单机存储系统就是单机存储引擎的一种封装,而单机存储引擎分为:
哈希存储引擎
Bitcask是一个基于哈希表结构的键值存储结构。
它的特点是写时追加,也就是说它每次在文件中只会追加数据而不会修改,所以文件大小超过限制时,会新建一个活跃数据文件,而达到大小限制的文件就叫作老数据文件。
Bitcask的数据结构:

内存中哈希索引表的数据结构:

- 读取操作:用内存中的哈希索引表的数据结构,通过主键找到对应的文件编号,value长度和位置,就可以在活跃数据文件找到对应item(每一个item都是Bitcask数据结构),得到value值。
- 删除:原item的value中存入删除标记。
- 新增:直接添加一条item条目。
- 更新:原item不变,跟新增操作一样。
定期合并:Bitcask系统中的记录删除后者更新后都会让原来的数据变为垃圾文件,所以要进行定期合并,对同一个key只保留最新的一个。
快速恢复:哈希索引表存在内存中,一旦断电,重建这个哈希索引表需要扫一遍磁盘中的数据文件,为了加快重建速度,Bitcask通过索引文件来提高重建hash表的速度。索引文件其实就是内存中的哈希索引表转储到磁盘生成的结果文件。
B树存储引擎
Mysql的Innodb是按照页来组织数据的,也就是说内存中存储的是页,对应B+树的一个节点。
- 查询:从B+树的根节点开始进行二分查找知道找到叶子节点,而且每次读取一个节点,如果页不在内存中,则需要从磁盘中读取出来并把对应的页缓存起来。
- 修改:首先需要记录提交日志,然后再修改内存中的B+树。内存中修改的页超过一定比率,就会将页面刷新到磁盘中持久化。
缓存区管理
基本的LRU:将近期访问的item存到一个链表中,每次新访问的item加到链表头部,同时淘汰掉链表尾部item(即最近最少访问到的item被淘汰掉)。
存在的问题1:如每次访问item都要更新一次LRU链表,都需要对整个LRU加锁
存在的问题2:若果一次查询中扫描了大量的item数据,则会导致缓存池LRU链表中的大部分或者全部数据被替换掉,从而污染缓存池。
改进的LRU:
对问题1:牺牲精度来减小锁粒度
分段LRU链表(如Mysql):将LRU链表分为前后两部分,如果访问的item在前部分则不进行任何操作,即不用将该item移动到 头部。只有在后半部分时才加锁,移动到头部。
计时LRU链表(如memcached):链表的每个节点item都存储一个最近访问时间,每次访问该item时,只有当距离上次访问时间 操作某个设定值才会移动该item到链表头部。
块LRU链表(如OceanBase):链表的每个节点不是单独的一个item数据记录而是以块比如2MB的内存块。每次移动或者淘汰都 以块为基本单位。每个块保存一个访问计数和最近访问时间,每次访问块中的任何一个item都会将该块的访问计数加1,当该块的访问计数达到某个设定值(比如所有块的平均访问次数)时就更新该块的最近访问时间。按块的最近访问时间来淘汰块。
对问题2:分级缓存
LIRS算法(如MySQL InnoDB):LIRS将数据分为两部分:LIR(Low Inner-reference Recency)和HIR(High Inner-reference Recency),其中,LIR中的 数据是热点,在较短的时间内被访问了至少两次。LIRS可以看成是一种分级思想:第一级是HIR,第二级是LIR,数据先进入到第一级,当数据在较短的时间内被访问两次时成为热点数据则进入LIR,HIR和LIR内部都采用LRU策略。这样,LIR中的数据比较稳定。类似的,如可以实现两级cache,cache元素先进入第一级cache,当访问频率达到一定值(比如2)时升级到第二级,第一级和第二级均内部采用LRU进行替换。
LSM树存储引擎
LSM的基本思想就是将的数据的修改增量保存在内存中,当内存达到大小限制后将这些增量数据批量写入磁盘,读取时需要合并磁盘中的历史数据和内存中的增量数据。
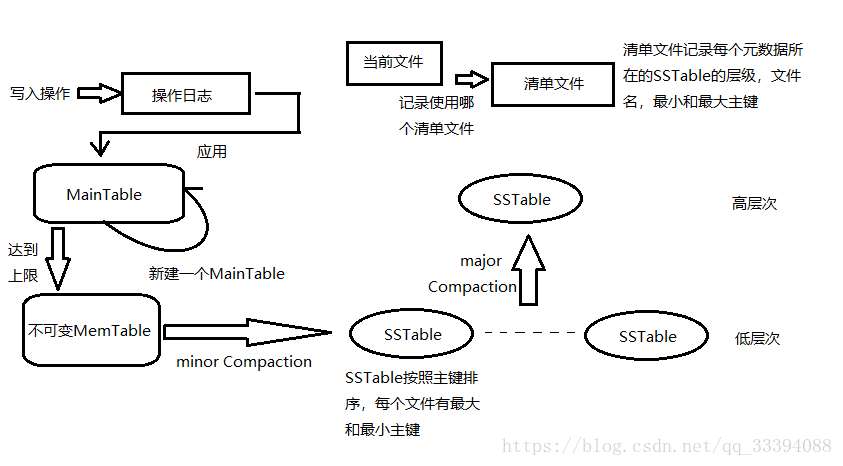
- 当应用写入一条记录时,LevelDB会首先将修改操作写入到操作日志文件,成功后再将修改操作应用到MemTable,这样就完成了写入操作。
- 当MemTable占用的内存达到一个上限值后,需要将内存的数据转储到外存文件中。LevelDB会将原先的MemTable冻结成为不可变MemTable,并生成一个新的MemTable。新到来的数据被记入新的操作日志文件和新生成的MemTable中。
- LevelDB后台线程会将不可变MemTable的数据排序后转储到磁盘,形成一个新的SSTable文件,这个操作称为minor Compaction。
SSTable中的文件是按照记录的主键排序的,每个文件有最小的主键和最大的主键。 - 当某个层级下的SSTable文件数目超过一定设置值后,levelDB会从这个层级中选择SSTable文件,将其和高一层级的SSTable文件合并,这就是major compaction。
- LevelDB的清单文件记录了所有元数据,包括属于哪个层级、文件名称、最小主键和最大主键,它会随着Compaction进行而重新生成新的清单文件,所以需要当前文件来记录了当前使用的清单文件名。
LevelDB写入操作很简单,但是读取操作比较复杂,需要先查看内存中的MemTable,然后在不可变MemTable中查找,接下来再从SSTable文件中读取。