1 前言

模型名:BiLSTM-CRF
论文参考:
Bidirectional LSTM-CRF Models for Sequence Tagging
Neural Architectures for Named Entity Recognition
使用数据集:
https://www.datafountain.cn/competitions/529/ranking
Tips:文章可能存在一些漏洞,欢迎留言指出
2 数据准备
导包、路径、超参数、预设常量
import pandas as pd
import torch
import pickle
import os
from torch import optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from bilstm_crf import BiLSTM_CRF, NerDataset, NerDatasetTest
from sklearn.metrics import f1_score
# 路径
TRAIN_PATH = './dataset/train_data_public.csv'
TEST_PATH = './dataset/test_public.csv'
VOCAB_PATH = './data/vocab.txt'
WORD2INDEX_PATH = './data/word2index.pkl'
MODEL_PATH = './model/bilstm_crf.pkl'
# 超参数
MAX_LEN = 60
BATCH_SIZE = 8
EMBEDDING_DIM = 120
HIDDEN_DIM = 12
EPOCH = 5
# 预设
# 设备
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
# tag2index
tag2index = {
"O": 0, # 其他
"B-BANK": 1, "I-BANK": 2, # 银行实体
"B-PRODUCT": 3, "I-PRODUCT": 4, # 产品实体
"B-COMMENTS_N": 5, "I-COMMENTS_N": 6, # 用户评论,名词
"B-COMMENTS_ADJ": 7, "I-COMMENTS_ADJ": 8 # 用户评论,形容词
}
# 预设标签
unk_flag = '[UNK]' # 未知
pad_flag = '[PAD]' # 填充
start_flag = '[STA]' # 开始
end_flag = '[END]' # 结束
生成word2index字典、加载数据集
# 生成word2index词典
def create_word2index():
if not os.path.exists(WORD2INDEX_PATH): # 如果文件不存在,则生成word2index
word2index = dict()
with open(VOCAB_PATH, 'r', encoding='utf8') as f:
for word in f.readlines():
word2index[word.strip()] = len(word2index) + 1
with open(WORD2INDEX_PATH, 'wb') as f:
pickle.dump(word2index, f)
# 数据准备
def data_prepare():
# 加载训练集、测试集
train_dataset = pd.read_csv(TRAIN_PATH, encoding='utf8')
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')
return train_dataset, test_dataset
3 数据处理
文本、标签转换为索引(训练集)
流程:
( 1 )提取预设标签索引 ( 2 )初步生成文本对应的索引,需要在头和尾分别加入 s t a r t i n d e x 和 e n d i n d e x ,初步生成标签对应的索引,同理,在头和尾加入 0 ( 3 )对文本和标签索引按照长度执行操作:低于 m a x l e n 则填充,超过 m a x l e n 则截断 ( 4 )根据 t e x t i n d e x 生成 m a s k ( 5 )将每一个 r o w 的 t e x t i n d e x 、 t a g i n d e x 、 m a s k 加入到对应的 l i s t 中 ( 6 )将 t e x t s 、 t a g s 、 m a s k s 转化为 t e n s o r 格式 \textcolor{purple}{ (1)提取预设标签索引\\ (2)初步生成文本对应的索引,需要在头和尾分别加入start_index和end_index,初步生成标签对应的索引,同理,在头和尾加入0\\ (3)对文本和标签索引按照长度执行操作:低于max_len则填充,超过max_len则截断\\ (4)根据text_index生成mask\\ (5)将每一个row的text_index、tag_index、mask加入到对应的list中\\ (6)将texts、tags、masks转化为tensor格式 } (1)提取预设标签索引(2)初步生成文本对应的索引,需要在头和尾分别加入startindex和endindex,初步生成标签对应的索引,同理,在头和尾加入0(3)对文本和标签索引按照长度执行操作:低于maxlen则填充,超过maxlen则截断(4)根据textindex生成mask(5)将每一个row的textindex、tagindex、mask加入到对应的list中(6)将texts、tags、masks转化为tensor格式
# 文本、标签转化为索引(训练集)
def text_tag_to_index(dataset, word2index):
# 预设索引
unk_index = word2index.get(unk_flag)
pad_index = word2index.get(pad_flag)
start_index = word2index.get(start_flag, 2)
end_index = word2index.get(end_flag, 3)
texts, tags, masks = [], [], []
n_rows = len(dataset) # 行数
for row in tqdm(range(n_rows)):
text = dataset.iloc[row, 1]
tag = dataset.iloc[row, 2]
# 文本对应的索引
text_index = [start_index] + [word2index.get(w, unk_index) for w in text] + [end_index]
# 标签对应的索引
tag_index = [0] + [tag2index.get(t) for t in tag.split()] + [0]
# 填充或截断句子至标准长度
if len(text_index) < MAX_LEN: # 句子短,填充
pad_len = MAX_LEN - len(text_index)
text_index += pad_len * [pad_index]
tag_index += pad_len * [0]
elif len(text_index) > MAX_LEN: # 句子长,截断
text_index = text_index[:MAX_LEN - 1] + [end_index]
tag_index = tag_index[:MAX_LEN - 1] + [0]
# 转换为mask
def _pad2mask(t):
return 0 if t == pad_index else 1
# mask
mask = [_pad2mask(t) for t in text_index]
# 加入列表中
texts.append(text_index)
tags.append(tag_index)
masks.append(mask)
# 转换为tensor
texts = torch.LongTensor(texts)
tags = torch.LongTensor(tags)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts, tags, masks
文本转换为索引(测试集)
测试集同上,没有标签
# 文本转化为索引(测试集)
def text_to_index(dataset, word2index):
# 预设索引
unk_index = word2index.get(unk_flag)
pad_index = word2index.get(pad_flag)
start_index = word2index.get(start_flag, 2)
end_index = word2index.get(end_flag, 3)
texts, masks = [], []
n_rows = len(dataset) # 行数
for row in tqdm(range(n_rows)):
text = dataset.iloc[row, 1]
# 文本对应的索引
text_index = [start_index] + [word2index.get(w, unk_index) for w in text] + [end_index]
# 填充或截断句子至标准长度
if len(text_index) < MAX_LEN: # 句子短,填充
pad_len = MAX_LEN - len(text_index)
text_index += pad_len * [pad_index]
elif len(text_index) > MAX_LEN: # 句子长,截断
text_index = text_index[:MAX_LEN - 1] + [end_index]
# 转换为mask
def _pad2mask(t):
return 0 if t == pad_index else 1
# mask
mask = [_pad2mask(t) for t in text_index]
masks.append(mask)
# 加入列表中
texts.append(text_index)
# 转换为tensor
texts = torch.LongTensor(texts)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts, masks
4 模型
条件随机场部分使用了 t o r c h c r f 包 针对训练集,返回 l o s s 和 p r e d i c t i o n s 针对测试集,由于没有 t a g s ,因此只需返回 p r e d i c t i o n s \textcolor{blue}{ 条件随机场部分使用了torchcrf包\\ 针对训练集,返回loss和predictions\\ 针对测试集,由于没有tags,因此只需返回predictions } 条件随机场部分使用了torchcrf包针对训练集,返回loss和predictions针对测试集,由于没有tags,因此只需返回predictions
代码:
import torch
from torch import nn
from torch.utils.data import Dataset
from torchcrf import CRF
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag2index, embedding_dim, hidden_size, padding_idx, device):
super(BiLSTM_CRF, self).__init__()
self.vocab_size = vocab_size
self.tag2index = tag2index
self.tagset_size = len(tag2index)
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
self.padding_index = padding_idx
self.device = device
# 词嵌入层
self.embed = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim, padding_idx=padding_idx)
# LSTM层
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, num_layers=1, bidirectional=True)
# Dense层
self.dense = nn.Linear(in_features=hidden_size * 2, out_features=self.tagset_size)
# CRF层
self.crf = CRF(num_tags=self.tagset_size)
# 隐藏层
self.hidden = None
def forward(self, texts, tags=None, masks=None):
# texts:[batch, seq_len] tags:[batch, seq_len] masks:[batch, seq_len]
x = self.embed(texts).permute(1, 0, 2) # [seq_len, batch, embedding_dim]
# 初始化隐藏层参数
self.hidden = (torch.randn(2, x.size(1), self.hidden_size).to(self.device),
torch.randn(2, x.size(1), self.hidden_size).to(self.device)) # [num_directions , batch, hidden_size]
out, self.hidden = self.lstm(x, self.hidden) # out:[seq_len, batch, num_directions * hidden_size]
lstm_feats = self.dense(out) # lstm_feats:[seq_len, batch, tagset_size]
if tags is not None:
tags = tags.permute(1, 0)
if masks is not None:
masks = masks.permute(1, 0)
# 计算损失值和概率
if tags is not None:
loss = self.neg_log_likelihood(lstm_feats, tags, masks, 'mean')
predictions = self.crf.decode(emissions=lstm_feats, mask=masks) # [batch]
return loss, predictions
else:
predictions = self.crf.decode(emissions=lstm_feats, mask=masks)
return predictions
# 负对数似然损失函数
def neg_log_likelihood(self, emissions, tags=None, mask=None, reduction=None):
return -1 * self.crf(emissions=emissions, tags=tags, mask=mask, reduction=reduction)
class NerDataset(Dataset):
def __init__(self, texts, tags, masks):
super(NerDataset, self).__init__()
self.texts = texts
self.tags = tags
self.masks = masks
def __getitem__(self, index):
return {
"texts": self.texts[index],
"tags": self.tags[index] if self.tags is not None else None,
"masks": self.masks[index]
}
def __len__(self):
return len(self.texts)
class NerDatasetTest(Dataset):
def __init__(self, texts, masks):
super(NerDatasetTest, self).__init__()
self.texts = texts
self.masks = masks
def __getitem__(self, index):
return {
"texts": self.texts[index],
"masks": self.masks[index]
}
def __len__(self):
return len(self.texts)
前向传播分析:
(1)初始:
texts:[batch, seq_len] tags:[batch, seq_len] masks:[batch, seq_len]
(2)经过embed层:
x:[seq_len, batch, embedding_dim]
(3)经过lstm层:
out:[seq_len, batch, num_directions * hidden_size]
self.hidden:[num_directions , batch, hidden_size]
(4)经过dense层:
lstm_feats:[seq_len, batch, tagset_size]
(5)经过CRF层:
loss:负对数似然函数计算出来,是一个值
predictions:第一个维度是batch,第二个维度由传入的masks决定
Dataset
分别建立了训练集的NerDataset和测试集的NerDatasetTest
5 模型训练
训练集传入模型返回loss和predictions,每隔200个iter输出损失值和微平均f1值
# 训练
def train(train_dataloader, model, optimizer, epoch):
for i, batch_data in enumerate(train_dataloader):
texts = batch_data['texts'].to(DEVICE)
tags = batch_data['tags'].to(DEVICE)
masks = batch_data['masks'].to(DEVICE)
loss, predictions = model(texts, tags, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 200 == 0:
micro_f1 = get_f1_score(tags, masks, predictions)
print(f'Epoch:{
epoch} | i:{
i} | loss:{
loss.item()} | Micro_F1:{
micro_f1}')
6 NER效果评估
计算micro f1值,用list.count()函数求得了原始的tag长度,也就是未被mask的长度,去掉头和尾,也就是每一个tags[index]和predictions[index]最多有 m a x _ l e n − 2 \textcolor{red}{\ max\_len-2} max_len−2个数据,这里对于为58个数据。按照列表切片并拼接起来,得到final_tags和final_predictions,最后调用 s k l e a r n . m e t r i c s . f 1 _ s c o r e ( ) \textcolor{red} {sklearn.metrics.f1\_score()} sklearn.metrics.f1_score()函数计算micro_f1值
# 计算f1值
def get_f1_score(tags, masks, predictions):
final_tags = []
final_predictions = []
tags = tags.to('cpu').data.numpy().tolist()
masks = masks.to('cpu').data.numpy().tolist()
for index in range(BATCH_SIZE):
length = masks[index].count(1) # 未被mask的长度
final_tags += tags[index][1:length - 1] # 去掉头和尾,有效tag,最大max_len-2
final_predictions += predictions[index][1:length - 1] # 去掉头和尾,有效mask,最大max_len-2
f1 = f1_score(final_tags, final_predictions, average='micro') # 取微平均
return f1
6 训练集流水线
代码:
# 执行流水线
def execute():
# 读取数据集
train_dataset, test_dataset = data_prepare()
# 生成word2index字典
create_word2index()
with open(WORD2INDEX_PATH, 'rb') as f:
word2index = pickle.load(f)
# 文本、标签转化为索引
texts, tags, masks = text_tag_to_index(train_dataset, word2index)
# 数据集装载
train_dataset = NerDataset(texts, tags, masks)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
# 构建模型
model = BiLSTM_CRF(vocab_size=len(word2index), tag2index=tag2index, embedding_dim=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM, padding_idx=1, device=DEVICE).to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
print(f"GPU_NAME:{
torch.cuda.get_device_name()} | Memory_Allocated:{
torch.cuda.memory_allocated()}")
# 模型训练
for i in range(EPOCH):
train(train_dataloader, model, optimizer, i)
# 保存模型
torch.save(model.state_dict(), MODEL_PATH)
效果:
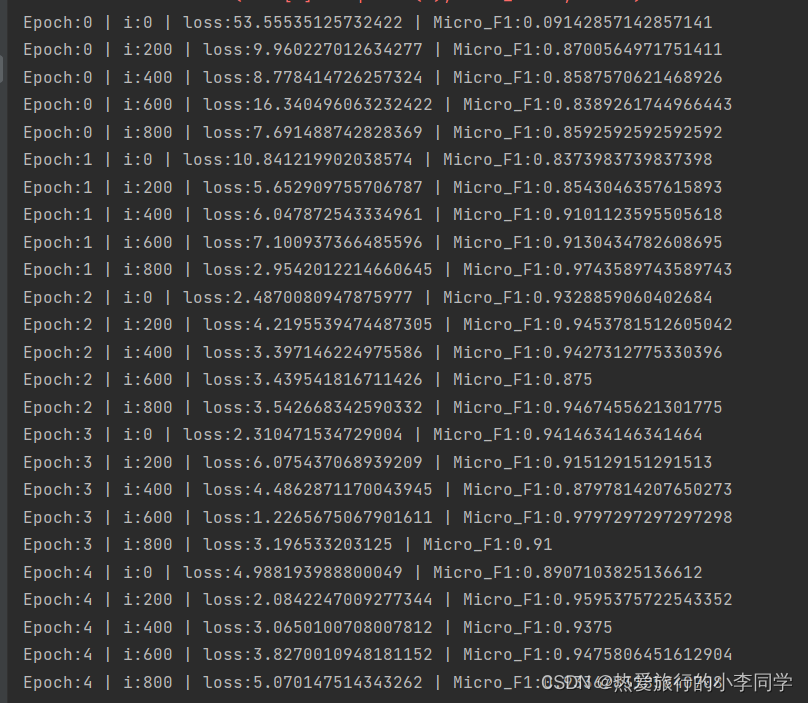
7 测试集流水线
流程:
(1)加载数据集
(2)加载word2index文件
(3)文本转化为索引,并生成masks
(4)装载测试集
(5)构建模型,装载预训练模型
(6)模型预测
(7)将预测结果转化为文本形式过程中,需要将迭代器中每一个predictions去掉头和尾
(8)生成csc文件
代码:
# 测试集预测实体标签
def test():
# 加载数据集
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')
# 加载word2index文件
with open(WORD2INDEX_PATH, 'rb') as f:
word2index = pickle.load(f)
# 文本转化为索引
texts, masks = text_to_index(test_dataset, word2index)
# 装载测试集
dataset_test = NerDatasetTest(texts, masks)
test_dataloader = DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=False)
# 构建模型
model = BiLSTM_CRF(vocab_size=len(word2index), tag2index=tag2index, embedding_dim=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM, padding_idx=1, device=DEVICE).to(DEVICE)
model.load_state_dict(torch.load(MODEL_PATH))
# 模型预测
model.eval()
predictions_list = []
for i, batch_data in enumerate(test_dataloader):
texts = batch_data['texts'].to(DEVICE)
masks = batch_data['masks'].to(DEVICE)
predictions = model(texts, None, masks)
# print(len(texts), len(predictions))
predictions_list.extend(predictions)
print(len(predictions_list))
print(len(test_dataset['text']))
# 将预测结果转换为文本格式
entity_tag_list = []
index2tag = {
v: k for k, v in tag2index.items()} # 反转字典
for i, (text, predictions) in enumerate(zip(test_dataset['text'], predictions_list)):
# 删除首位和最后一位
predictions.pop()
predictions.pop(0)
text_entity_tag = []
for c, t in zip(text, predictions):
if t != 0:
text_entity_tag.append(c + index2tag[t])
entity_tag_list.append(" ".join(text_entity_tag)) # 合并为str并加入列表中
print(len(entity_tag_list))
result_df = pd.DataFrame(data=entity_tag_list, columns=['result'])
result_df.to_csv('./data/result_df.csv')
效果:
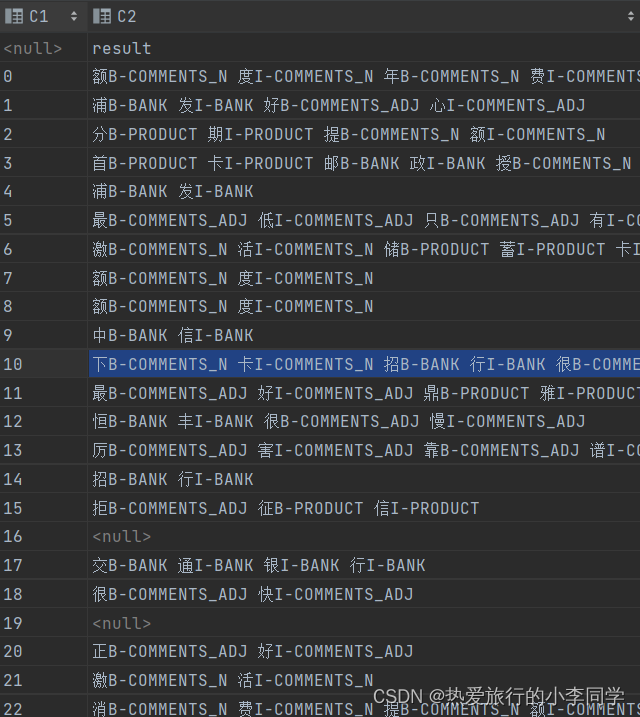
8 完整代码
study_bilstm_crf.py
# @project : pythonProject
# -*- coding: utf-8 -*-
# @Time : 2022/8/28 17:04
# @Author : leejack
# @File : study_bilstm_crf.py
# @Description : 学习BiLSTM-CRF
import numpy as np
import pandas as pd
import torch
import time
import pickle
import os
from torch import optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from bilstm_crf import BiLSTM_CRF, NerDataset, NerDatasetTest
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.metrics import f1_score
# 路径
TRAIN_PATH = './dataset/train_data_public.csv'
TEST_PATH = './dataset/test_public.csv'
VOCAB_PATH = './data/vocab.txt'
WORD2INDEX_PATH = './data/word2index.pkl'
MODEL_PATH = './model/bilstm_crf.pkl'
# 超参数
MAX_LEN = 60
BATCH_SIZE = 8
EMBEDDING_DIM = 120
HIDDEN_DIM = 12
EPOCH = 5
# 预设
# 设备
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
# tag2index
tag2index = {
"O": 0, # 其他
"B-BANK": 1, "I-BANK": 2, # 银行实体
"B-PRODUCT": 3, "I-PRODUCT": 4, # 产品实体
"B-COMMENTS_N": 5, "I-COMMENTS_N": 6, # 用户评论,名词
"B-COMMENTS_ADJ": 7, "I-COMMENTS_ADJ": 8 # 用户评论,形容词
}
# 预设标签
unk_flag = '[UNK]' # 未知
pad_flag = '[PAD]' # 填充
start_flag = '[STA]' # 开始
end_flag = '[END]' # 结束
# 生成word2index词典
def create_word2index():
if not os.path.exists(WORD2INDEX_PATH): # 如果文件不存在,则生成word2index
word2index = dict()
with open(VOCAB_PATH, 'r', encoding='utf8') as f:
for word in f.readlines():
word2index[word.strip()] = len(word2index) + 1
with open(WORD2INDEX_PATH, 'wb') as f:
pickle.dump(word2index, f)
# 数据准备
def data_prepare():
# 加载训练集、测试集
train_dataset = pd.read_csv(TRAIN_PATH, encoding='utf8')
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')
return train_dataset, test_dataset
# 文本、标签转化为索引(训练集)
def text_tag_to_index(dataset, word2index):
# 预设索引
unk_index = word2index.get(unk_flag)
pad_index = word2index.get(pad_flag)
start_index = word2index.get(start_flag, 2)
end_index = word2index.get(end_flag, 3)
texts, tags, masks = [], [], []
n_rows = len(dataset) # 行数
for row in tqdm(range(n_rows)):
text = dataset.iloc[row, 1]
tag = dataset.iloc[row, 2]
# 文本对应的索引
text_index = [start_index] + [word2index.get(w, unk_index) for w in text] + [end_index]
# 标签对应的索引
tag_index = [0] + [tag2index.get(t) for t in tag.split()] + [0]
# 填充或截断句子至标准长度
if len(text_index) < MAX_LEN: # 句子短,填充
pad_len = MAX_LEN - len(text_index)
text_index += pad_len * [pad_index]
tag_index += pad_len * [0]
elif len(text_index) > MAX_LEN: # 句子长,截断
text_index = text_index[:MAX_LEN - 1] + [end_index]
tag_index = tag_index[:MAX_LEN - 1] + [0]
# 转换为mask
def _pad2mask(t):
return 0 if t == pad_index else 1
# mask
mask = [_pad2mask(t) for t in text_index]
# 加入列表中
texts.append(text_index)
tags.append(tag_index)
masks.append(mask)
# 转换为tensor
texts = torch.LongTensor(texts)
tags = torch.LongTensor(tags)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts, tags, masks
# 文本转化为索引(测试集)
def text_to_index(dataset, word2index):
# 预设索引
unk_index = word2index.get(unk_flag)
pad_index = word2index.get(pad_flag)
start_index = word2index.get(start_flag, 2)
end_index = word2index.get(end_flag, 3)
texts, masks = [], []
n_rows = len(dataset) # 行数
for row in tqdm(range(n_rows)):
text = dataset.iloc[row, 1]
# 文本对应的索引
text_index = [start_index] + [word2index.get(w, unk_index) for w in text] + [end_index]
# 填充或截断句子至标准长度
if len(text_index) < MAX_LEN: # 句子短,填充
pad_len = MAX_LEN - len(text_index)
text_index += pad_len * [pad_index]
elif len(text_index) > MAX_LEN: # 句子长,截断
text_index = text_index[:MAX_LEN - 1] + [end_index]
# 转换为mask
def _pad2mask(t):
return 0 if t == pad_index else 1
# mask
mask = [_pad2mask(t) for t in text_index]
masks.append(mask)
# 加入列表中
texts.append(text_index)
# 转换为tensor
texts = torch.LongTensor(texts)
masks = torch.tensor(masks, dtype=torch.uint8)
return texts, masks
# 训练
def train(train_dataloader, model, optimizer, epoch):
for i, batch_data in enumerate(train_dataloader):
texts = batch_data['texts'].to(DEVICE)
tags = batch_data['tags'].to(DEVICE)
masks = batch_data['masks'].to(DEVICE)
loss, predictions = model(texts, tags, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 200 == 0:
micro_f1 = get_f1_score(tags, masks, predictions)
print(f'Epoch:{
epoch} | i:{
i} | loss:{
loss.item()} | Micro_F1:{
micro_f1}')
# 计算f1值
def get_f1_score(tags, masks, predictions):
final_tags = []
final_predictions = []
tags = tags.to('cpu').data.numpy().tolist()
masks = masks.to('cpu').data.numpy().tolist()
for index in range(BATCH_SIZE):
length = masks[index].count(1) # 未被mask的长度
final_tags += tags[index][1:length - 1] # 去掉头和尾,有效tag,最大max_len-2
final_predictions += predictions[index][1:length - 1] # 去掉头和尾,有效mask,最大max_len-2
f1 = f1_score(final_tags, final_predictions, average='micro') # 取微平均
return f1
# 执行流水线
def execute():
# 读取数据集
train_dataset, test_dataset = data_prepare()
# 生成word2index字典
create_word2index()
with open(WORD2INDEX_PATH, 'rb') as f:
word2index = pickle.load(f)
# 文本、标签转化为索引
texts, tags, masks = text_tag_to_index(train_dataset, word2index)
# 数据集装载
train_dataset = NerDataset(texts, tags, masks)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
# 构建模型
model = BiLSTM_CRF(vocab_size=len(word2index), tag2index=tag2index, embedding_dim=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM, padding_idx=1, device=DEVICE).to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
print(f"GPU_NAME:{
torch.cuda.get_device_name()} | Memory_Allocated:{
torch.cuda.memory_allocated()}")
# 模型训练
for i in range(EPOCH):
train(train_dataloader, model, optimizer, i)
# 保存模型
torch.save(model.state_dict(), MODEL_PATH)
# 测试集预测实体标签
def test():
# 加载数据集
test_dataset = pd.read_csv(TEST_PATH, encoding='utf8')
# 加载word2index文件
with open(WORD2INDEX_PATH, 'rb') as f:
word2index = pickle.load(f)
# 文本、标签转化为索引
texts, masks = text_to_index(test_dataset, word2index)
# 装载测试集
dataset_test = NerDatasetTest(texts, masks)
test_dataloader = DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=False)
# 构建模型
model = BiLSTM_CRF(vocab_size=len(word2index), tag2index=tag2index, embedding_dim=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM, padding_idx=1, device=DEVICE).to(DEVICE)
model.load_state_dict(torch.load(MODEL_PATH))
# 模型预测
model.eval()
predictions_list = []
for i, batch_data in enumerate(test_dataloader):
texts = batch_data['texts'].to(DEVICE)
masks = batch_data['masks'].to(DEVICE)
predictions = model(texts, None, masks)
# print(len(texts), len(predictions))
predictions_list.extend(predictions)
print(len(predictions_list))
print(len(test_dataset['text']))
# 将预测结果转换为文本格式
entity_tag_list = []
index2tag = {
v: k for k, v in tag2index.items()} # 反转字典
for i, (text, predictions) in enumerate(zip(test_dataset['text'], predictions_list)):
# 删除首位和最后一位
predictions.pop()
predictions.pop(0)
text_entity_tag = []
for c, t in zip(text, predictions):
if t != 0:
text_entity_tag.append(c + index2tag[t])
entity_tag_list.append(" ".join(text_entity_tag)) # 合并为str并加入列表中
print(len(entity_tag_list))
result_df = pd.DataFrame(data=entity_tag_list, columns=['result'])
result_df.to_csv('./data/result_df.csv')
if __name__ == '__main__':
execute()
# test()