Redis为什么快?
项目中会用到redis,因为redis可做缓存,并发每秒能处理10w条数据。但你知道为什么redis存取那么快么,你可能会说redis基于内存,基于K-V存储,单线程….。等等,为什么单线程反而会快了呢?
其实Redis是基于NIO的多路复用模型。Windows环境下是select的多路复用,Linux环境下是epoll的多路复用。可能有人会问,什么是多路复用。
多路复用
简单来说,Redis将数据的读取交给内核去做
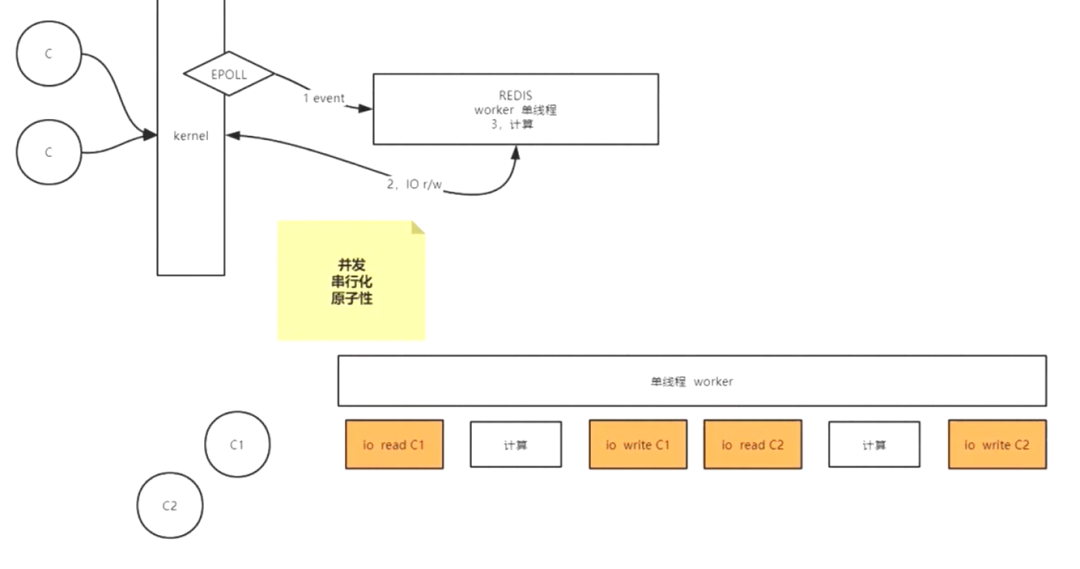
多路复用
redis会将n个客户端连接放入一个集合中(这里就是一个进程),然后再调用epoll(Windows下没有这个函数)或者select函数将集合放入操作系统内核kernel中进行处理,通过事件驱动,内核会获取有数据的连接并循环读取,时间复杂度为O(1)。
如果你问什么是NIO?你需要额外的补充NIO的知识。
Redis value结构
常见5种结构
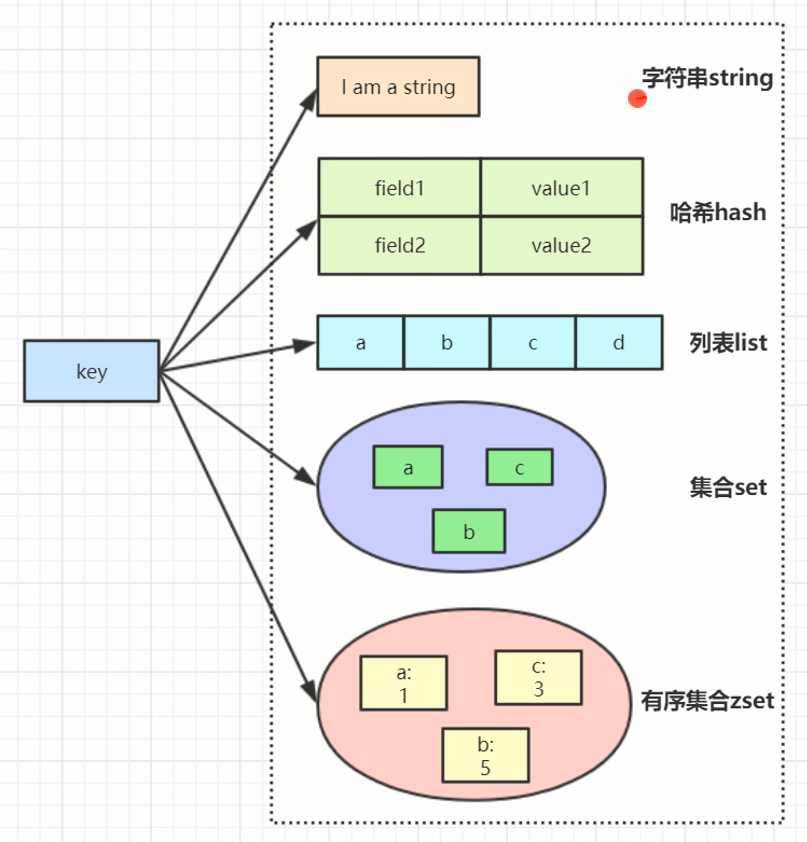
value结构
使用场景
String
比如微信公众号统计阅读数量就可以使用value为String
1
2
|
INCR article:readcount:{文章id}
GET article:readcount:{文章id}
|
可以做分布式系统全局的序列号
1
|
INCRBY orderId 1000 //一次性生成1000个id,可以存入队列中,按需获取
|
tips: 可以用setnx命令 + 超时时间做 分布式锁 ,github上有关于我的redis分布式锁的项目:dislock
除了redis可以做分布式锁外,zookeeper也可以做分布式锁(基于节点名唯一,watcher机制),相比于redis,zookeeper在最终一致性上强于redis,但性能会弱于redis。github分布式锁项目:distributelock
Bitmap
可以统计用户 任意时间窗口登录了几次
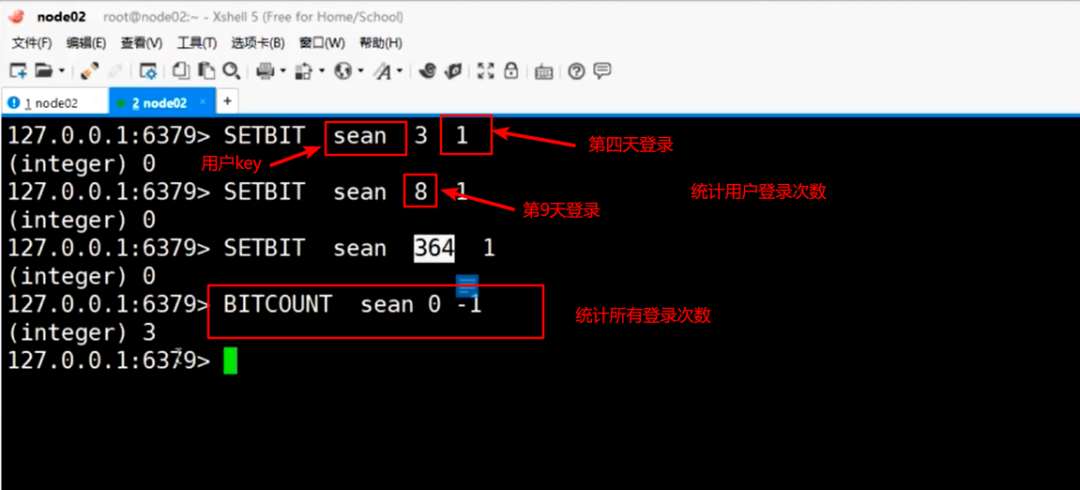
bitmap是一个二进制的数组,长度不限(当长度为20亿时,占用内存200多MB)。数组内的值为0或1。如上图,用户sean第4天登录,则为
第9天登录为
以此类推。最后一行为统计第一个索引到最后一个索引之间值为1的次数。
我们还可以用bitmap统计活跃用户数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#第一天7号用户登录一次
127.0.0.1:6379> setbit 20200101 7 1
( integer ) 0
#第一天3号用户登录一次
127.0.0.1:6379>set bit 20200101 3 1
( integer ) 0
#第二天3号用户登录一次
127.0.0.1:6379> setbit 20200102 3 1
( integer ) 0
#或运算
127.0.0.1:6379> BITOP or res 20200101 20200102
#统计活跃用户
127.0.0.1:6379> BITCOUNT res
( integer ) 2
2人
|
tips:大名鼎鼎的布隆过滤器就可以用bitmap是实现
Hash
hash可以存购物车相关信息
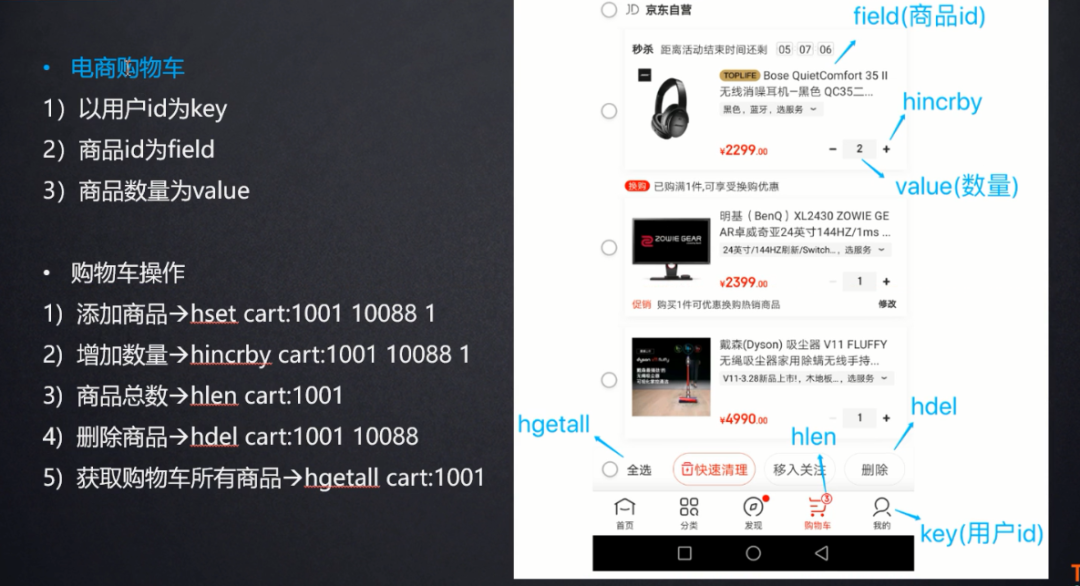
如上图:以用户id为key,商品id为filed,商品数量为value存储。可以展示购物车信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
127.0.0.1:6379> hset cart:1001 10088 1
(integer) 1
127.0.0.1:6379> hincrby cart:1001 10088 1
(integer)2
127.0.0.1:6379> hget cart:1001 10088
"2"
127.0.0.1:6379> hset cart:1001 10088 1
(integer)0
127.0.0.1:6379> hset cart:1001 20088 1
(integer) 1
127.0.0.1:6379> hlen cart:1001
(integer) 2
127.0.0.1:6379> hdel cart:1001 20088
(integer) 1
127.0.0.1:6379> hlen cart:1001
(integer)1
127.0.0.1:6379> hset cart:1001 30088 1
(integer) 1
127.0.0.1:6379> hgetall cart:1001
1)"10088"
2)"1"
3)"30088"I
4)"1"
127.0.0.1:6379>
|
hash结构有以下优缺点:
优点
1)同类数据归类整合储存,方便数据管理
2)相比string操作消耗内存与cpu更小
3)相比string储存更节省空间
缺点
1)过期功能不能使用在field上,只能用在key上
2)Redis集群架构下不适合大规模使用
总的来说hash可用于存储 详情页聚合,数据来自不同的库的聚合。
List
list可用作队列,栈等数据结构

微博消息和公众号消息场景
1
2
3
4
5
6
7
|
lvshen关注了MacTalk,备胎说车等大V
1)MacTalk发微博,消息ID为10018
LPUSH msg:(lvshen-ID} 10018
2)备胎说车发微博,消息ID为10086
LPUSH msg:(lvshen-ID) 10086
3)查看最新微博消息
LRANGE msg:(lvshen-ID} 0 5
|
list常用操作
1
2
3
4
5
6
7
|
LPUSH key value [value ...] //将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value ...] //将一个或多个值value插入到key列表的表尾(最右边)
LPOP key //移除并返回key列表的头元素
RPOP key //移除并返回key列表的尾元素
LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key ...] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key ...] timeout //从key列表表尾弹出一元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待
|
Set
set可以用作微信抽奖小程序
1
2
3
4
5
6
|
1)点击【参与抽奖】加入集合
SADD key {userlD}
2)查看参与抽奖所有用户
SMEMBERS key
3)抽取count名中奖者
SRANDMEMBER key [count] /SPOP key [count]
|
也可以用于微信微博点赞
1
2
3
4
5
6
7
8
9
10
|
1)点赞
SADD like:{消息ID} {用户ID}
2)取消点赞
SREM like:{消息ID} {用户ID}
3)检查用户是否点过赞
SISMEMBER like:{消息ID} {用户ID}
4)获取点赞的用户列表
SMEMBERS like:{消息ID}
5)获取点赞用户数
SCARD like:{消息ID}
|
可以通过集合操作实现微博微信关注模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
1)Lvshen(我)关注的人:
#lvshenSet-> {A, B, C}
192.168.42.128:6379> sadd lvshenSet A B C
(integer) 3
2)A关注的人:I
#aSet--> {lvshen, B, C, guojia}
192.168.42.128:6379> sadd aSet lvshen B C guojia
(integer) 4
3)B关注的人:
#bSet-> {lvshen, A, guojia, C, xunyu)
192.168.42.128:6379> sadd bSet lvshen A guojia C xunyu
(integer) 5
4)我和A共同关注:
SINTER lvshenSet aSet--> {B, C}
5)我关注的人也关注他(A):
SISMEMBER bSet A
SISMEMBER cSet A
6)我可能认识的人:
SDIFF aSet lvshenSet--> (lvshen, guojia)
|
set常用操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
//Set常用操作
SADD key member [member...] //往集合key中存入元素,元素存在则忽略,若key不存在则新建
SREM key member [member...] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
//Set运算操作
SINTER key [key...] //交集运算
SINTERSTORE destination key [key..] //将交集结果存入新集合destination中
SUNION key [key..] //并集运算
SUNIONSTORE destination key [key...] //将并集结果存入新集合destination中
SDIFF key [key...] //差集运算
SDIFFSTORE destination key [key...] //将差集结果存入新集合destination中
|
总的来说set可以用于去重,抽奖等操作
Zset
zset为有序的去重集合,可用于实现排行榜
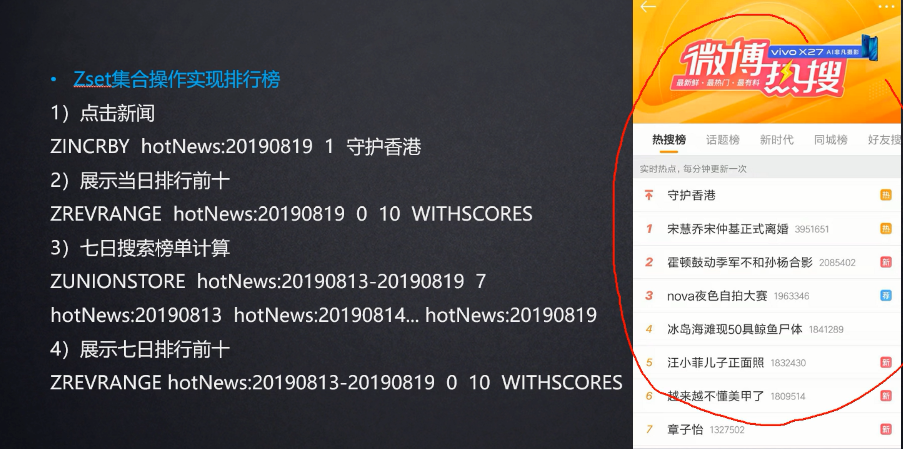
总结:zset可以用于排行榜,翻页等场景。zset可以用于作延迟队列,score为延迟的时间点,获取时顺序获取端口的值,如果当前时间戳等于score则可取出。
zset的底层数据结构为跳表,一种特殊的链表,同时查找和增删都很优秀,具体知识可以参考文章:
Redis—跳跃表
GEO
redis还可以支持地理位置查询,适用于LBS的开发

常用命令
Stream
Stream 5.0版本开始的新结构“流”。使用场景:消费者生产者场景(类似MQ)
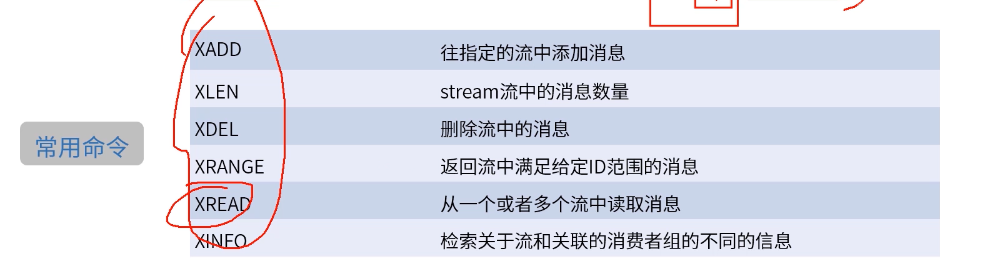
常用命令
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
127.0.0.1:6379> xadd room:msg:1001 * userId tony content hello
"1568106742941-0"
127.0.0.1:6379> xadd room:msg:1001 * userId tony content hello2
"1568106753764-0"
127.0.0.1:6379> type room:msg:1001
stream
127.0.0.1:6379> xlen room:msg:1001
(integer)2
127.0.0.1:6379> xrange room:msg:1001 - +
1) 1)"1568106742941-0"
2) 1)"userId"
2)"tony"
3)"content"
4)"hello"
2) 1)"1568106753764-0"
2) 1)"userId"
2)"tony"
3)"content"
4)"hello2"
127.0.0.1:6379>
127.0.0.1:6379> xread count streams room:msg:1001 0
1) 1)"room:msg:1001"
2) 1) 1)"1568106742941-0"
2) 1)"userId"
2)"tony"
3)"content"
4)"hello"
2) 1)"1568106753764-0"
2) 1)"userId"
2)"tony"
3)"content"
4)"hello2"
127.0.0.1:6379> xread count 2 streams room:msg:1001 $
(nil)
127.0.0.1:6379> xread count 2 streams room:msg:1001 $
(nil)
127.0.0.1:6379> xread count 2 block 10000 streams room:msg:1001 $
|
现在redis普遍用的都是3.x,list也可用于消息队列。所以很少有人用stream。
Redis集群
有关集群的搭建可以参考:Redis3.0集群搭建
关于集群关心的问题
1、增加了slot槽的计算,是不是比单机性能差?
共16384个槽,slots槽计算方式公开的,HASH_SLOT=CRC16(key)mod16384。
为了避免每次都需要服务器计算重定向,优秀的java客户端都实现了本地计算,并且缓存服务器slots分配,有变动时再更新本地内容,从而避免了多次重定向带来的性能损耗。
2、redis集群大小,到底可以装多少数据?
理论是可以做到16384个槽,每个槽对应一个实例,但是redis官方建议是最大1000个实例。存储足够大了。
3、ask和moved重定向的区别
重定向包括两种情况
a.若确定slot不属于当前节点,redis会返回moved。
b.若当前redis节点正在处理slot迁移,则代表此处请求对应的key暂时不在此节点,返回ask,告诉客户端本次请求重定向。
4、数据倾斜和访问倾斜的问题
倾斜导致集群中部分节点数据多,压力大。解决方案分为前期和后期:前期是业务层面提前预测,哪些key是热点,在设计的过程中规避。后期是slot迁移,尽量将压力分摊(slot调整有自动rebalance、reshard和手动)。
5、读写分离
redis cluster默认所有从节点上的读写,都会重定向到key对接槽的主节点上。
可以通过readonly设置当前连接可读,通过readwrite取消当前连接的可读状态。
注意:主从节点依然存在数据不一致的问题
Redis可用性
通过主从集群实现高可用,slave节点向master节点发送syn请求同步命令。master节点会通过bgsave命令创建rdb文件将数据以二进制形式存储其中,然后将文件分发给slave节点。
tips: 1.bgsave是创建了子线程工作,不影响主线程; 2.主从结构以线性链表部署,不要图状结构部署
Redis缓存失效问题
缓存一致性模型
查询信息时,先从缓存中获取信息;缓存中没有则从数据库中获取;将值塞到缓存。
缓存击穿
查询一个不存在的key,查询会直接落到数据库上。如果黑客用不存在的key查询,很可能搞垮数据库。
解决思路:查询之前先判断目标数据是否存在,不存在的直接忽略。将流量拦截于缓存和数据库之前。
这里使用布隆过滤器:
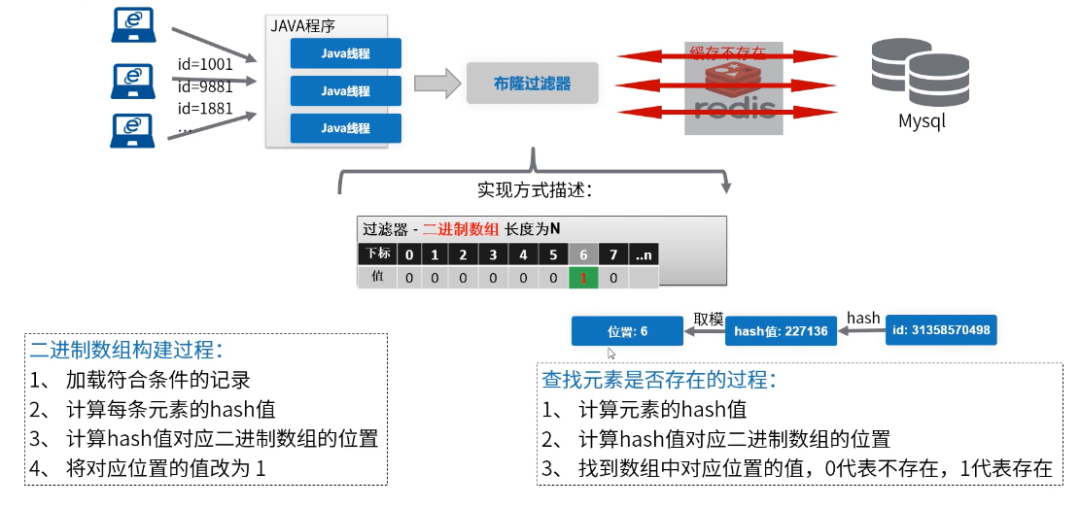
布隆过滤器
demo示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
@Test
public void testBit() {
String userId = "1001";
int hasValue = Math.abs(userId.hashCode()); //key 做hash运算
long index = (long) (hasValue % Math.pow(2, 32)); //hash值与数组长度取模
Boolean bloomFilter = redisTemplate.opsForValue().setBit("user_bloom_filter", index, true);
log.info("user_bloom_filter:{}",bloomFilter);
}
//缓存击穿解决方法
@Test
public void testUnEffactiveCache() {
String userId = "1001";
//1.系统初始化是init 布隆过滤器,将所有数据存于redis bitmap中
//2.查询是先做判断,该key是否存在与redis中
int hasValue = Math.abs(userId.hashCode()); //key 做hash运算
long index = (long) (hasValue % Math.pow(2, 32)); //hash值与数组长度取模
Boolean result = redisTemplate.opsForValue().getBit("user_bloom_filter", index);
if (!result) {
log.info("该userId在数据库中不存在:{}",userId);
//return null;
}
//3.从缓存中获取
//4.缓存中没有,从数据库中获取,并存放于redis中
}
|
布隆过滤器优缺点
优点:
内存空间占用少
缺点:
布隆过滤器需要不断维护,带来新的工作
布隆过滤器并不能精准过滤。(布隆过滤器判定不存在,100%不存在,判断为存在,则可能不存在的。)理论上Hash计算值是有碰撞的(不同的内容hash计算出同样的值),导致不存在的元素可能
会被判断为存在
为了减少hash碰撞,可以将key用几个hash算法获取index值。然而布隆过滤器并非需要拦截所有的请求,只需要将缓存击穿控制在一定的量即可。
缓存雪崩
当大量的key在统一时间过期,而这时又有大量的访问key,请求落到数据上,导致数据库崩溃。
解决办法:
Semaphore信号量限流
J.U.C包重要的并发编程工具类,又称“信号量”,控制多个线程争抢许可。
核心方法
acquire:获取一个许可,如果没有就等待,
release:释放一个许可。
典型场景
1、代码并发处理限流;
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
package com.lvshen.demo.semaphore;
import java.util.Random;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
/**
* Description:信号量机制
*
* @author Lvshen
* @version 1.0
* @date: 2020/3/21 20:34
* @since JDK 1.8
*/
public class SemaphoreDemo {
public static void main(String[] args) {
SemaphoreDemo semaphoreDemo = new SemaphoreDemo();
int count = 9; //数量
//循环屏障
CyclicBarrier cyclicBarrier = new CyclicBarrier(count);
Semaphore semaphore = new Semaphore(5);//限制请求数量
for (int i = 0; i < count; i++) {
String vipNo = "vip-00" + i;
new Thread(() -> {
try {
cyclicBarrier.await();
//semaphore.acquire();//获取令牌
boolean tryAcquire = semaphore.tryAcquire(3000L, TimeUnit.MILLISECONDS);
if (!tryAcquire) {
System.out.println("获取令牌失败:" + vipNo);
}
//执行操作逻辑
System.out.println("当前线程:" + Thread.currentThread().getName());
semaphoreDemo.service(vipNo);
} catch (Exception e) {
e.printStackTrace();
} finally {
semaphore.release();
}
}).start();
}
}
// 限流控制5个线程同时访问
public void service(String vipNo) throws InterruptedException {
System.out.println("楼上出来迎接贵宾一位,贵宾编号" + vipNo + ",...");
Thread.sleep(new Random().nextInt(3000));
System.out.println("欢送贵宾出门,贵宾编号" + vipNo);
}
}
|
容错降级
如果令牌被抢完(并发时还没来的及释放令牌),线程执行到这里时可以返回一个异常码。
redis集群方案
还有一种可能,如果redis key来不及删除,由于内存淘汰策略。会删除一些key,导致缓存失效。集群方案可以解决内存不足问题。
高并发下缓存不一致问题
根据缓存一致性模型:
查询信息时,a.1:先从缓存中获取信息;a.2:缓存中没有则从数据库中获取;a.3:将值塞到缓存。
更新数据时,b.1:更新数据库;b.2:删除缓存
如果查询和更新是两个线程,由于以上执行并非原子性,b.2可能会先于a.3执行。导致redis里面数据和数据库数据不一致。
解决方法
可以先将数据预热到redis中,去掉查询时存入redis的操作。再部署一个mysql服务,收集mysql日志。数据库数据发生变化的时候,通知缓存维护程序,把变化后的数据更新到到缓存里面。

关于数据库监听,阿里有一套开源框架 Canal ,可以监听mysql的数据变化。
Redis持久化
1.RDB快照:将数据以二进制形式写到文件中
2.AOF:将写命令以追加的形式写入到aof文件中
关于aof有下面几种形式:
a. redis没操作一次,写一次文件。优点是保证完整性,缺点是一致性会下降
b. 每秒钟将写命令写入到一个buffer中,当buffer中存满一定的数据,再写入到文件中(aof默认采用此种写入)
c.每次操作将写命令存入buffer中,之后再写入文件中
使用
默认是使用rdb恢复数据,如果开启aof,重启之后会加载aof文件恢复。当然生产环境上是混合使用。比如8点之前我使用rdb恢复,8点之后我使用aof恢复。
往期推荐
扫码二维码,获取更多精彩。或微信搜Lvshen_9,可后台回复获取资料
1.回复"java" 获取java电子书;
2.回复"python"获取python电子书;
3.回复"算法"获取算法电子书;
4.回复"大数据"获取大数据电子书;
5.回复"spring"获取SpringBoot的学习视频。
6.回复"面试"获取一线大厂面试资料
7.回复"进阶之路"获取Java进阶之路的思维导图
8.回复"手册"获取阿里巴巴Java开发手册(嵩山终极版)
9.回复"总结"获取Java后端面试经验总结PDF版
10.回复"Redis"获取Redis命令手册,和Redis专项面试习题(PDF)
11.回复"并发导图"获取Java并发编程思维导图(xmind终极版)
另:点击【我的福利】有更多惊喜哦。
