原文
一文读懂BiLSTM+CRF实现命名实体识别 — PaddleEdu documentation
https://paddlepedia.readthedocs.io/en/latest/tutorials/natural_language_processing/ner/bilstm_crf.html
BiLSTM + CRF是一种经典的命名实体识别(NER)模型方案,这在后续很多的模型improvment上都有启发性。如果你有了解NER任务的兴趣或者任务,或者完全出于对CRF的好奇,建议大家静心读一读这篇文章。
本篇文章会将重点放到条件随机场(CRF)上边,因为这是实现NER任务很重要的一个组件,也是本篇文章最想向你推荐的特色。但是如果你 对长短时记忆网络(LSTM)也不是很熟悉,那你也不用担心,笔者会去解释LSTM的用法,它的输入和输出等等内容,以保证你可以顺畅的读下去,领悟到这个模型的精髓。
内容目录
- 一种实现NER的策略:BiLSTM+CRF
- 回归CRF建模原理本身
2.1 线性CRF的定义
2.2 发射分数和转移分数
2.3 建模CRF的损失函数
2.4 单条路径的分数计算
2.5 全部路径的分数计算
2.6 CRF的Viterbi解码
1. 使用BiLSTM+CRF实现NER
为方便直观地看到BiLSTM+CRF是什么,我们先来贴一下BiLSTM+CRF的模型结构图,如图1所示。
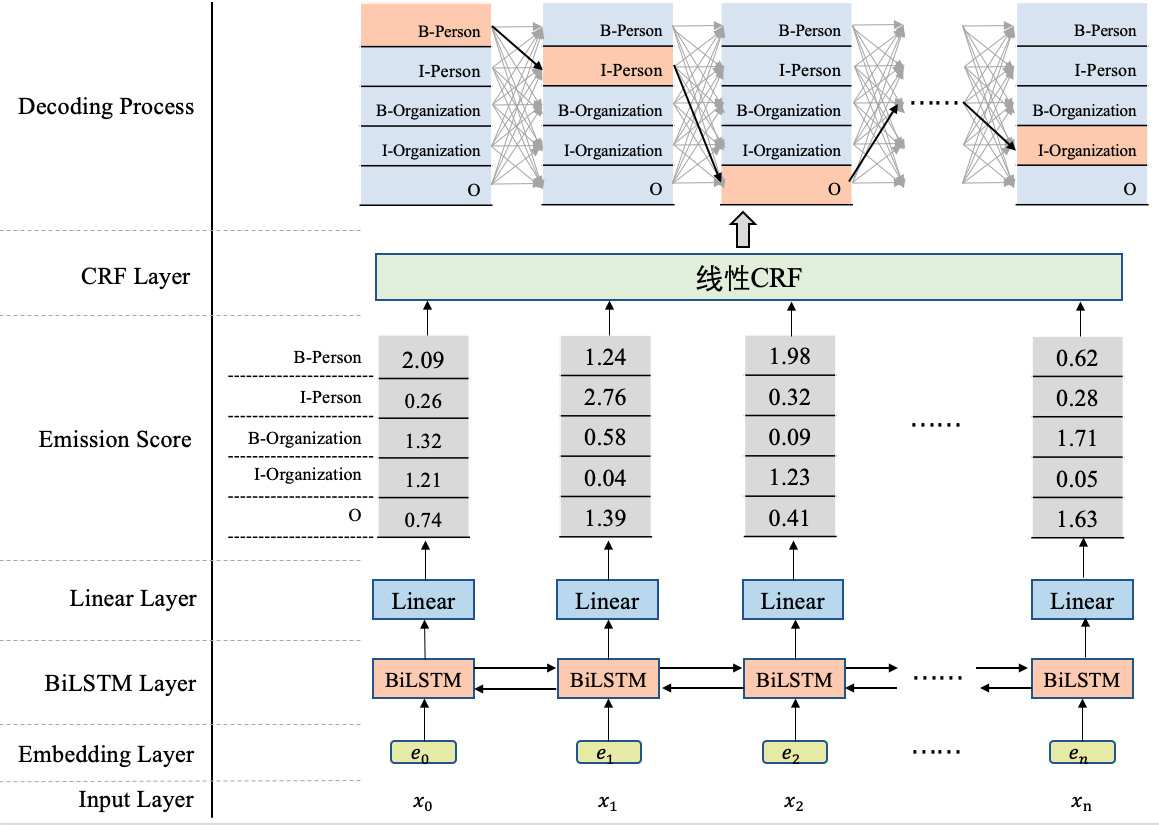
从图1可以看到,在BiLSTM上方我们添加了一个CRF层。具体地,在基于BiLSTM获得各个位置的标签向量之后,这些标签向量将被作为发射分数传入CRF中,发射这个概念是从CRF里面带出来的,后边在介绍CRF部分会更多地提及,这里先不用纠结这一点。
这些发射分数(标签向量)传入CRF之后,CRF会据此解码出一串标签序列。那么问题来了,从图1最上边的解码过程可以看出,这里可能对应着很多条不同的路径,例如:
- B-Person, I-Person, O, …, I-Organization
- B-Organization, I-Person, O, …, I-Person
- B-Organization, I-Organization, O, …, O
CRF的作用就是在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的输出。
我们来总结一下,使用BiLSTM+CRF模型架构实现NER任务,大致分为两个阶段:使用BiLSTM生成发射分数(标签向量),基于发射分数使用CRF解码最优的标签路径。
2. 回归CRF建模原理本身
本节将开始聚焦在CRF原理本身进行讲解,力图为读者展现一个清楚明白,基础本质的CRF。那现在开始这趟学习之旅吧,相信你一定会有所收获。
2.1 线性CRF的定义
通常我们会使用线性链CRF来建模NER任务,所以本实验将聚焦在线性链CRF来探讨。那什么是线性链CRF呢,我们来看下李航老师在《统计学习方法》书中的定义:
设 X = [ x 1 , x 2 , . . . , x n ] , Y = [ y 1 , y 2 , . . . , y n ] X=[x_1, x_2, ..., x_n],Y=[y_1, y_2, ..., y_n] X=[x1,x2,...,xn],Y=[y1,y2,...,yn] 均为线性链表示的随机变量序列,若在给定随机变量序列的 X X X的条件下,随机变量序列 Y Y Y的条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)构成条件随机场,即满足马尔可夫性:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ P(y_i|X, y_{1}…
则称 P ( Y ∣ X ) P(Y|X) P(Y∣X)为线性链条件随机场。
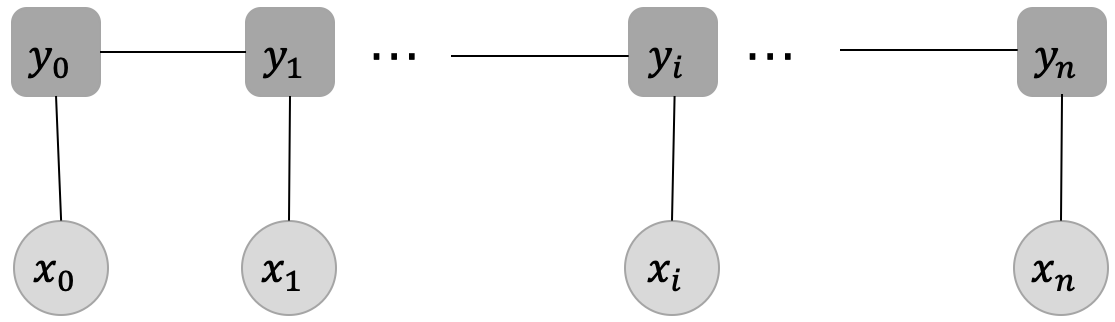
同学们看到这个定义,或许会有些疑惑,但是不用着急,我们来探讨下这个定义。图2展示了一种经典的线性链CRF的结构图,从这张结构图来理解这个定义,主要包含两个点:
- 确保输入序列 X X X和输出序列 Y Y Y是线性序列
- 每个标签 y i y_i yi的产生,只与这些因素有关系:当前位置的输入 x i x_i xi, y i y_i yi直接相连的两个邻居 y i − 1 y_{i-1} yi−1和 y i + 1 y_{i+1} yi+1,与其他的标签和输入没有关系。
这样的定义,其实帮助我们减小了建模CRF的代价。
2.2 发射分数和转移分数
上边我们探讨了线性链CRF的定义以及它的一种经典图结构,接下来我们继续回到我们建模的命名实体任务上来。
在图2中, x = [ x 0 , x 1 , . . . , x i , . . . , x n ] x=[x_0, x_1, ... , x_i, ... , x_n] x=[x0,x1,...,xi,...,xn]代表输入变量,对应到我们当前任务就是输入文本序列, y = [ y 0 , y 1 , . . . , y i , . . . , y n ] y=[y_0, y_1, ..., y_i, ..., y_n] y=[y0,y1,...,yi,...,yn]代表相应的标签序列,
其中,每个输入 x i x_i xi均对应着一个标签 y i y_i yi,这一步对应的就是发射分数,它指示了当前的输入 x i x_i xi应该对应什么样的标签;在每个标签 y i y_i yi之间也存在连线,它表示当前位置的标签 y i y_i yi向下一个位置的标签 y i + 1 {y_{i+1}} yi+1的一种转移。举个例子,假设当前位置的标签是"B-Person",那下一个位置就很有可能是"I-Person"标签,即标签"B-Person"向"I-Person"转移的概率会比较大。
这里我们带出了建模CRF过程中两个重要的概念:发射分数和转移分数,下边我们来看看他们是什么。
2.2.1 发射分数
前边我们在第2节已经提到过发射分数了,即BiLSTM后产生的标签向量。如果大家对这部分内容已经很熟悉,完全可以跳过这部分。图3以矩阵的形式展示了发射分数的生成过程。
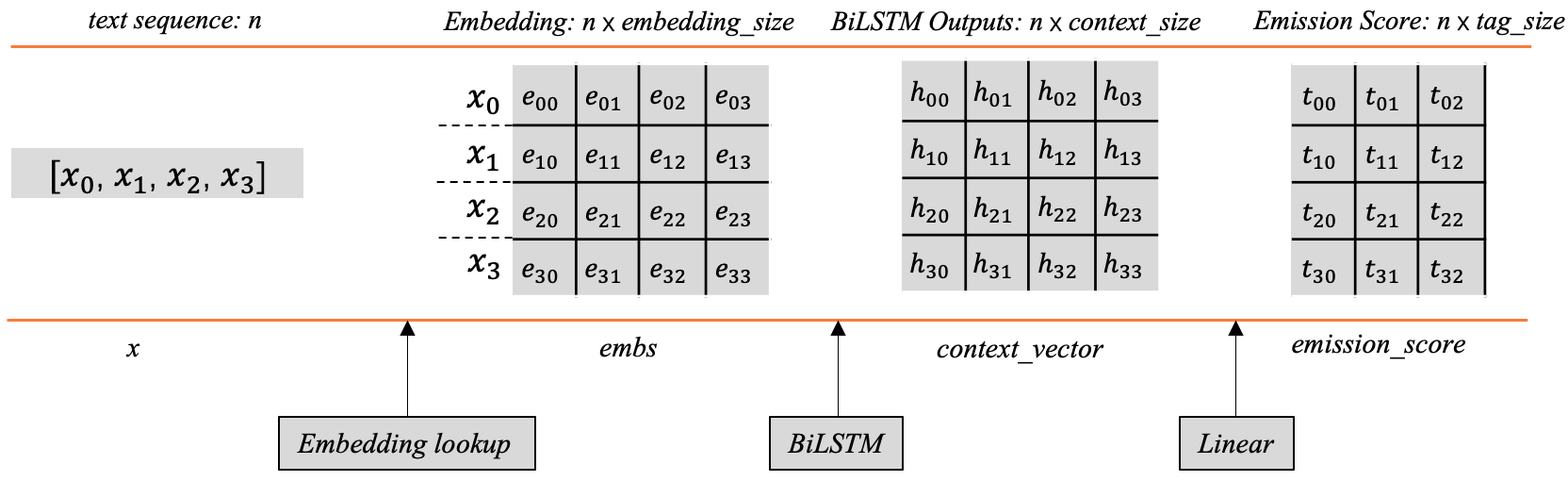
当给定的文本序列 x = [ x 1 , x 2 , x 3 , . . . , x n ] x=[x_1, x_2, x_3,..., x_n] x=[x1,x2,x3,...,xn]映射为对应词向量之后,将会得到一个shape为 [ n , e m b e d d i n g _ s i z e ] [n, embedding\_size] [n,embedding_size]的词向量矩阵 e m b s embs embs,其中每对应一个字词(图5样例只使用了4个词),例如 x 0 x_0 x0对应的词向量是 [ e 00 , e 01 , e 02 , e 03 ] [e_{00}, e_{01}, e_{02}, e_{03}] [e00,e01,e02,e03]。
然后将 e m b s embs embs传入BiLSTM后,每个词的位置都会产生一个上下文向量,所有的向量组合之后会得到一个向量矩阵 c o n t e x t _ v e c t o r context\_vector context_vector,其中每行代表对应单词经过BiLSTM后的上下文向量。
这里的每个位置的上下文向量可以用来指导当前位置应该输出的标签信息,但这里有个问题,这个输出向量的维度并不是标签的数量,它不能直接用来指示应该输出什么标签。一般的做法是在后边加一层线性层,将这个上下文向量的维度映射为标签的数量,这样的话就会生成前边所讲的标签向量,其中的每个元素分别对应着相应标签的分数,根据这个分数可以用来指导最终标签的输出。
具体地,线性层这里只是做了这样的一个线性变换: y = X W + b y = XW+b y=XW+b,显然,这里的 X X X就是 c o n t e x t _ v e c t o r context\_vector context_vector, y y y是相应的 e m i s s i o n _ s c o r e emission\_score emission_score, W 和 b W和b W和b是线性层的可学习参数。
前边提到, c o n t e x t _ v e c t o r context\_vector context_vector的shape为 [ n , c o n t e x t _ s i z e ] [n,context\_size] [n,context_size],那么线性层的 W W W的shape应该是 [ c o n t e x t _ s i z e , t a g _ s i z e ] [context\_size, tag\_size] [context_size,tag_size],经过以上公式的线性变换,就可以得到发射分数 e m i s s i o n _ s c o r e emission\_score emission_score,其中每个字词对应一行的标签分数(图3中只设置了三列,代表一共有3个标签),例如, x 0 x_0 x0对第一个标签的分数预测为 t 00 t_{00} t00,对第二个标签的分数预测为 t 01 t_{01} t01,对第三个标签的分数预测为 t 02 t_{02} t02,依次类推。
2.2.2 转移分数
下面我们来聊聊转移分数,这个转移分数表示一个标签向另一个标签转移的分数,分数越高,转移概率就越大,反之亦然。图4展示了记录转移分数的矩阵。
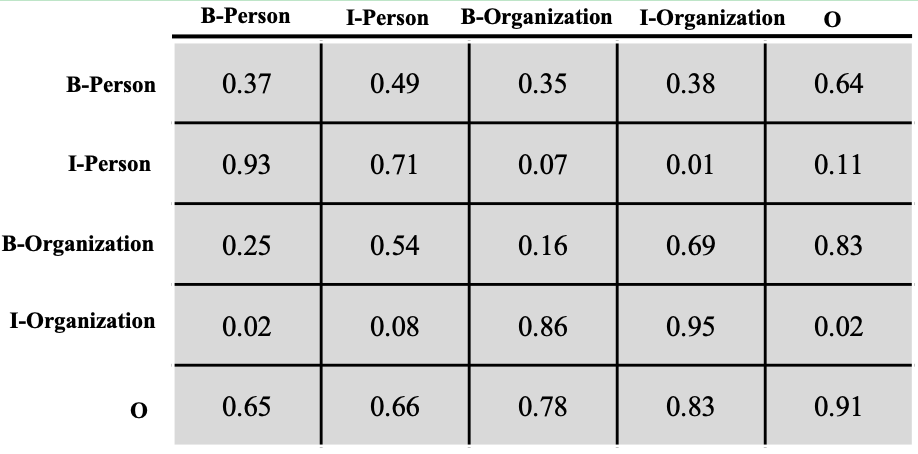
让我们从列到行地来看下这个转移矩阵 T T T,B-Person向I-Person转移的分数为0.93,B-Person向I-Organization转移的分数为0.02,前者的分数远远大于后者。I-Person向I-Person转移的概率是0.71,I-Organization向I-Organization转移的分数是0.95,因为一个人或者组织的名字往往包含多个字,所以这个概率相对是比较高的,这其实也是很符合我们直观认识的。
假设我们现在有个标签序列:B-Person, I-Person, O, O,B-Organization, I-Organization。那么这个序列的转移分数可按照如下方式计算:
S e q t = T I − P e r s o n , B − P e r s o n + T O , I − P e r s o n + T O , O + T O , B − O r g a n i z a t i o n + T B − O r g a n i z a t i o n , I − O r g a n i z a t i o n Seq_t = T_{I-Person,B-Person} + T_{O,I-Person} + T_{O,O} + T_{O,B-Organization} + T_{B-Organization, I-Organization} Seqt=TI−Person,B−Person+TO,I−Person+TO,O+TO,B−Organization+TB−Organization,I−Organization
这个转移分数矩阵是CRF中的一个可学习的参数矩阵,它的存在能够帮助我们显示地去建模标签之间的转移关系,提高命名实体识别的准确率。
2.3 CRF建模的损失函数
前边我们讲到,CRF能够帮助我们以一种全局的方式建模,在所有可能的路径中选择效果最优,分数最高的那条路径。那么我们应该怎么去建模这个策略呢,下面我们来具体谈谈。
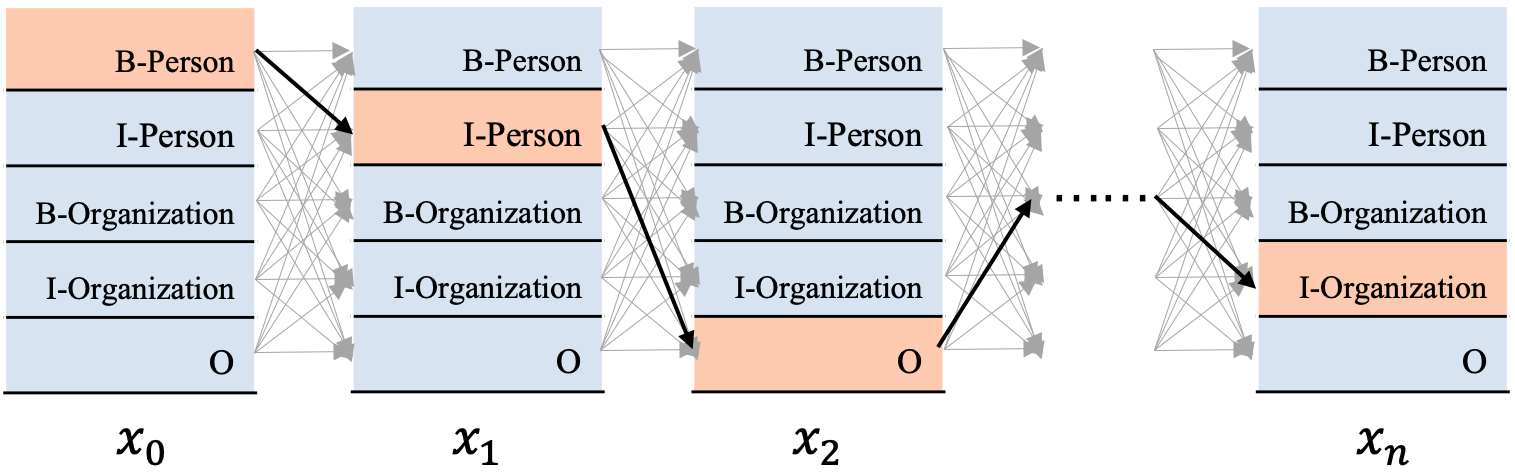
图5展示了CRF的工作图,现在我们有一串输入 x = [ x 0 , x 1 , x 2 , x n ] x=[x_0, x_1, x_2, x_n] x=[x0,x1,x2,xn](这里的 x x x是文本串对应的发射分数,每个字词 x i x_i xi都对应着一个发射分数向量,也就是前边提到的标签向量,该向量的维度就是标签数量),期待解码出相应的标签序列 y = [ y 0 , y 1 , y 2 , . . . , y n ] y=[y_0, y_1,y_2, ..., y_n] y=[y0,y1,y2,...,yn],形式化为对应的条件概率公式如下:
( y ∣ x ) = P ( y 0 , y 1 , . . . , y n ∣ x 0 , x 1 , . . . , x n ) (y|x) = P(y_0,y_1,...,y_n|x_0,x_1,...,x_n) (y∣x)=P(y0,y1,...,yn∣x0,x1,...,xn)
在第2节我们提到,CRF的解码策略在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的输出,假设标签数量是 k k k,文本长度是 n n n,显然会有 N = k n N=k^n N=kn条路径,若用 S i S_i Si代表第 i i i条路径的分数,那我们可以这样去算一个标签序列出现的概率:
P ( S i ) = e S i ∑ j N e S j P(S_i)=\frac{e^{S_i}}{\sum_j^{N}{e^{S_j}}} P(Si)=∑jNeSjeSi
现在我们有一条真实的路径 r e a l real real,即我们期待CRF解码出来的序列就是这一条。那它的分数可以表示为 s r e a l s_{real} sreal,它出现的概率就是:
P ( S r e a l ) = e S r e a l ∑ j N e S j P(S_{real})=\frac{e^{S_{real}}}{\sum_j^{N}{e^{S_j}}} P(Sreal)=∑jNeSjeSreal
所以我们建模学习的目的就是为了不断的提高 P ( S r e a l ) P(S_{real}) P(Sreal)的概率值,这就是我们的目标函数,当目标函数越大时,它对应的损失就应该越小,所以我们可以这样去建模它的损失函数:
l o s s = − P ( S r e a l ) = − e S r e a l ∑ j N e S j loss=-P(S_{real})=-\frac{e^{S_{real}}}{\sum_j^{N}{e^{S_j}}} loss=−P(Sreal)=−∑jNeSjeSreal
为方便求解,我们一般将这样的损失放到log空间去求解,因为log函数本身是单调递增的,所以它并不影响我们去迭代优化损失函数。
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ loss &= -log \…
千呼万唤始出来,这就是我们CRF建模的损失函数了。我们整个BiLSTM+CRF建模的目的就是为了让这个函数越来越小。从这个损失函数可以看出,这个损失函数包含两部分:单条真实路径的分数 S r e a l S_{real} Sreal,归一化项 l o g ( e S 1 + e S 2 + . . . + e S N ) log(e^{S_1}+e^{S_2}+...+e^{S_N}) log(eS1+eS2+...+eSN),即将全部的路径分数进行 l o g _ s u m _ e x p log\_sum\_exp log_sum_exp操作,即先将每条路径分数 S i S_i Si进行 e x p ( S i ) exp(S_i) exp(Si),然后再将所有的项加起来,最后取 l o g log log值。
讲到这里,有的同学可能会有疑惑,这里的每条路径分数应该怎么算呢?接下来,我们就来解决这个问题。
2.4 单条路径的分数计算
在开始之前,我们再来做一些约定,前边我们提到了发射分数和转移分数,假设 E E E代表发射分数矩阵, T T T代表转移分数矩阵, n n n代表文本序列长度, t a g _ s i z e tag\_size tag_size代表标签的数量。另外为方便书写,我们为每个标签编个id号(参考图5中涉及到的标签),如图6所示。

其中, E E E的shape为 [ n , t a g _ s i z e ] [n, tag\_size] [n,tag_size],每行对应着一个文本字词的发射分数,每列代表一个标签,例如, E 01 E_{01} E01代表 x 0 x_0 x0取id为1的标签分数, E 23 E_{23} E23代表 x 2 x_2 x2取id为3的标签分数。 T T T的shape为 [ t a g _ s i z e , t a g _ s i z e ] [tag\_size, tag\_size] [tag_size,tag_size],它代表了标签之间相互转移的分数,例如, T 03 T_{03} T03代表id为3的标签向id为0的标签转移分数。
每条路径的分数就是由对应的发射分数和转移分数组合而成的,对于图5标记出来的黄色路径来说, x 0 x_0 x0的标签是B-Person,对应的发射分数是 E 00 E_{00} E00, x 1 x_1 x1的标签是I-Person,对应的发射分数是 E 11 E_{11} E11,由B-Person向I-Person转移的分数是 T 10 T_{10} T10,因此到这一步的分数就是: E 00 + T 10 + E 11 E_{00}+T_{10}+E_{11} E00+T10+E11。
接下来 x 2 x_2 x2的标签是 O O O,由 x 1 x_1 x1的标签向I-Person向 x 2 x_2 x2的标签O转移的概率是 T 41 T_{41} T41,因此到这一步的分数是: E 00 + T 10 + E 11 + T 41 + E 24 E_{00}+T_{10}+E_{11}+T_{41}+E_{24} E00+T10+E11+T41+E24,依次类推,我们可以计算完整条路径的分数。假设第 i i i个位置对应的标签为 y i y_i yi,则整条路径的分数计算形式化公式为:
S r e a l = ∑ i = 0 n − 1 E i , y i + ∑ i = 0 n − 2 T y i + 1 , y i S_{real}=\sum_{i=0}^{n-1}{E_{i,y_i}} + \sum_{i=0}^{n-2}{T_{y_{i+1}, y_{i}}} Sreal=i=0∑n−1Ei,yi+i=0∑n−2Tyi+1,yi
2.5全部路径的分数计算
2.3节中的损失函数包括两项,单条真实路径分数的计算和归一化项(如上所述,全部路径分数的 l o g _ s u m _ e x p log\_sum\_exp log_sum_exp,为方便描述,后续直接将个归一化项描述为全部路径之和)的计算。这里你或许会问,现在知道了单条路径分数的计算方式,遍历一下所有的路径算个分数,不就可以轻松算出全部路径之和吗?是的,这在理论上是可行的。
但是,前边我们提到这个路径的数量是个指数级别的量纲,假设我对串包含50个字的文本串进行实体识别,标签的数量是31,那么这个路径的数量将是 3 1 50 31^{50} 3150条,这是真的是难以接受的一件事情,它会远远拖慢模型的训练和预测效率。
因此,我们要换一种高效的思路,这里其实用到了一种被称为前向算法的动态规划,它能帮助我们将图5所有路径的和计算,拆解为每个位置的和计算,最终得出所有的路径之和。如果这是你第一次听到这个算法,那也没关系,我会通过示例的方式,为你展现这个算法的工作原理,但是在看这部分内容之前,我们再来回顾一下我们的计算目标,即损失函数中的第1项:
l o g ( e S 1 + e S 2 + . . . + e S N ) log(e^{S_1}+e^{S_2}+...+e^{S_N}) log(eS1+eS2+...+eSN)
另外,为方便描述这个原理,我们来简化下这个问题,假设我们现在在计算图7所示的所有路径之和。
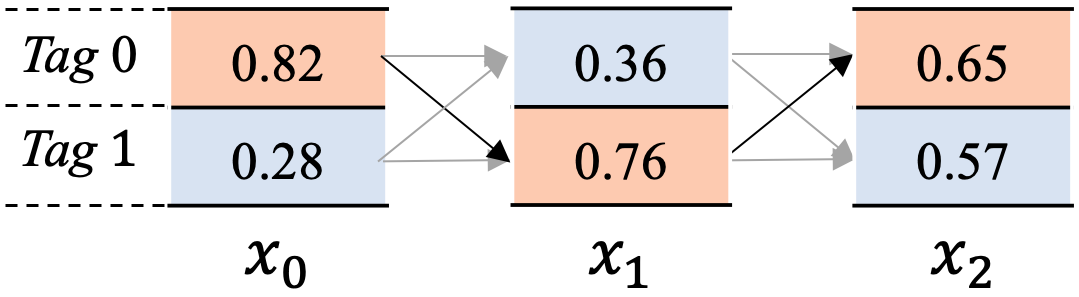
图7中,共包含2个标签 T a g Tag Tag 0 和 T a g Tag Tag 1, 文本串有3个单词 x 0 , x 1 , x 2 x_0, x_1, x_2 x0,x1,x2。我们再来做些约定如下:
e m i s s i o n i = [ x i 0 , x i 1 ] emission_i=[x_{i0},x_{i1}] emissioni=[xi0,xi1], 代表 x i x_i xi位置的发射分数。
其中, x i 0 x_{i0} xi0代表 x i x_i xi位置输出 T a g Tag Tag 0 标签的分数, x i 1 x_{i1} xi1代表 x i x_i xi位置输出 T a g Tag Tag 1 标签的分数。
$ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] $, 代表转移矩阵。
其中, t 01 t_{01} t01代表从 T a g Tag Tag 1 转移到 T a g Tag Tag 0的分数, t 10 t_{10} t10代表从 T a g Tag Tag 0 转移到 T a g Tag Tag 1的分数,依次类推。
a l p h a i = [ s i 0 , s i 1 ] alpha_i=[s_{i0},s_{i1}] alphai=[si0,si1], 其中各个数值代表到当前位置 x i x_i xi为止,以 x i x_i xi位置相应标签结尾的路径分数之和。
以 x 2 x_2 x2步为例, a l p h a 2 = [ s 20 , s 21 ] alpha_2=[s_{20},s_{21}] alpha2=[s20,s21],其中 s 20 s_{20} s20代表截止到 x 2 x_2 x2步骤为止,以标签 T a g Tag Tag 0 结尾所有的路径分数之和, s 21 s_{21} s21代表截止到 x 2 x_2 x2步骤为止,以标签 T a g Tag Tag 1结尾的所有路径分数之和。
这里比较抽象,如图7所示,参与 x 2 x_2 x2步的 s 20 s_{20} s20分数计算的路径包括4条,即 s 20 s_{20} s20是下边4条路径分数之和,依次如下
- x 00 , x 10 , x 20 x_{00},x_{10},x_{20} x00,x10,x20
- x 00 , x 11 , x 20 x_{00},x_{11},x_{20} x00,x11,x20
- x 01 , x 10 , x 20 x_{01},x_{10},x_{20} x01,x10,x20
- x 01 , x 11 , x 20 x_{01},x_{11},x_{20} x01,x11,x20
恭喜,我们完成了一些枯燥的定义,下边我们来看看如何计算所有路径的分数和吧,这里我们分成3步走来解释,首先计算截止到 x 0 x_0 x0位置,到各个标签的分数(上边的 a l p h a alpha alpha内容)是多少;截止到 x 1 x_1 x1位置,到各个标签的分数是多少;截止到 x 2 x_2 x2位置,到各个标签的分数是多少。
第1步,截止到 x 0 x_0 x0位置
当前位置 x 0 x_0 x0输入的发射分数为: e m i s s i o n 0 = [ x 00 , x 01 ] emission_0=[x_{00},x_{01}] emission0=[x00,x01],因为这是序列的起始,显然截止到 x 0 x_0 x0位置有: a l p h a 0 = [ x 00 , x 01 ] alpha_0=[x_{00},x_{01}] alpha0=[x00,x01]。
截止到 x 0 x_0 x0这一步,将 x 0 x_0 x0位置的所有标签的分数累计作为所有路径的分数为:
t o t a l 0 = l o g ( e x 00 + e x 01 ) total_0 = log(e^{x_{00}}+e^{x_{01}}) total0=log(ex00+ex01)
第2步,截止到 x 1 x_1 x1位置
当前步骤涉及到 x 0 x_0 x0向 x 1 x_1 x1位置的转移,在这个过程中, x 1 x_1 x1位置输入的发射分数为: e m i s s i o n 1 = [ x 10 , x 11 ] emission_1=[x_{10}, x_{11}] emission1=[x10,x11], 转移概率矩阵为: $ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] , 前 一 个 位 置 , 前一个位置 ,前一个位置x_0 各 标 签 的 路 径 累 计 和 各标签的路径累计和 各标签的路径累计和alpha_0=[x_{00},x_{01}]$。
接下来我们expand一下 e m i s s i o n 1 emission_1 emission1 和 a l p h a 0 alpha_0 alpha0,力求通过矩阵计算的方式一次完成当前位置 x 1 x_1 x1各个标签的路径累计 a l p h a 1 alpha_1 alpha1,具体如下:
e m i s s i o n 1 = [ x 10 x 10 x 11 x 11 ] emission_1 = \left[ \begin{matrix} x_{10} & x_{10}\\ x_{11} & x_{11} \end{matrix} \right] emission1=[x10x11x10x11]
a l p h a 0 = [ x 00 x 01 x 00 x 01 ] alpha_0 = \left[ \begin{matrix} x_{00} & x_{01}\\ x_{00} & x_{01} \end{matrix} \right] alpha0=[x00x00x01x01]
然后我们来计算截止到 x 1 x_1 x1位置,到不同标签的每条路径的分数:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ scores &= alph…
我们来看一条路径分数的计算,例如$ x_{00}+t_{10}+x_{11} , 它 代 表 在 , 它代表在 ,它代表在x_0 的 位 置 标 签 为 的位置标签为 的位置标签为Tag$ 0,在 x 1 x_1 x1的位置标签为 T a g Tag Tag 1,然后通过加上 t 10 t_{10} t10完成了 x 0 x_0 x0位置 T a g Tag Tag 0标签 向 x 1 x_1 x1位置标签 T a g Tag Tag 1的转移。
从上边的结果可以看到,第1行代表向当前位置 x 1 x_1 x1标签 T a g Tag Tag 0的转移路径,第2行代表向当前位置 x 1 x_1 x1标签 T a g Tag Tag 1的转移路径。以第1行为例,将第1行的路径分数相加,就相当于到当前位置 x 1 x_1 x1并且以 T a g Tag Tag 0结尾的所有路径之和。
因此,这样我们可以容易地算出当前位置 x 1 x_1 x1的各个标签的路径累计分数 a l p h a 1 alpha_1 alpha1:
a l p h a 1 = [ l o g ( e x 00 + t 00 + x 10 + e x 01 + t 01 + x 10 ) , l o g ( e x 00 + t 10 + x 11 + e x 01 + t 11 + x 11 ) ] alpha_1 = [log(e^{x_{00}+t_{00}+x_{10}}+e^{x_{01}+t_{01}+x_{10}}), log(e^{x_{00}+t_{10}+x_{11}}+e^{x_{01}+t_{11}+x_{11}})] alpha1=[log(ex00+t00+x10+ex01+t01+x10),log(ex00+t10+x11+ex01+t11+x11)]
最后,我们来算下截止到 x 1 x_1 x1位置,所有的路径和:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ total_1 &= log…
再回顾一下我们的计算目标: l o g ( e S 1 + e S 2 + . . . + e S N ) log(e^{S_1}+e^{S_2}+...+e^{S_N}) log(eS1+eS2+...+eSN),你可以看到如果图7最终只到 x 1 x_1 x1位置,那么上边的这个结果就是我们相求的全部路径之和,或者说是归一化项。
第3步,截止到 x 2 x_2 x2位置
我们再来看下 x 2 x_2 x2位置的一些输入信息, x 2 x_2 x2位置输入的发射分数为: e m i s s i o n 2 = [ x 20 , x 21 ] emission_2=[x_{20}, x_{21}] emission2=[x20,x21], 转移概率矩阵为: $ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] , 前 一 个 位 置 , 前一个位置 ,前一个位置x_1 各 标 签 的 路 径 累 计 和 各标签的路径累计和 各标签的路径累计和alpha_1=[log(e{x_{00}+t_{00}+x_{10}}+e{x_{01}+t_{01}+x_{10}}), log(e{x_{00}+t_{10}+x_{11}}+e{x_{01}+t_{11}+x_{11}})]$。
接下来继续expand一下 e m i s s i o n 2 emission_2 emission2 和 a l p h a 1 alpha_1 alpha1,力求通过矩阵计算的方式一次完成当前位置 x 2 x_2 x2各个标签的路径累计 a l p h a 2 alpha_2 alpha2,具体如下:
e m i s s i o n 2 = [ x 20 x 20 x 21 x 21 ] emission_2 = \left[ \begin{matrix} x_{20} & x_{20}\\ x_{21} & x_{21} \end{matrix} \right] emission2=[x20x21x20x21]
a l p h a 1 = [ l o g ( e x 00 + t 00 + x 10 + e x 01 + t 01 + x 10 ) l o g ( e x 00 + t 10 + x 11 + e x 01 + t 11 + x 11 ) l o g ( e x 00 + t 00 + x 10 + e x 01 + t 01 + x 10 ) l o g ( e x 00 + t 10 + x 11 + e x 01 + t 11 + x 11 ) ] alpha_1 = \left[ \begin{matrix} log(e^{x_{00}+t_{00}+x_{10}}+e^{x_{01}+t_{01}+x_{10}}) & log(e^{x_{00}+t_{10}+x_{11}}+e^{x_{01}+t_{11}+x_{11}}) \\ log(e^{x_{00}+t_{00}+x_{10}}+e^{x_{01}+t_{01}+x_{10}}) & log(e^{x_{00}+t_{10}+x_{11}}+e^{x_{01}+t_{11}+x_{11}}) \end{matrix} \right] alpha1=[log(ex00+t00+x10+ex01+t01+x10)log(ex00+t00+x10+ex01+t01+x10)log(ex00+t10+x11+ex01+t11+x11)log(ex00+t10+x11+ex01+t11+x11)]
然后我们来计算截止到 x 2 x_2 x2位置,到不同标签的每条路径的分数:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ scores &= alph…
继续按行累加,算出到当前位置 x 2 x_2 x2的各个标签的路径累计分数 a l p h a 2 alpha_2 alpha2:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ alpha_2 &= [lo…
最后,我们来算下截止到 x 2 x_2 x2位置,所有的路径和:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ total_2 &= log…
显然,这个式子的结果就是最终我们想要的计算目标,损失函数中的第1项,共计包含8条路径的分数。
2.6 CRF的Viterbi解码
在前边几节,我们讲过了CRF的损失函数、单条路径分数的计算、全部路径分数的计算,根据这些内容完全可以进行BiLSTM+CRF的训练。但是,我们如何使用CRF从全部的路径中解码出得分最高的那条路径呢?
同2.5节所述,计算全部路径分数后,选择得分最大的那条路径肯定是不行的。其实这里是使用了一种被称为Viterbi的算法,它的思想和2.5节介绍的前向算法有些类似,将从全部路径中查找最优路径的过程,拆解为选择每个位置累计的最大路径。如果这是你第一次接触Viterbi算法,也不用担心,本节依然会通过示例的方式展现这个算法原理。
我们依然以图7为例,解码这全部路径中分数最大的这条(图中橙色显示的这条路径)。在正式介绍之前,我们依然做些约定如下:
e m i s s i o n i = [ x i 0 , x i 1 ] emission_i=[x_{i0},x_{i1}] emissioni=[xi0,xi1], 代表 x i x_i xi位置的发射分数。
其中, x i 0 x_{i0} xi0代表 x i x_i xi位置输出 T a g Tag Tag 0 标签的分数, x i 1 x_{i1} xi1代表 x i x_i xi位置输出 T a g Tag Tag 1 标签的分数。
$ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] $, 代表转移矩阵。
其中, t 01 t_{01} t01代表从 T a g Tag Tag 1 转移到 T a g Tag Tag 0的分数, t 10 t_{10} t10代表从 T a g Tag Tag 0 转移到 T a g Tag Tag 1的分数,依次类推。
a l p h a i = [ s i 0 , s i 1 ] alpha_i=[s_{i0},s_{i1}] alphai=[si0,si1], 其中各个数值代表到当前位置 x i x_i xi为止,以当前位置 x i x_i xi相应标签结尾的路径中,取得最大分数的路径得分。
以 x 2 x_2 x2位置为例, a l p h a 2 = [ s 20 , s 21 ] alpha_2=[s_{20},s_{21}] alpha2=[s20,s21],其中 s 20 s_{20} s20代表截止到 x 2 x_2 x2步骤为止,以标签 T a g Tag Tag 0 结尾所有的路径中得分最大的路径分数, s 21 s_{21} s21代表截止到 x 2 x_2 x2步骤为止,以标签 T a g Tag Tag 1结尾的所有路径中得分最大的路径分数。
这里比较抽象,如图7所示,参与 x 2 x_2 x2步的 s 20 s_{20} s20分数计算的路径包括4条, s 20 s_{20} s20是这4条路径中得分最大这一条对应的分数,即下边这一条路径: x 00 , x 11 , x 20 x_{00},x_{11},x_{20} x00,x11,x20。
b e t a i = [ p i 0 , p i 1 ] beta_i = [p_{i0},p_{i1}] betai=[pi0,pi1],其中各个数值代表到当前位置 x i x_i xi为止,以当前位置 x i x_i xi相应标签结尾的路径中,分数最大的那一条路径在前一个位置 x i − 1 x_{i-1} xi−1的标签索引(每个标签对应的id号)。
以 x 2 x_2 x2位置为例, b e t a 2 = [ p 20 , p 21 ] beta_2 = [p_{20},p_{21}] beta2=[p20,p21],其中 p 20 p_{20} p20代表代表截止到 x 2 x_2 x2步骤为止,以标签 T a g Tag Tag 0 结尾所有的路径中得分最大的那条路径在 x i − 1 x_{i-1} xi−1位置的标签索引,同理 p 21 p_{21} p21代表截止到 x 2 x_2 x2步骤为止,以标签 T a g Tag Tag 1结尾的最大路径在 x i − 1 x_{i-1} xi−1位置的标签索引。
同样,如图7所示,在 x 2 x_2 x2位置,到标签 T a g Tag Tag 0的所有路径中,分数最大的路径是: x 00 , x 11 , x 20 x_{00},x_{11},x_{20} x00,x11,x20,因为前一个位置 x i − 1 x_{i-1} xi−1的标签是 T a g Tag Tag 1,因此 p 20 = 1 p_{20}=1 p20=1。
恭喜,我们又一次完成了这些枯燥的定义,下边我们来看看如何选择所有路径中得分最大的这一条吧,这里我们同样分成3步走来解释,首先计算截止到 x 0 x_0 x0位置,到各个标签的最大得分(上边的 a l p h a alpha alpha内容)是多少;截止到 x 1 x_1 x1位置,到各个标签的最大得分是多少;截止到 x 2 x_2 x2位置,到各个标签的最大得分是多少。
第1步,截止到 x 0 x_0 x0位置
当前位置 x 0 x_0 x0输入的发射分数为: e m i s s i o n 0 = [ x 00 , x 01 ] emission_0=[x_{00},x_{01}] emission0=[x00,x01],因为这是序列的起始,显然截止到 x 0 x_0 x0位置有: a l p h a 0 = [ x 00 , x 01 ] alpha_0=[x_{00},x_{01}] alpha0=[x00,x01]
另外因为起始位置前边没有路径,这里我们使用-1来初始化: b e t a 0 = [ − 1 , − 1 ] beta_0=[-1,-1] beta0=[−1,−1]
第2步,截止到 x 1 x_1 x1位置
当前步骤涉及到 x 0 x_0 x0向 x 1 x_1 x1位置的转移,在这个过程中, x 1 x_1 x1位置输入的发射分数为: e m i s s i o n 1 = [ x 10 , x 11 ] emission_1=[x_{10}, x_{11}] emission1=[x10,x11], 转移概率矩阵为: $ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] , 到 前 一 个 位 置 , 到前一个位置 ,到前一个位置x_0 各 标 签 的 最 大 路 径 得 分 为 各标签的最大路径得分为 各标签的最大路径得分为alpha_0=[x_{00},x_{01}]$。
接下来按照2.5节同样的方式,我们expand一下 e m i s s i o n 1 emission_1 emission1 和 a l p h a 0 alpha_0 alpha0,力求通过矩阵计算的方式一次完成到当前位置 x 1 x_1 x1各个标签的所有路径中得分最大的路径分数 a l p h a 1 alpha_1 alpha1,具体如下:
e m i s s i o n 1 = [ x 10 x 10 x 11 x 11 ] emission_1 = \left[ \begin{matrix} x_{10} & x_{10}\\ x_{11} & x_{11} \end{matrix} \right] emission1=[x10x11x10x11]
a l p h a 0 = [ x 00 x 01 x 00 x 01 ] alpha_0 = \left[ \begin{matrix} x_{00} & x_{01}\\ x_{00} & x_{01} \end{matrix} \right] alpha0=[x00x00x01x01]
然后我们来计算截止到 x 1 x_1 x1位置,到不同标签的每条路径的分数:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ scores &= alph…
同样地,以第1行为例,第1行代表到当前位置 x 1 x_1 x1标签 T a g Tag Tag 0结尾的所有路径的得分,那么第1行中分数最大这一条路径,就是到当前位置 x 1 x_1 x1并且以 T a g Tag Tag 0结尾的所有路径中得分最大的路径。
因此,这样我们可以容易地算出到当前位置 x 1 x_1 x1的各个标签的最大路径分数 a l p h a 1 alpha_1 alpha1:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ alpha_1 &= [ma…
显然从上边结果中,我们能够分析出到 x 1 x_1 x1位置各个标签的最大路径,例如到$Tag $ 0的路径有 x 00 + t 00 + x 10 x_{00}+t_{00}+x_{10} x00+t00+x10 和 $ x_{01}+t_{01}+x_{10} , 其 中 较 大 者 就 是 我 们 想 要 的 到 , 其中较大者就是我们想要的到 ,其中较大者就是我们想要的到x_1$位置 $Tag $ 0的最大路径。
这里不妨我们做个假设:
- x 00 + t 00 + x 10 < x 01 + t 01 + x 10 x_{00}+t_{00}+x_{10} < x_{01}+t_{01}+x_{10} x00+t00+x10<x01+t01+x10
- x 00 + t 10 + x 11 > x 01 + t 11 + x 11 x_{00}+t_{10}+x_{11} > x_{01}+t_{11}+x_{11} x00+t10+x11>x01+t11+x11
因此,我们可以获得 x 1 x_1 x1位置的索引 b e t a 1 = [ 1 , 0 ] beta_1=[1,0] beta1=[1,0],这代表在 x 1 x_1 x1位置,到标签 T a g Tag Tag 0的最大路径的前一个位置 x i − 1 x_{i-1} xi−1的标签是 T a g Tag Tag 1, 到标签 T a g Tag Tag 1的最大路径的前一个位置 x i − 1 x_{i-1} xi−1的标签是 T a g Tag Tag 0。
第3步,截止到 x 2 x_2 x2位置
我们再来看下 x 2 x_2 x2位置的一些输入信息, x 2 x_2 x2位置输入的发射分数为: e m i s s i o n 2 = [ x 20 , x 21 ] emission_2=[x_{20}, x_{21}] emission2=[x20,x21], 转移概率矩阵为: $ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] , 前 一 个 位 置 , 前一个位置 ,前一个位置x_1 各 标 签 的 路 径 累 计 和 : 各标签的路径累计和: 各标签的路径累计和:alpha_1=[max(x_{00}+t_{00}+x_{10}, x_{01}+t_{01}+x_{10}), max(x_{00}+t_{10}+x_{11}, x_{01}+t_{11}+x_{11})]$。
接下来继续expand一下 e m i s s i o n 2 emission_2 emission2 和 a l p h a 1 alpha_1 alpha1,力求通过矩阵计算的方式一次完成当前位置 x 2 x_2 x2各个标签的路径累计 a l p h a 2 alpha_2 alpha2,具体如下:
e m i s s i o n 2 = [ x 20 x 20 x 21 x 21 ] emission_2 = \left[ \begin{matrix} x_{20} & x_{20}\\ x_{21} & x_{21} \end{matrix} \right] emission2=[x20x21x20x21]
a l p h a 1 = [ m a x ( x 00 + t 00 + x 10 , x 01 + t 01 + x 10 ) m a x ( x 00 + t 10 + x 11 , x 01 + t 11 + x 11 ) m a x ( x 00 + t 00 + x 10 , x 01 + t 01 + x 10 ) m a x ( x 00 + t 10 + x 11 , x 01 + t 11 + x 11 ) ] alpha_1 = \left[ \begin{matrix} max(x_{00}+t_{00}+x_{10}, x_{01}+t_{01}+x_{10}) & max(x_{00}+t_{10}+x_{11}, x_{01}+t_{11}+x_{11}) \\ max(x_{00}+t_{00}+x_{10}, x_{01}+t_{01}+x_{10}) & max(x_{00}+t_{10}+x_{11}, x_{01}+t_{11}+x_{11}) \end{matrix} \right] alpha1=[max(x00+t00+x10,x01+t01+x10)max(x00+t00+x10,x01+t01+x10)max(x00+t10+x11,x01+t11+x11)max(x00+t10+x11,x01+t11+x11)]
然后我们来计算截止到 x 2 x_2 x2位置,到不同标签的每条路径的分数:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ scores &= alph…
因此,这样我们可以容易地算出到当前位置 x 2 x_2 x2的各个标签的最大路径分数 a l p h a 2 alpha_2 alpha2:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ alpha_1 &= [ma…
这里我不妨再假设:
-
m a x ( x 00 + t 00 + x 10 , x 01 + t 01 + x 10 ) + t 00 + x 20 > m a x ( x 00 + t 10 + x 11 , x 01 + t 11 + x 11 ) + t 01 + x 20 ) max(x_{00}+t_{00}+x_{10}, x_{01}+t_{01}+x_{10}) +t_{00}+x_{20} > max(x_{00}+t_{10}+x_{11}, x_{01}+t_{11}+x_{11})+t_{01}+x_{20}) max(x00+t00+x10,x01+t01+x10)+t00+x20>max(x00+t10+x11,x01+t11+x11)+t01+x20)
-
m a x ( x 00 + t 00 + x 10 , x 01 + t 01 + x 10 ) + t 10 + x 21 < m a x ( x 00 + t 10 + x 11 , x 01 + t 11 + x 11 ) + t 11 + x 21 ) max(x_{00}+t_{00}+x_{10}, x_{01}+t_{01}+x_{10})+t_{10}+x_{21} < max(x_{00}+t_{10}+x_{11}, x_{01}+t_{11}+x_{11}) +t_{11}+x_{21} ) max(x00+t00+x10,x01+t01+x10)+t10+x21<max(x00+t10+x11,x01+t11+x11)+t11+x21)
上一步我们曾假设:
- x 00 + t 00 + x 10 < x 01 + t 01 + x 10 x_{00}+t_{00}+x_{10} < x_{01}+t_{01}+x_{10} x00+t00+x10<x01+t01+x10
- x 00 + t 10 + x 11 > x 01 + t 11 + x 11 x_{00}+t_{10}+x_{11} > x_{01}+t_{11}+x_{11} x00+t10+x11>x01+t11+x11
因此有:
- x 01 + t 01 + x 10 + t 01 + x 10 < x 00 + t 10 + x 11 + t 01 + x 20 x_{01}+t_{01}+x_{10}+t_{01}+x_{10} < x_{00}+t_{10}+x_{11}+t_{01}+x_{20} x01+t01+x10+t01+x10<x00+t10+x11+t01+x20
- x 01 + t 01 + x 10 + t 10 + x 21 > x 00 + t 10 + x 11 + t 11 + x 21 x_{01}+t_{01}+x_{10}+t_{10}+x_{21} > x_{00}+t_{10}+x_{11}+t_{11}+x_{21} x01+t01+x10+t10+x21>x00+t10+x11+t11+x21
所以 x 2 x_2 x2位置的索引: b e t a 2 = [ 1 , 0 ] beta_2 = [1,0] beta2=[1,0]
此时: a l p h a 1 = [ x 00 + t 10 + x 11 + t 01 + x 20 , x 01 + t 01 + x 10 + t 10 + x 21 ] alpha_1=[x_{00}+t_{10}+x_{11}+t_{01}+x_{20}, x_{01}+t_{01}+x_{10}+t_{10}+x_{21} ] alpha1=[x00+t10+x11+t01+x20,x01+t01+x10+t10+x21]
在图7中橘色路径分数最高,其对应的是 x 00 + t 10 + x 11 + t 01 + x 20 x_{00}+t_{10}+x_{11}+t_{01}+x_{20} x00+t10+x11+t01+x20,因此再假设:
x 00 + t 10 + x 11 + t 01 + x 20 > x 01 + t 01 + x 10 + t 10 + x 21 x_{00}+t_{10}+x_{11}+t_{01}+x_{20} > x_{01}+t_{01}+x_{10}+t_{10}+x_{21} x00+t10+x11+t01+x20>x01+t01+x10+t10+x21
这其实代表在 x 2 x_2 x2位置的所有标签对应的最大路径中, T a g Tag Tag 0 对应的那条路径是最大的,这条路径也是全局所有路径中分数最大的那一条,是我们要解析出的期望路径。
第4步,开始解码标签序列
到现在位置,我们通过 b e t a 0 beta_0 beta0记录下了最大路径上的节点,接下来我们可以通过回溯来找出全局所有路径中的最大路径。
首先,在 x 2 x_2 x2位置所有标签对应的最大路径中, T a g Tag Tag 0 对应的路径分数最大。因此 x 2 x_2 x2位置对应的标签就是 T a g Tag Tag 0。
然后, b e t a 2 = [ 1 , 0 ] beta_2 = [1,0] beta2=[1,0],因此 x 2 x_2 x2位置解析出的标签 T a g Tag Tag 0,对应的上一位置 x 1 x_1 x1的标签是 T a g Tag Tag 1。
接下来, b e t a 1 = [ 1 , 0 ] beta_1=[1,0] beta1=[1,0],因此 x 1 x_1 x1位置解析出的标签 T a g Tag Tag 1,对应的上一位置 x 0 x_0 x0的标签是 T a g Tag Tag 0。
最后, b e t a 0 = [ − 1 , − 1 ] beta_0=[-1,-1] beta0=[−1,−1],当解析到这一步的时候,反回的标签肯定是-1,因此这个回溯过程也就结束了。
当回溯完成之后,将解析出的结果倒序排序,就是我们期望的最大路径。以图7为例,该路径就是 T a g Tag Tag 0 --> T a g Tag Tag 1 --> T a g Tag Tag 0。
恭喜,看到这里,相信你已经懂得了CRF的核心原理。江湖虽路远,但总会再见,如对笔者的文章满意,还请多多支持。
BiLSTM-Pytorch实现
# Author: Robert Guthrie
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(1)
def argmax(vec):
# return the argmax as a python int
_, idx = torch.max(vec, 1)
return idx.item()
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
# Compute log sum exp in a numerically stable way for the forward algorithm
def log_sum_exp(vec):
max_score = vec[0, argmax(vec)]
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
return max_score + \
torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# Maps the output of the LSTM into tag space.
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# Matrix of transition parameters. Entry i,j is the score of
# transitioning *to* i *from* j.
self.transitions = nn.Parameter(
torch.randn(self.tagset_size, self.tagset_size))
# These two statements enforce the constraint that we never transfer
# to the start tag and we never transfer from the stop tag
self.transitions.data[tag_to_ix[START_TAG], :] = -10000
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000
self.hidden = self.init_hidden()
def init_hidden(self):
return (torch.randn(2, 1, self.hidden_dim // 2),
torch.randn(2, 1, self.hidden_dim // 2))
def _forward_alg(self, feats):
# Do the forward algorithm to compute the partition function
init_alphas = torch.full((1, self.tagset_size), -10000.)
# START_TAG has all of the score.
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# Wrap in a variable so that we will get automatic backprop
forward_var = init_alphas
# Iterate through the sentence
for feat in feats:
alphas_t = [] # The forward tensors at this timestep
for next_tag in range(self.tagset_size):
# broadcast the emission score: it is the same regardless of
# the previous tag
emit_score = feat[next_tag].view(
1, -1).expand(1, self.tagset_size)
# the ith entry of trans_score is the score of transitioning to
# next_tag from i
trans_score = self.transitions[next_tag].view(1, -1)
# The ith entry of next_tag_var is the value for the
# edge (i -> next_tag) before we do log-sum-exp
next_tag_var = forward_var + trans_score + emit_score
# The forward variable for this tag is log-sum-exp of all the
# scores.
alphas_t.append(log_sum_exp(next_tag_var).view(1))
forward_var = torch.cat(alphas_t).view(1, -1)
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
alpha = log_sum_exp(terminal_var)
return alpha
def _get_lstm_features(self, sentence):
self.hidden = self.init_hidden()
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
def _score_sentence(self, feats, tags):
# Gives the score of a provided tag sequence
score = torch.zeros(1)
tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long), tags])
for i, feat in enumerate(feats):
score = score + \
self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score
def _viterbi_decode(self, feats):
backpointers = []
# Initialize the viterbi variables in log space
init_vvars = torch.full((1, self.tagset_size), -10000.)
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# forward_var at step i holds the viterbi variables for step i-1
forward_var = init_vvars
for feat in feats:
bptrs_t = [] # holds the backpointers for this step
viterbivars_t = [] # holds the viterbi variables for this step
for next_tag in range(self.tagset_size):
# next_tag_var[i] holds the viterbi variable for tag i at the
# previous step, plus the score of transitioning
# from tag i to next_tag.
# We don't include the emission scores here because the max
# does not depend on them (we add them in below)
next_tag_var = forward_var + self.transitions[next_tag]
best_tag_id = argmax(next_tag_var)
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
# Now add in the emission scores, and assign forward_var to the set
# of viterbi variables we just computed
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t)
# Transition to STOP_TAG
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# Follow the back pointers to decode the best path.
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# Pop off the start tag (we dont want to return that to the caller)
start = best_path.pop()
assert start == self.tag_to_ix[START_TAG] # Sanity check
best_path.reverse()
return path_score, best_path
def neg_log_likelihood(self, sentence, tags):
feats = self._get_lstm_features(sentence)
forward_score = self._forward_alg(feats)
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
def forward(self, sentence): # dont confuse this with _forward_alg above.
# Get the emission scores from the BiLSTM
lstm_feats = self._get_lstm_features(sentence)
# Find the best path, given the features.
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
START_TAG = "<START>"
STOP_TAG = "<STOP>"
EMBEDDING_DIM = 5
HIDDEN_DIM = 4
# Make up some training data
training_data = [(
"the wall street journal reported today that apple corporation made money".split(),
"B I I I O O O B I O O".split()
), (
"georgia tech is a university in georgia".split(),
"B I O O O O B".split()
)]
word_to_ix = {}
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
tag_to_ix = {"B": 0, "I": 1, "O": 2, START_TAG: 3, STOP_TAG: 4}
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# Check predictions before training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
precheck_tags = torch.tensor([tag_to_ix[t] for t in training_data[0][1]], dtype=torch.long)
print(model(precheck_sent))
# Make sure prepare_sequence from earlier in the LSTM section is loaded
for epoch in range(
300): # again, normally you would NOT do 300 epochs, it is toy data
for sentence, tags in training_data:
# Step 1. Remember that Pytorch accumulates gradients.
# We need to clear them out before each instance
model.zero_grad()
# Step 2. Get our inputs ready for the network, that is,
# turn them into Tensors of word indices.
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# Step 3. Run our forward pass.
loss = model.neg_log_likelihood(sentence_in, targets)
# Step 4. Compute the loss, gradients, and update the parameters by
# calling optimizer.step()
loss.backward()
optimizer.step()
# Check predictions after training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
print(model(precheck_sent))
# We got it!
输出如下:
(tensor(2.6907), [1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1])
(tensor(20.4906), [0, 1, 1, 1, 2, 2, 2, 0, 1, 2, 2])
4. Reference
[1] 邱锡鹏. 神经网络与深度学习[M]. 北京:机械工业出版社,2021.
[2] 吴飞. 人工智能导论:模型与算法[M]. 北京:高等教育出版社,2020.
[3] CRF Layer on the Top of BiLSTM
[3] ADVANCED: MAKING DYNAMIC DECISIONS AND THE BI-LSTM CRF