编者:王小草
日期:2018年7月28日
今天俺要介绍的是一篇来自2018 ACL会议上的论文,属于语言表征上范畴,讲的是如何用无监督的方式进行跨语言的词嵌入表征。
1 背景知识
在介绍论文之前,善良的我先给大家介绍一下论文的背景知识。
1.1 什么是跨语言词嵌入?
英文:cross-lingual embedding
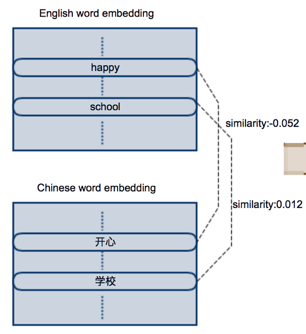
我们很熟知用word2vec(CBOW/Skip-grim)可以训练出有语义相似性的词嵌入向量,广泛应用于许多NLP任务,并取得了很好的效果。下图依次是在英文语料上独立训练的英文词嵌入,和在中文语料上独立训练的英文词嵌入。因为是在各自的语料上独立训练的,因此两个词嵌入矩阵在分布上也是独立不相关的。比如“happy”和“快乐”两个词的语义相同,但是他们的向量的相似性却为-0.052;同理“school”和“学校”的相似性为0.012,来自不同语言但含义相似的词几乎没有任何相关性。
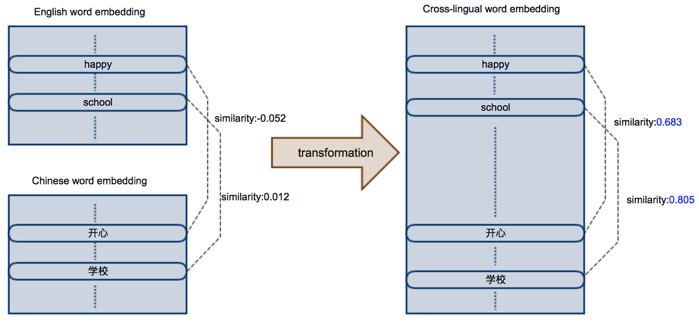
而跨语言词嵌入是指将不同语言独立训练的词向量,通过某种方式转换到同一个共享的空间中。在这个共享的空间中,即使是不同语言的词,只要具有相似含义,他们就有高的相似性。如下如,“happy”和“快乐”两个词在新的共享空间中,相似性为0.683;“school”和“学校”的相似性为0.805,体现了高的相似性。
1.2 为什么要进行跨语言词嵌入?
可以总结为3个好处:

其中第二点是至关重要的原因。因为目前英文语言的研究者多,公开的英文数据集也相对来说比其他语言更多。因此,当看到在英文上表现惊艳的模型时,发现因为缺少中文数据集,而无法迁移,总是苦之闷之,仰天捶胸。但是若可以将英文和中文的词都嵌入进相同的空间中,那么在英文上训练出来的模型,就可以直接应用在中文数据上了,简直痛之快之,伏案大笑。
1.3 如何进行跨语言词嵌入?
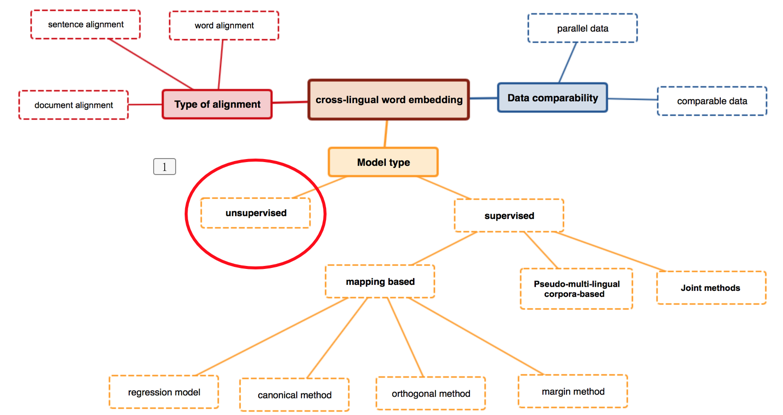
上图是跨语言词嵌入的几个研究方向。从训练数据上分可分为基于词对齐的,句子对齐的,以及文章对齐;或者是基于并行数据(如翻译对)或基于相似数据(如在pos上相似的词对)。从模型上分可以分为无监督和有监督。有监督的研究颇多,本文不详细介绍。无监督的模型是最近才兴起的,本文将着重介绍2018 ACL的一篇利用无监督算法进行跨语言词嵌入的文章。这篇文章的结果显示,无监督的模型不但取得了很好的成绩,还在大部分跨语言上超过了有监督的模型,这是喜之贺之。那么让我们带着激动的心情一起去看看作者到底是如何操作的呢?
2 数据准备与定义
2.1 准备独立语言的词嵌入矩阵
与
分别表示两类语言中独立训练好的词嵌入矩阵,需要自己先训练好的。
与
表示在相应的词嵌入矩阵中的第i个词的词嵌入向量。
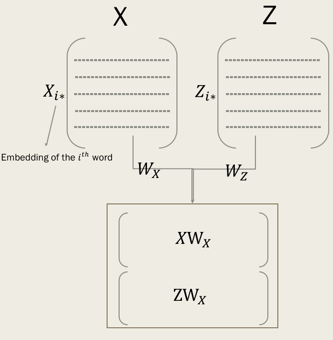
我们的目标是要学习
和
这两个转换矩阵(transformation metrices),从而使得
和
在同一个跨语言空间中。如下图:
2.2 定义词典
因为是无监督的,所以是不需要任何训练数据集的。但是我们得定义一个词典,这个词典的行是来自X语言的词(x1,x2,..xi,…);列是来自于Z语言的词(z1,z2,…,zi,…)。 =1,如果Z中的第j个词是X中的第i个词的翻译,否则 =0.
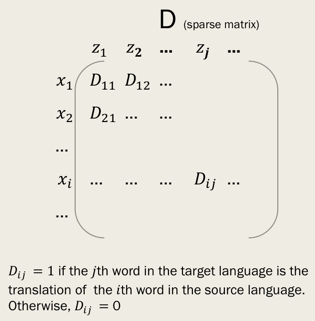
接下去,是两部重头戏:
1)通过X,Y两个独立的词嵌入矩阵去初始化字典D
2) 通过优化D,得到最优的
和
3 方法详解
3.1 词嵌入标准化
重头戏总是有铺垫颇多,先来看看文中对词嵌入矩阵进行标准化的方法,等下重头戏中要用到。
标准化的过程分为三步:
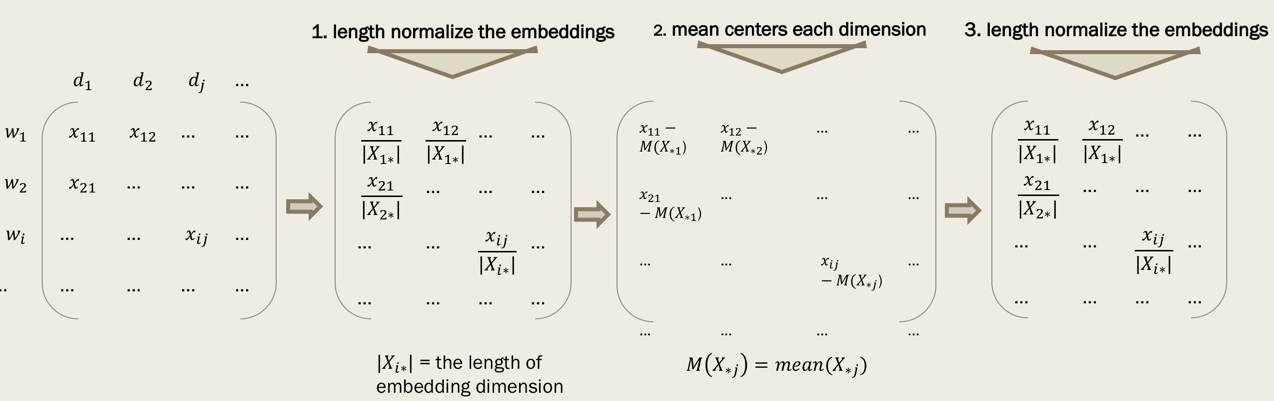
根据长度归一化词嵌入:
/ |
|,即将每个词嵌入向量的维度上都除以嵌入向量的长度。
均值中心化每个维度:对类一列都减去该列的均值。
中心化之后再进行一次一模一样的长度归一化,确保最后输出的词向量是unit length的。
为啥要这样做呢?主要出于两个原因
1)0均值之后,向量之间的点乘就是这两个向量的余弦相似度,也等价于是欧氏距离,因此可以直接用来描述向量之间的相似性。(至于为什么这样标准化了之后就各种等价了呢,作者在他以前写的一篇文章中做了解释:【Learning principled bilingual mappings of word em- beddings while preserving monolingual invariance.】)
2)长度归一化之后,当进行奇异值分解的时候,
=
, S就相当于是词向量的维度与维度之间的相似性矩阵。(后文求最优化的过程会用到奇异值分解)
3.2 完全无监督的初始化
3.2.1 初始化字典的困境
困境:
现在我们要用X和Y两个词嵌入矩阵去初始化词典D了。但是!因为
与
是两类语言独立训练出来的词嵌入矩阵,因此无论是他们的第i个词
与
,还是第j个维度
与
都是不对齐的,两个嵌入矩阵是没有任何直接的相关性的。没有相关性,那怎么生成相关性矩阵D呢???
解决方案:
于是作者提出了一个解决方案,先构建两个替代的嵌入矩阵
和
,这个两个矩阵在第j维上是对齐的:
与
。那么如何得到这两个替代的矩阵呢?
3.2.2 相似矩阵代替词嵌入矩阵
计算
与
的相似矩阵(similarity metrices):
和
=
=
假设两个原来的词嵌入空间是完全等距的,相似性矩阵
和
等价于他们行和列的排列,这个排列定义了跨这两个语言的字典。虽然实际上,完全的等距并不存在,但是可以被假设它们是近似的。在此基础上,我们可以尝试行和列索引的所有可能排列,以找到
和
之间的最佳匹配。
那么问题又来了,尝试行和列索引的所有可能排列,以找到 和 之间的最佳匹配,可能会导致组合爆炸。于是聪明的作者又提出了向量排序的方法。
3.2.3 相似句子向量排序
为了解决以上问题,作者提出先对相似性矩阵的每一行都进行排序。在严格的等距条件下,排序后,不同语言中相等的词会得到相同的向量。因此给出sorted( )中的任意一行,都可以在sorted( )中找到最相近的一行,从而找到对应词的翻译。
3.2.4 相思矩阵开根号
将词嵌入矩阵进行奇异值分解:
=
于是相似性矩阵为:
=
=
*
=
相似性矩阵的开根号与原词向量矩阵
更接近:
=
,在实践中也发现开更好后效果更好。
同理,可以得到
因此我们使用sorted(
)和sorted(
)代替sorted(
)和sorted(
)
3.2.5 得到词嵌入矩阵的最终变体
接着,根据3.1中标准化词嵌入的方法,对sorted( )和sorted( )进行标准化,得到我们一开始定义的替代矩阵: 和 ,它们将被用于去建立自学习(下一节)的初始解
3.3 鲁棒的自学习
3.3.1 步骤:
主要分成两个步骤,重复以下两个步骤直到收敛。
1)通过最大化当前字典
的相似性计算最优的正交映射:
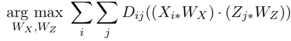
以上可以这样求解:
的奇异值分解:
=
,其中得到
=
,
=
2)在映射后的词嵌入相似性矩阵上计算最优的词典
:
映射后的词嵌入相似性矩阵:
如果j =
,则
= 1,否则
= 0
3.3.2 困境:
底层的优化目标与初始字典是独立的,并且保证算法收敛到初始字典的局部最优。但是!如果从一个完全随机的解开始,这个方法就不起作用了,因为在这种情况下,它会陷入糟糕的局部最优。基于此,我们使用3.2节无监督初始化给出的初始解。又但是!简单地插入这两种方法在我们的初步实验中并没有起作用,因为这种初始方法的质量不够好,无法避免局部最优。有基于此,我们接下来提出了一些关键的改进,在字典归纳步骤中,使自学习更加健壮,并学习更好的映射。
3.3.3 解决方案:
主要可分成四步:
1)随机字典归纳
为了鼓励对搜索空间进行更广泛的探索,我们在相似矩阵中以概率p随机保留一些元素,并将其余的元素设置为0,使字典归纳为随机的。因此,p的值越小,受影响的字典就会随着迭代次数的变化而变化,从而避免了本地最优的优化。为了在算法进入一个好的区域后找到一个细粒度的解,在训练过程中我们会增加这个p值(从p=0.1开始),就像模拟退火一样。当步骤1中的目标函数在每50词迭代中没有提升
的时候,会将p值翻倍。
2)基于频率的字典裁剪
随着词的增加,相似性矩阵会以平方的速度增加,不仅增加了计算成本,而且使得可能解的数量以指数为3的速度上升,从而使得优化难度增加。考虑到较不频繁的单词可能会是噪音,作者建议将字典归纳过程限制在每种语言中频次最高的前k个词中。在实践中发现k=20000的时候效果好。
3)CSLS 抽取
靠得很相近的那些词会有hubness的问题,这种现象被认为是维数诅咒的结果,并导致一些点(称为中心点(hub))成为许多其他点的近邻。文中使用Cross-domain Similarity Local Scaling (CSLS)(来自文献Conneau et al. (2018)),步骤如下:
给定两个映射之后的词嵌入向量x,y.
计算
:向量x在y向量的语言中的最相近的k个词的余弦相似度的均值;同理计算
x,y的修正后的分数为
r_T(y)。Conneau et al将k设置为10
4)双向字典归纳
当字典从源语言被导入到目标语言中时,并不是所有的目标语言词汇都会出现在字典中,有些词汇会多次出现。我们认为这可能会加重局部最优的问题,因为重复的词语可能会起到强大的吸引子的作用,很难逃脱。为了缓解这一问题并鼓励差异,我们提出了从两个方向引入字典并采取相应的拼接。
注意,计算初始解的时候,我们使用 和 ,不使用随机字典归纳,并且字典裁剪中k值设为4000。得到初始字典之后,之后的步骤中,不再使用 和 ,而是在原 和 上进行计算。
3.4 对称的re-weighting
根据词嵌入中维度与维度的相关性矩阵去赋予转换矩阵中的维度新的权重,那些在跨语言中相似性高的维度应该具有更高的权重。
因为上文已经进行过了embedding normalization, 因此词向量维度的相关性矩阵就是上文奇异值分解中的S。因此,转换矩阵可以写成:

但由于re-weighting仍然会造成局部最优的困境,因此只在3.3中迭代收敛后使用。并且将reweighting对称得应用在两个语言中。
4 实验设置
4.1 评估的方法:
根据常用的方法,我们使用双语词汇提取的方法,该方法通过与gold standard的比较来衡量归纳词典的准确性,具体步骤如下:

4.2 评估的数据集来自以下两篇论文:
1)dataset of Dinu et al. (2015) and the subsequent extensions of Artetxe et al. (2017, 2018a)
【Improving zero-shot learning by mitigat- ing the hubness problem】
【Learning bilingual word embeddings with (almost) no bilingual data】
跨语言对:English-Italian, English-German, English-Finnish and English- Spanish
2)Zhang et al. (2017a)
【Adversarial training for unsupervised bilingual lexicon induction】
跨语言对:Spanish-English, Italian-English and Turkish- English
4.3 对比的方案:
对比的方案来自以下两篇论文,使用的都是无监督的方法。
1)Zhang et al. (2017a):
【Adversarial training for unsupervised bilingual lexicon induction.】
2)Conneau et al. (2018):
【Word translation without parallel data】
针对每个比较的方案,会运行10次,并且输出10次的平均accuracy,与最大的accuracy进行比较。
4.4 工具:
python(numpy and cupy)
5 实验结果
5.1 主要结果
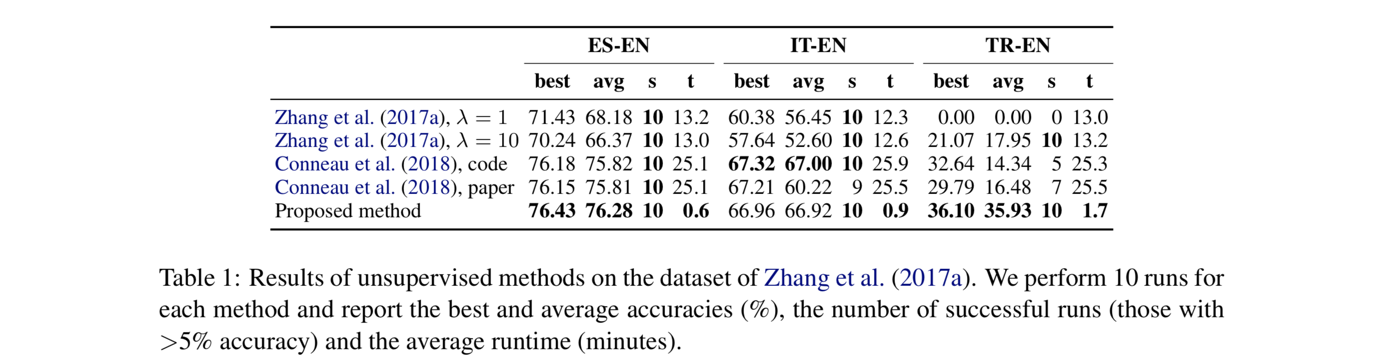
在数据集Zhang et al. (2017a)上的表现如下表,比较Zhang et al. (2017a)、Conneau et al. (2018),以及本文作者的无监督方案。
在数据集dataset of Dinu et al. (2015) and the subsequent extensions of Artetxe et al. (2017, 2018a) 上的表现如下表,比较Zhang et al. (2017a)、Conneau et al. (2018),以及本文作者的无监督方案。
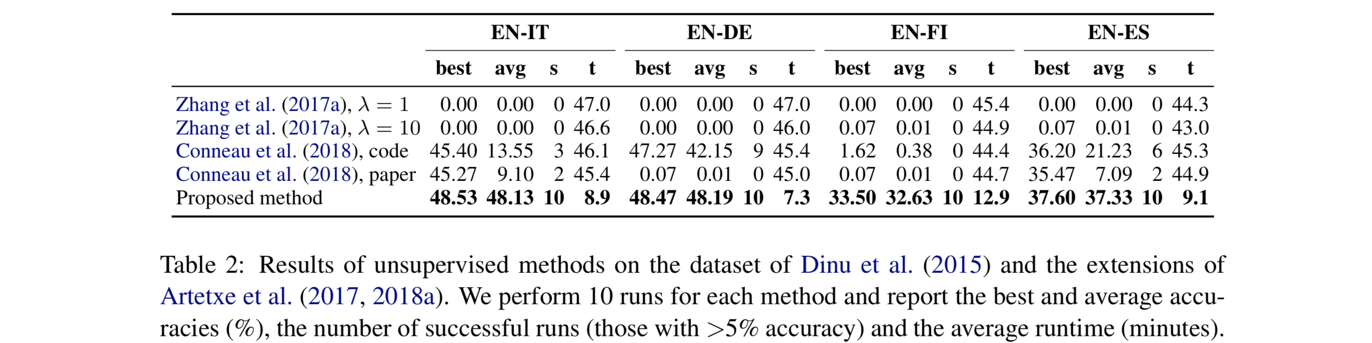
从上面两个数据集上的表现来看,本文提出的无监督方法略胜一筹。
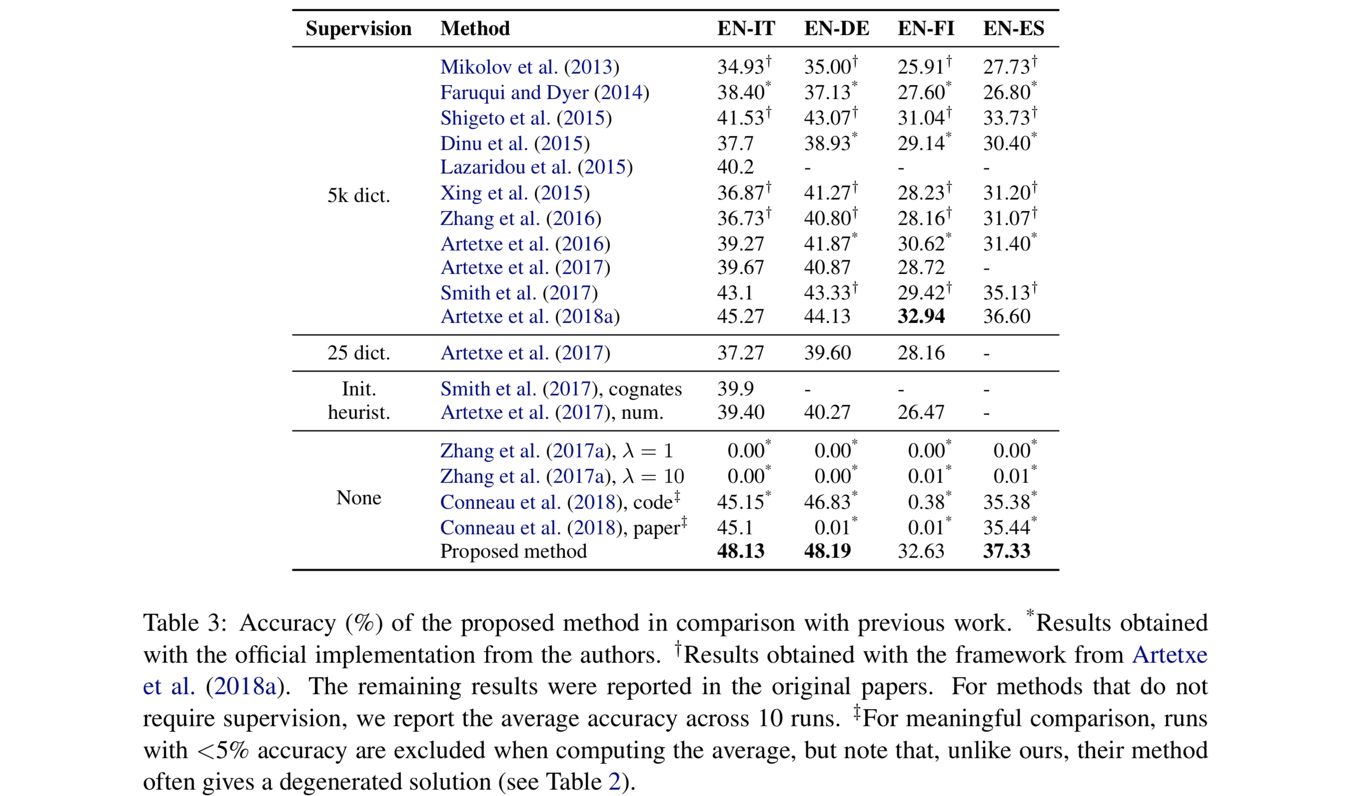
5.2 与其他最新研究的比较
5.3 烧灼测试(Ablation test)
为了更好的理解在本文的无监督模型中,各个因素对模型表现的贡献,作者分别试验了移除该因素后的模型表现,并进行了比较。
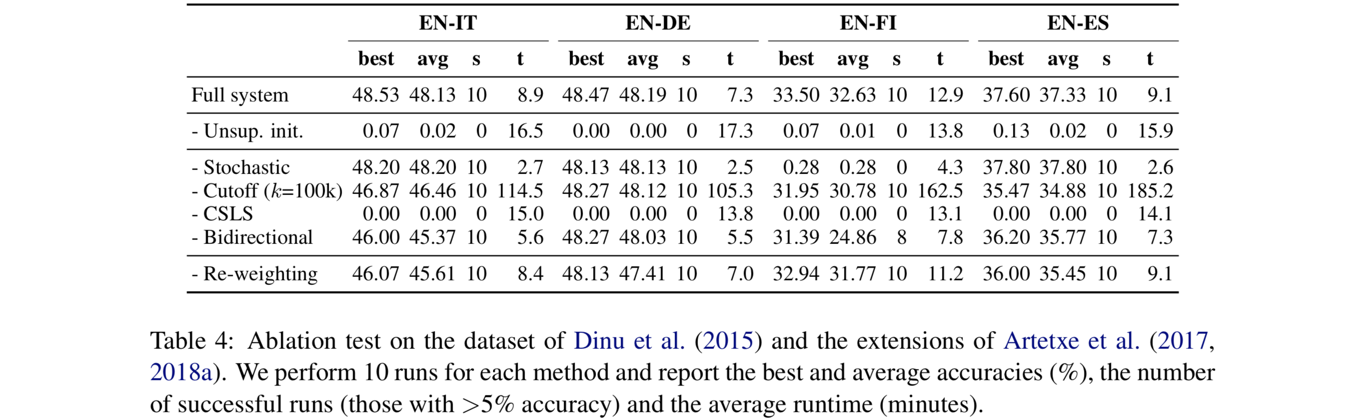
当去除掉unsupervised initialization之后,模型表现大大降低,说明本文3.2提出的初始化方法非常有效。其他的结论不在这里复述作者的原话了,大家可以自己看表分析或者找原文阅读哈~
论文地址:http://aclweb.org/anthology/P18-1073
代码地址:https://github.com/artetxem/vecmap