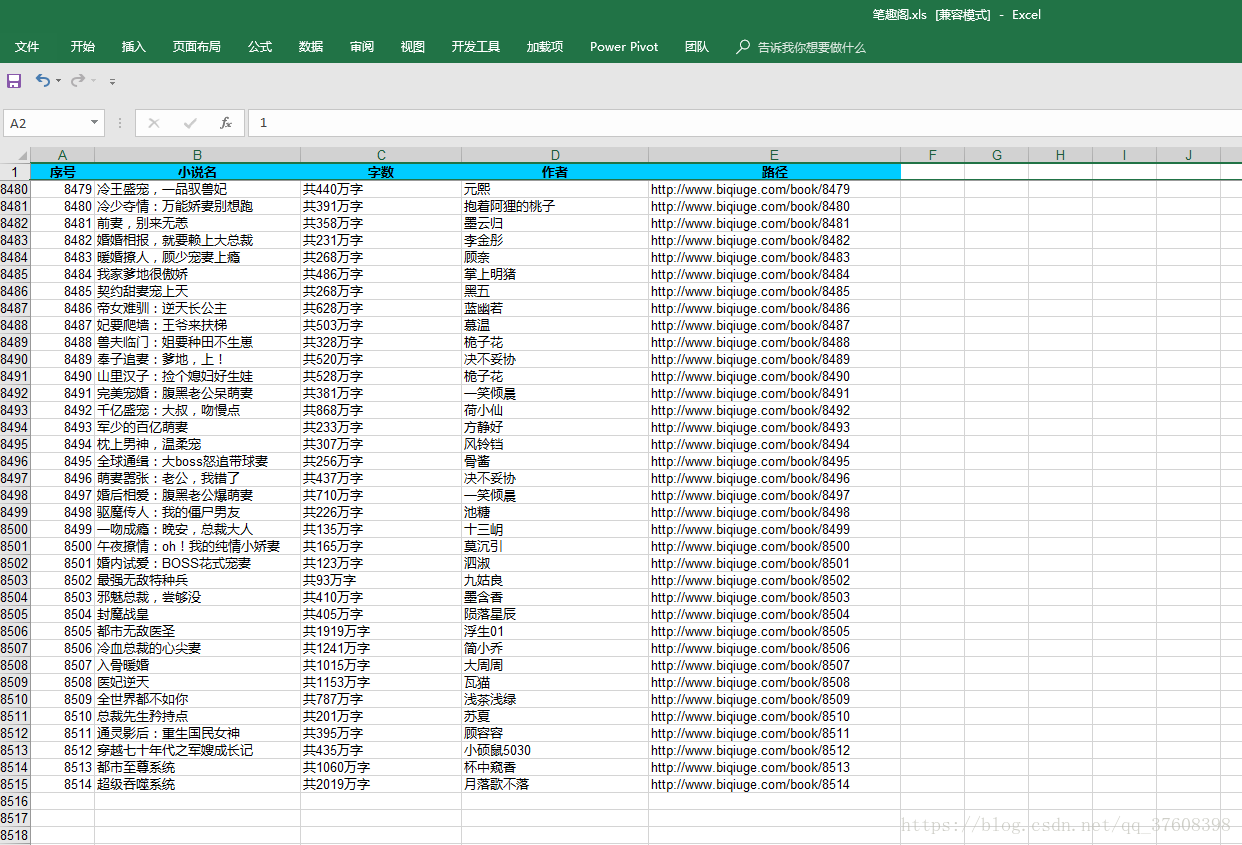
在通过excel的数据分列功能可以将字数提取出来作为关键数据:
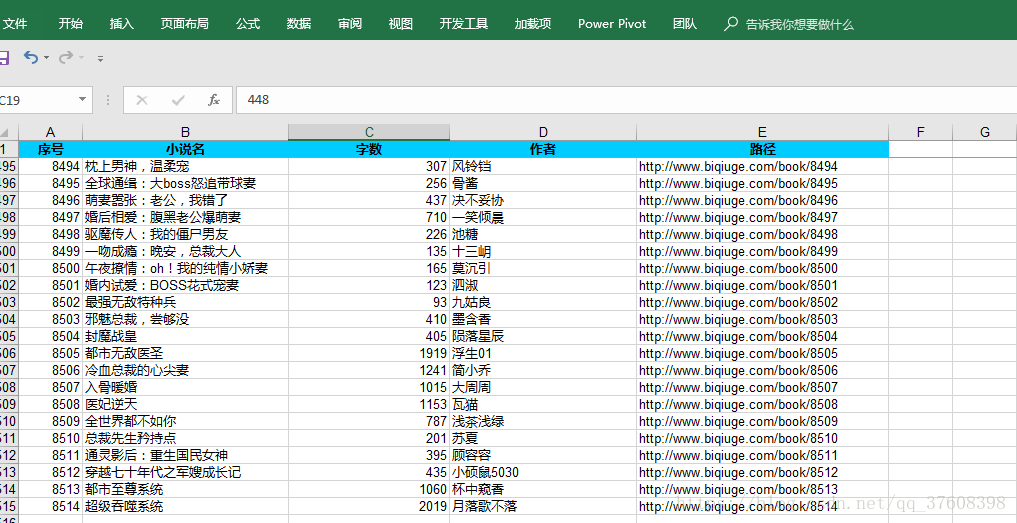
有需要这份数据的请去我的资源下载,资源名:笔趣阁小说数据汇总.xls