一、开发环境
Myeclipse10+jdk7+tomcat7+Mysql5.5
二、集群配置情况:
1、机器配置
| 服务器节点 | CPU | 内存 | 硬盘 |
| Master | Intel Core i5 | 4GB | 1T |
| Slave1 | Intel Core i5 | 4GB | 1T |
| Slave2 | Intel Core i5 | 4GB | 1T |
| Slave3 | Intel Core i5 | 4GB | 1T |
| Mysql+Tomcat | Intel Core i5 | 4GB | 1T |
2、节点角色分配
| 主机名 | IP | 角色 |
| Master | 10.5.0.230 | NameNode、ResourceManager、SecondaryNameNode |
| Slave1 | 10.5.0.231 | DataNode、NodeManager |
| Slave2 | 10.5.0.232 | DataNode、NodeManager |
| Slave3 | 10.5.0.233 | DataNode、NodeManager |
3、集群架构图
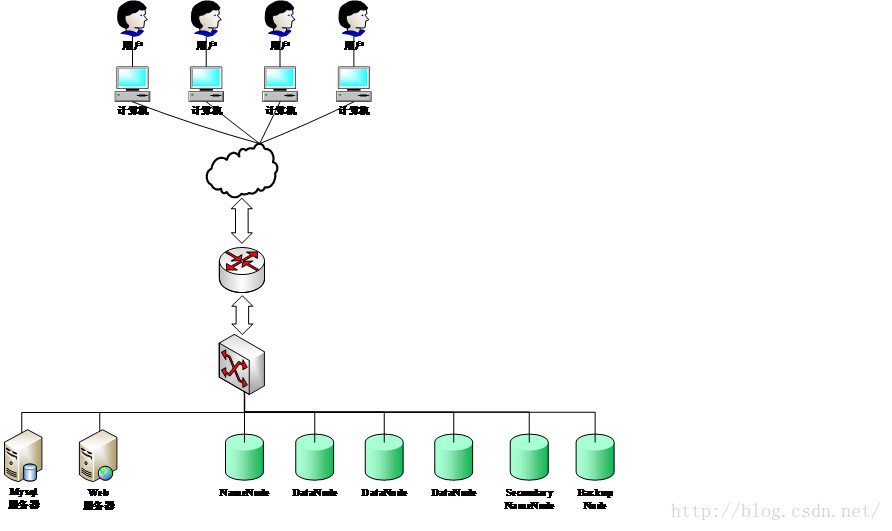
4、集群配置与测试
Hadoop集群使用Ubuntu Server版本操作系统,Mysql+Web服务器使用Ubuntu Desktop版,Mysql5.5、Tomcat7与Myeclipse2014安装在Mysql+Web服务器上。本集群使用Cloudra Hadoop开发的hadoop-2.6.0-cdh5.4.1 版本软件。
1) 配置Hadoop参数文件hadoop-env.sh
cd $HADOOP_HOME/etc/hadoop
sudo vi hadoop-env.sh

修改JAVA_HOME的值
export JAVA_HOME=/usr/lib/jvm/oracle-java8-installer
2) 配置masters参数文件
sudo vi masters
Master
3) 配置slaves参数文件
sudo vi slaves
Slave1
Slave2
Slave3
4) 配置参数文件core-site.xml
<configuration>
<property>
<name>fs.default.name</name> <value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> <value>file:/usr/local/cloudera/hadoop_tmp/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name> <value>131072</value>
</property>
<property>
<name>hadoop.native.lib</name> <value>true</value>
</property>
</configuration>
5) 配置参数文件hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name> <value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> <value>file:/usr/local/cloudera/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> <value>file:/usr/local/cloudera/hadoop_tmp/hdfs/datanode</value>
</property>
<property>
<name>dfs.permissions</name> <value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name> <value>true</value>
</property>
<property>
<name>dfs.blocksize</name> <value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name> <value>20</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name> <value>65535</value>
</property>
</configuration>
6) 将Master上配置好的Hadoop文件复制到Slave节点上
sudo apt-get install rsync
sudo rsync -avxP
/usr/local/cloudera/ hadoop@Slave1:/usr/local/cloudera/
sudo rsync -avxP
/usr/local/cloudera/ hadoop@Slave2:/usr/local/cloudera/
sudo rsync -avxP
/usr/local/cloudera/ hadoop@Slave3:/usr/local/cloudera/
7) Hadoop集群格式化文件系统启动
hadoop namenode -format
./usr/local/cloudera/hadoop-2.6.0-cdh5.4.1/sbin/start-all.sh
8) 验证集群是否成功启动
① 在Master节点查看NameNode、ResourceManager进程是否启动
② 在Slave节点查看DataNode、NodeManager进程是否启动
③ 通过浏览器浏览Hadoop的web管理界面:http://master:50070,查看数据节点是否可用
④ 运行Hadoop命令在HDFS上创建目录和上传文件
hadoop fs -mkdir /input
hadoop fs -put /home/hadoop/test_pefeader/file1.txt /input/
⑤ 查看目录下上传的文件
hadoop fs -ls /input/
三、Web界面
1、登陆界面

2、注册界面

3、主界面

通过访问Hadoop的NameNode节点的管理页面,也可以看到上传的文件。
地址:http://master:5007/explorer.html#/user/perfeader

四、主要功能实现
1、 文件上传模块
文件上传分为两个步骤。首先,把文件上传到tomcat服务器的/UsersFiles目录下,并且上传的文件重新命名,防止多用户上传重名文件。在UsersFiles目录下把文件再上传到Hadoop的HDFS文件系统中。具体代码实现如下所示。
以下是上传文件方法代码:
public ActionForward execute(ActionMapping mapping, ActionForm form,HttpServletRequest request, HttpServletResponse response){
……
FormFile file=fileForm.getFile(); //得到上传的文件
int fileSize=file.getFileSize();//得到文件的大小
//进行文件大小判断,最大为500M
if(fileSize>1024*1024*500){
//判断文件类型
if(fileType.equals("1")){
queryByPage(request,pageNow,"1","1",user);}
else{
queryByPage(request,pageNow,"files_type",fileType,user);
}
request.setAttribute("msg", "文件太大");
<p> return mapping.findForward("ok");
}
//得到上传文件的名称
String fileName=file.getFileName();
//得到文件上传到服务器的保存路径
String keepFilePath=this.getServlet().getServletContext().getRealPath("/UsersFiles");
String newFileName=GetNewFileNameTool.getNewFileName(fileName);
String fn = newFileName.substring( newFileName.lastIndexOf("/")+1);
//创建文件对象
Files files=new Files(GetTimeIdTool.getId(new Date().toLocaleString()),user.getUserid(),fileName,newFileName,GetFileSizeTool.getFileSize(fileSize), keepFilePath,new Date().toLocaleString(),GetFileTypeTool.getFileType(fileName));
filesService=new FilesService();
//得到文件的输入流
try {
is=file.getInputStream();
System.out.println(keepFilePath);
System.out.println(newFileName);
if(UpLoadTool.uploadServer(keepFilePath, newFileName, is)&&filesService.inputFile(files)){
//判断文件类型
if(fileType.equals("1")){
queryByPage(request,pageNow,"1","1",user);</p><p> }else{
queryByPage(request,pageNow,"files_type",fileType,user);</p><p> }
request.setAttribute("msg", "上传成功");
//从Tomcat服务器上传文件到Hadoop集群HDFS分布式文件系统
//定义HDFS的参数
HdfsDAO hdfs = new HdfsDAO( new Configuration());
//调用HDFS的Copyfile方法
hdfs.copyFile("/home/hadoop/test_perfeader/apache-tomcat-7.0.64/webapps/CampusCloud/UsersFiles/"+fn,"hdfs://10.5.0.230:9000/user/perfeader/");
return mapping.findForward("ok");
}else{//判断文件类型
if(fileType.equals("1")){
queryByPage(request,pageNow,"1","1",user);
}else{
queryByPage(request,pageNow,"files_type",fileType,user);
}
request.setAttribute("msg", "上传失败");
return mapping.findForward("ok");
}
}
……
}</p>接下来,文件通过Tomcat服务器上传到Hadoop的HDFS系统中,方法关键代码如下:
public void copyFile(String local, String remote) throws IOException {
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.copyFromLocalFile(new Path(local), new Path(remote));
System.out.println("copy from: " + local + " to " + remote);
fs.close();
}2) 文件下载模块
文件下载模块是首先判断文件是否在Tomcat服务器上的目录下存在,如果存在直接从Tomcat服务器下载。如果不存在,首先在Hadoop系统通过HDFS文件系统下载文件到Tomcat服务临时文件目录下,再从Tomcat服务器上下载下来。
以下是下载文件方法代码:
//定义对象
FilesService filesService=null;
public void doGet(HttpServletRequest request, HttpServletResponse response){
try {
……
//设置一个头,告诉浏览器有文件下载
String fileName=java.net.URLEncoder.encode(file.getName(), "utf-8");
response.setHeader("Content-Disposition","attachment;filename="+fileName);
//获取到要下载文件的绝对路径
String filePath=this.getServletContext().getRealPath("/UsersFiles");
String fileAllPath=filePath+"/"+file.getNewname();
FileInputStream fis=null;
OutputStream os=null;
byte[] buffer=new byte[1024];
int len=0;
try {
File f=new File(fileAllPath);
if(!f.exists()){
//从Tomcat服务器上传文件到Hadoop集群HDFS分布式文件系统
//定义HDFS的参数
HdfsDAO hdfs = new HdfsDAO( new Configuration());
//调用HDFS的Download方法
hdfs.download("hdfs://10.5.0.230:9000/user/perfeader/"+file.getNewname(),"/home/hadoop/test_perfeader/apache-tomcat-7.0.64/webapps/CampusCloud/UsersFiles/");}
fis=new FileInputStream(fileAllPath);
os=response.getOutputStream();
while((len=fis.read(buffer))>0){
os.write(buffer, 0, len);
}
}
……
}
}接下来,文件从Hadoop的HDFS系统下载文件到Tomcat服务器,方法关键代码如下:
public void download(String remote, String local) throws IOException {
Path path = new Path(remote);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.copyToLocalFile(path, new Path(local));
System.out.println("download: from" + remote + " to " + local);
fs.close();
}3) 文件删除模块
文件删除模块是当用户选中要删除的文件后,首先在Tomcat上删除文件,然后在HDFS上把相应的文件删除,最后在数据库中删除文件的基本信息。
以下是删除文件方法代码:
public void doGet(HttpServletRequest request, HttpServletResponse response)throws ServletException, IOException
{
……
//得到文件上传到服务器的保存路径
String keepFilePath=this.getServletContext().getRealPath("/UsersFiles");
//接收
String string=request.getParameter("id");
String[] strs=string.split(",");
filesService=new FilesService();
HdfsDAO hdfs = new HdfsDAO( new Configuration());
for(int i=0; i<strs.length;i++){
DeleteFileTool.deleteFile(filesService.getNewFileName(strs[i]),keepFilePath);
hdfs.rmr("hdfs://10.5.0.230:9000/user/perfeader/"+filesService.getNewFileName(strs[i]));
filesService.deleteFilesById(strs[i]);
}
Users user=(Users)request.getSession().getAttribute("user");
if(user==null){
request.getRequestDispatcher("logon.jsp").forward(request, response);
return;
}
……
}接下来,从Hadoop的HDFS系统中删除文件,方法关键代码如下:
public void rmr(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.deleteOnExit(path);
System.out.println("Delete: " + folder);
fs.close();
}4) 文件查询模块
以下是查询文件方法代码:
public ActionForward execute(ActionMapping mapping, ActionForm form,HttpServletRequest request, HttpServletResponse response){
SearchForm searchForm = (SearchForm) form;
String fileName=searchForm.getFileName();
Users user=(Users)request.getSession().getAttribute("user");
filesService=new FilesService();
queryByPage(request, 1, "files_name", fileName, user);
return mapping.findForward("ok");
}