1. 基本概念
1.1 NameNode
HDFS采用Master/Slave架构。NameNode就是HDFS的Master架构。HDFS系统包括一个NameNode组件,主要负责HDFS文件系统的管理工作,具体包括名称空间(namespace)管理,文件Block管理。NameNode提供的是始终被动接收服务的server,主要有三类协议接口:
- ClientProtocol接口,提供给客户端,用于访问NameNode。它包含了文件的HDFS功能。和GFS一样,HDFS不提供POSIX形式的接口,而使用了一个私有接口。
- DataNodeProtocol接口,用于DataNode向NameNode通信。
- NameNodeProtocol接口,用于从NameNode到NameNode的通信。
在HDFS内部,一个文件被分成一个或多个Block,这些Block存储在DataNode集合里,NameNode就负责管理文件Block的所有元数据信息,这些元数据信息主要为:
- “文件名→数据块”映射
- “数据块→DataNode列表”映射
- 文件owership和permissions(文件权限)
- 文件大小,时间
其中,“文件名→数据块”保存在磁盘上进行持久化存储,需要注意的是NameNode上不保存“数据块→DataNode列表”映射,该列表是通过DataNode上报给NameNode建立起来的。
1.2 SecondaryNameNode
SecondaryNameNode其主要是定时对NameNode的数据snapshots进行备份,这样可尽量降低NameNode崩溃之后导致数据丢失的风险,其所做的工作就是从NameNode获得fsimage和edits后把两者重新合并发给NameNode,这样,既能减轻NameNode的负担又能安全地备份,一旦HDFS的Master架构失效,就可以借助Secondary NameNode进行数据恢复。SecondaryNameNode的主要工作是帮助NameNode合并edits log,减少NameNode的启动时间。
1.3 DataNode
DataNode就是负责存储数据的组件,一个数据块Block会在多个DataNode中进行冗余备份;而一个DataNode对于一个块最多只包含一个备份。所
以可以简单地认为DataNode上存储了数据块ID和数据块内容以及它们的映射关系。
过DataNode启动时的上报来更新NameNode上的映射表。DataNode和NameNode建立连接后,就会不断地和NameNode保持联系,反馈信息中也包含了NameNode对DataNode的一些命令,如
删除数据库或者把数据块复制到另一个DataNode。当然DataNode也作为服务器接受来自客户端的访问,处理数据块读/写请求。DataNode之间还会进行通信,执行数据块复制的任务。
1.4 客户端
访问HDFS的程序或HDFS shell命令都可以称为HDFS的客户端(client),在HDFS的客户端中至少需要指定HDFS集群配置中的NameNode地址以及端口号信息,或者通过配
置HDFS的core-site.xml配置文件来指定。
1.5 块(Block)
HDFS为了满足大数据的效率和整个集群的吞吐量选择了更大的数值,默认是128M。
客户端在读取HDFS上的一个文件时就以块为基本的数据单元。例如一次简单读取,首先,客户端把文件名和程序指定的字节偏移,根据固定的Block大小,转换成文件的Block索引。然后,客户端把文件名和Block索引发送给Master节点,Master节点将相应的Block标识和副本的位置信息返回给客户端,客户端用文件名和Block索引作为key缓存这些信息,之后客户端发送请求到其中的一个副本,一般会选择最近的。请求信息包含了Block的标识和字节范围。在对这个Block的后续读取操作中,客户端不必再和Master节点通信了,除非缓存的元数据信息过期或文件被重新打开。实际上,客户端通常会在一次请求中查询多个Block信息,Master节点的回应也可能包含了紧跟着这些被请求的Block后面的Block的信息。在实际应用中,这些额外的信息在不花费任何代价的情况下,避免了客户端和Master节点未来可能会发生的几次通信。
2. HDFS的特性和目标
2.1 HDFS的特性
- 高容错,可扩展以及可配置性强
- 跨平台
- Shell命令接口
- Web界面
- 文件权限和授权。
- 机架感知功能。
- 安全模式。
- Rebalacner。
- 升级和回滚程序。
2.2 HDFS的目标
- 硬件错误
- 流式数据的访问
- 大规模数据集
- 简化一致性模型
- 移动计算代价比移动数据代价低
- 可移植性
3. HDFS架构
NameNode负责管理文件系统的命令空间和客户端对文件的访问:DataNode是数据存储节点,所有的这些集群通常是普通运行的Linux机器,运行着用户级别的服务进程。
3.1 Master/Slave架构
HDFS架构如下图所示:
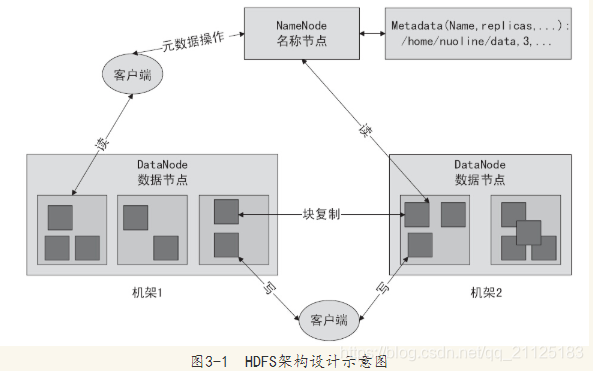
NameNode负责保存和管理所有的HDFS元数据,因而用户数据就不需要通过NameNode,也就是说文件数据的读写是直接在DataNode上进行的。在默认情况下,HDFS使用三个冗余备份,当然用户可以为不同的文件命名空间设定不同的复制因子。Namenode管理所有的文件系统元数据。这些数据包括空间、访问控制信息、文件和Block的映射信息,以及当前Block的位置信息。
客户端利用NameNode的通信只获取元数据,所有的数据操作都是由客户端直接和DataNode服务器进行交互的。
3.2 NameNode和SecondaryNameNode通信模型
NameNode将对文件系统的改动追加保存到本地文件系统上的一个日志文件edits。当一个NameNode启动时,它首先从一个映像文件(fsimage)中读取HDFS的状态,接着执行日志文件中的编辑操作。然后将新的HDFS状态写入fsimage中并使用一个空的edits文件开始正常操作。因为NameNode只有在启动阶段才合并fsimage和edits,久而久之日志文件可能会变得非常庞大,特别是对于大型的集群日志文件太大的另一个副作用是下一次NameNode启动会花很长时间,NameNode和Secondary NameNode之间的通信示意图如图
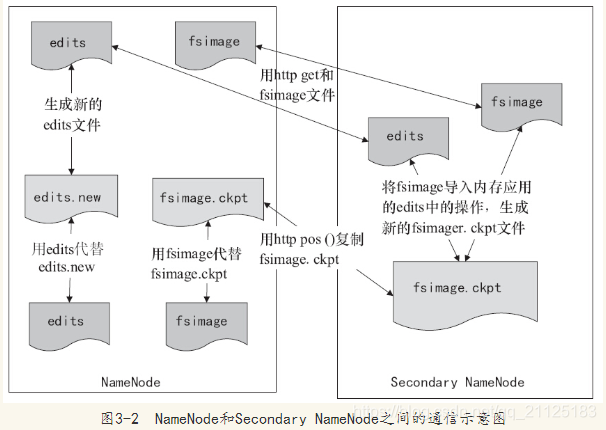
NameNode和Secondary NameNode间数据的通信使用的是HTTP协议,SecondaryNameNode定期合并fsimage和edits日志,将edits日志文件大小控制在一个限度下。因为内存需求和NameNode在一个数量级上,所以通常Secondary NameNode和NameNode运行在不同的机器上。Secondary NameNode通过bin/start-dfs.sh在conf/masters中指定的节点上启动。
Secondary NameNode的检查点进程启动,是由以下两个配置参数控制的
- fs.checkpoint.period 指定两次连续检查点的最大时间间隔,默认是一个小时。
- fs.checkpoint.size 定义了日志文件的最大值,一旦超过这个值就会导致强制执行检查点,默认是64M
3.3 文件读取机制
在读取HDFS的文件时,首先客户端调用FileSystem的open()函数打开文件,DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。对于每一个数
据块,元数据节点返回保存数据块的数据节点的地址。DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。客户端调用stream的read()函数开始读
取数据。DFSInputStream连接保存此文件第一个数据块的最近的数据节点。Data从数据节点读到客户端,当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连
接,然后连接此文件下一个数据块的最近的数据节点。当客户端读取完数据的时候,调用FSDataInputStream的close函数。客户端读取HDFS中的文件访问数据流的整个过程
如图所示。图中的操作序号1、2、3、4、5表示执行顺序,读取文件的数据流步骤如下:
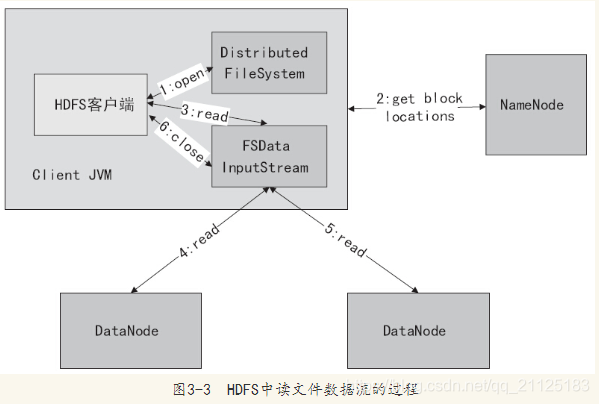
1)调用FileSystem的open()打开文件,见序号1:open。
2)DistributedFileSystem使用RPC调用NameNode,得到文件的数据块元数据信息,并返回FSDataInputStream给客户端,见序号2:get block locations
3)HDFS客户端调用stream的read()函数开始读取数据,见序号3:read。
4)调用FSDataInputStream直接从DataNode获取文件数据块,见序号4 5read。
5)读完文件时,调用FSDataInputStream的close函数,见序号6:close。
3.4 文件写入机制

-
首先客户端调用create()来创建文件,然后DistributedFileSystem同样使用RPC调用NameNode元数据节点,在文件系统的命名空间中创建一个新的文件。
-
NameNode首先确定文件原来不存在,以及客户端有创建文件的权限,然后创建新文件。
-
DistributedFileSystem返回DFSOutputStream,客户端用于写数据。客户端开始写入数据,DFSOutputStream将数据分成块,写入Data Queue。Data Queue由Data
Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。 -
分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点,第二个数据节点将
数据发送给第三个数据节点。 -
DFSOutputStream为发出去的数据块保存了Ack Queue,等待pipeline中的数据节点告知数据已经写入成功。如果数据节点在写入的过程中失败,
则关闭pipeline,同时将Ack Queue中的数据块放入Data Queue的开始位置。
4. HDFS核心设计
4.1 Block大小
- 选择较大的Block尺寸有几个优点:首先,它减少了客户端和NameNode通信的需求,因为只需要一次和NameNode节点的通信就可以获取Block的位置信息,之后就可以通过对同一个Block进行多次的读写操作。
- 结合惰性空间分配,采用较大的Block尺寸也有缺陷。小文件包含较少的Block,甚至只有一个Block,当有许多的客户端对同一个小文件进行多次访问的时候,存储这些Block的DataNode服务器就会变成一个访问热点。
4.2 数据复制
HDFS被设计成在一个大集群中可以跨机器可靠地存储海量的文件。它将每个文件存储成Block序列,除了最后一个Block,所有的Block都是同样的大小。文件的所有Block为了容错都会被冗余复制存储。每个文件的Block大小和Replication因子都是可配置的。
4.3 数据副本存放策略
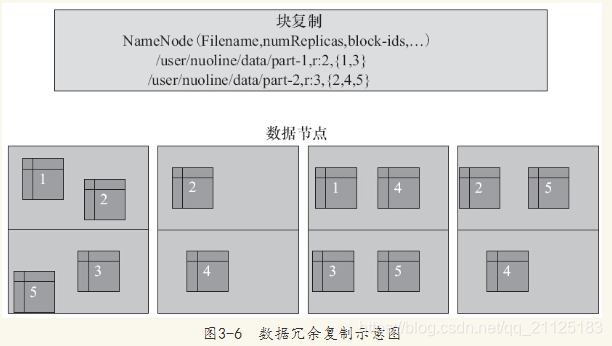
副本的存放是HDFS可靠性和高性能的关键。优化的副本存放策略是HDFS区分于其他大部分分布式文件系统的重要特性。这种特性需要做大量的调优,并需要经验的积累。HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性、可用性和网络带宽的利用率。
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在于第一个副本不同的 机架的节点上。
- 第三个副本:与第二个副本相同机架的节点。
- 更多副本:随机节点
在这种策略下,副本并不是均匀分布在不同的机架上。三分之一的副本在一个节点上,三分之一的副本在同一个机架的其他节点上,其他副本均匀分布在剩下的机架中,这一策略在不损害数据可靠性和读取性能的情况下改进了写的性能。
为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副
本。如果读取程序的同一个机架上有一个副本,那么就读取该副本;如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读取本地数据中心的副本。
4.4 数据组织
4.4.1 数据块
HDFS最适合的应用场景是处理大数据集合,同时这些应用大多是一次写入多次读取,并且读取的数据要满足流式读取,即write-once-read-many语义。
4.4.2 Staging
事实上,HDFS客户端会将文件数据缓存到本地的一个临时文件中,应用写文件时被透明地重定向到这个临时文件。当这个临时文件累积的数据超过一个Block的大小(默认为64MB),客户端才会联系NameNode。NameNode将文件名插入文件系统的层次结构中,并且分配一个数据块给它,然后返回DataNode的标识符和目标数据块给客户端。客户端将本地临时文件flush到指定的DataNode上。当文件关闭时,在临时文件中剩余的没有flush的数据也会传输到指定的DataNode,然后客户端告诉NameNode文件已经关闭。此时NameNode才将文件创建操作提交到持久存储如果NameNode在文件关闭前挂机,该文件将丢失。
4.4.3 流水线式的复制
当某个客户端向HDFS文件写数据的时候,一开始是写入本地的临时文件,假设该文件的replication因子为3,那么客户端会从NameNode获取一张DataNode列表来存放副本。然后客户端开始向第一个DataNode传输数据,第一个DataNode会一小部分一小部分(4KB)地接收数据,将每个部分写入本地仓库,同时传输该部分到第二个DataNode。第二个DataNode也是这样,边收边传,一部分一小部分接收,将每个部分存储到本地仓库。
4.5 空间回收
4.5.1 文件的删除和恢复
当用户或应用程序删除某个文件,这个文件并没有立刻从HDFS中删除。而是被转移到trash目录下。
4.5.2 减少副本系数
在减少某个文件的副本系数之后,NameNode会选择要删除过剩的副本。下次心跳检查就将该信息传递给DataNode,DataNode就会移除相应的Block并释放空间。
4.6 通信协议
所有的HDFS的通信协议都是构建在TCP/IP之上的
4.7 安全模式
安全模式是这样一种特殊状态:当系统处于这个状态时,不接受任何对名称空间的修改,同时也不会对数据块进行复制或删除。NameNode在启动的时候会自动进入安全模式,也可以手动进入(不会自动离开)。NameNode从所有的DataNode接收心跳信号和块状态报告。块状态报告包括了某个DataNode所有的数据块列表,每个数据块都有一个指定的最小副本数。当NameNode检测确认某个数据块的副本数目达到这个最小值时,该数据块就会被认为是副本安全(safely replicated)的;在一定百分比(这个参数可配置)的数据块被NameNode检测确认是安全的之后(加上一个额外的30秒等待时间),NameNode将退出安全模式状态。
NameNode退出安全模式之后会确定还有哪些数据块副本没有达到指定的数目,并将这些数据复制到其他DataNode上去。
4.8 机架感知
在通常情况下,大型Hadoop集群是以机架的形式来组织的,同一个机架上不同节点间的网络状况比不同机架之间的更为理想。需要程序员进行手动配置。
4.9 健壮性
HDFS的主要目标就是实现在失败情况下数据存储的可靠性。常见的三种失败情况是:NameNode failures、DataNode failures和网络分割(network partitions),这
几种失败很容易导致HDFS中的组件失效。下面将分别从数据错误、集群均衡、数据完整性、元数据磁盘错误,以及快照五个方面阐述HDFS的健壮性设计
4.9.1.数据错误
每个DataNode都向NameNode周期性地发送心跳包。网络切割可能会导致部分DataNode与NameNode失去联系。NameNode可通过心跳包的缺失检测到这一情况,并将这些DataNode标记为dead,不会向它们发送IO请求,寄存在deadDataNode上的任何数据将不再有效。
4.9.2 集群均衡
HDFS支持数据的均衡计划,如果某个DataNode上的空闲空间低于特定的临界点,那么就会启动一个计划——自动将数据从一个DataNode搬移到空闲的DataNode。
4.9.3 数据完整性
从某个DataNode获取的数据块有可能是已损坏的,损坏可能是由于DataNode的存储设备错误、网络错误或者软件bug造成的。HDFS客户端软件实现了HDFS文件内容的校验和。当某个客户端创建一个新的HDFS文件,会计算这个文件的每个Block的校验和,并作为一个单独的隐藏文件保存这些校验和在同一个HDFS namespace下。当客户端检索文件内容,它会确认从DataNode获取的数据跟相应的校验和文件中的校验和是否匹配,如果不匹配,客户端可以选择从其他DataNode获取该Block的副本。
4.9.4 元数据磁盘错误
FsImage和Editlog是HDFS的核心数据结构。这些文件如果损坏了,整个HDFS实例都将失效。因而,NameNode可以配置成支持维护多个FsImage和Editlog的副本。任何
对FsImage或Editlog的修改,都将同步到它们的副本上。
4.9.5 快照
快照支持某个时间的数据副本,当HDFS数据损坏的时候,可以恢复到过去一个已知的正确时间点
5. 负载均衡
当新增一个数据块(一个文件的数据被保存在一系列的块中)时,NameNode在选择DataNode接收这个数据块之前,要考虑到很多因素。其中的一
些因素如下:
- 将数据块的一个副本放在正在写这个数据块的节点上。
- 尽量将数据块的不同副本分布在不同的机架上,这样集群可在完全失去某一机架的情况下还能存活。
- 一个副本通常被放置在和写文件的节点同一机架的某个节点上,这样可以减少跨越机架的网络I/O。
- 尽量均匀地将HDFS数据分布在集群的DataNode中。
由于上述多种考虑需要取舍,数据可能并不会均匀分布在DataNode中。当HDFS出现不平衡状况的时候,将引发很多问题,比如MapReduce程序无法很好地利用本地计算的优势,机器之间无法达到更好的网络带宽使用率、机器磁盘无法利用等。可见,保证HDFS中的数据平衡是非常重要的。为此,HDFS为管理员提供一个工具,用于分析数据分布和重新均衡DataNode上的数据分布:
$HADOOP_HOME/bin/start-balancer.sh -t 10%
-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率的偏差值小于10%。那么我们就可以认为HDFS集群已经达到了平衡状态。
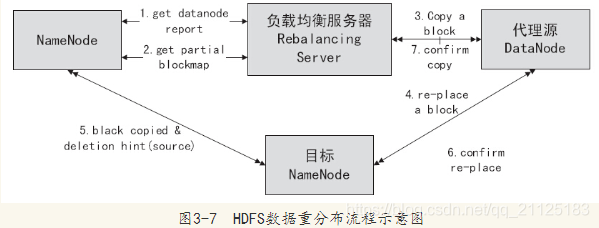
负载均衡程序作为一个独立的进程与NameNode进行分开执行。从图中可以看到,HDFS负载均衡的处理步骤如下:
1)负载均衡服务Rebalancing Server从NameNode中获取所有的DataNode情况,具体包括每一个DataNode磁盘使用情况,见图3-7中的流程1.get datanode report。
2)Rebalancing Server计算哪些机器需要将数据移动,哪些机器可以接受移动的数据,以及从NameNode中获取需要移动数据的分布情况,见图3-7中的流程2.get partial
blockmap。
3)Rebalancing Server计算出来可以将哪一台机器的Block移动到另一台机器中去,见图中流程3.copy a block。
4)需要移动Block的机器将数据移动到目标机器上,同时删除自己机器上的Block数
据,见图中的流程4、5、6。
5)Rebalancing Server获取本次数据移动的执行结果,并继续执行这个过程一直到没有数据可以移动或HDFS集群已经达到平衡的标准为止,见图中的流程7。
6. HDFS权限管理
HDFS系统实现了一个和POSIX系统类似的文件和目录权限管理模型。每个用户和目录由一个所有者(owner)和一个组(group)。文件或者目录对其所有者、同组下的其他用户,已经所有其他用户分别有着不同的权限。对目录而言,当列出目录内容时需要具有r权限,当新增或者删除目录中子节点需要w权限。当访问目录的子节点时需要x权限。
每个访问HDFS的用户进程的标识分为两个部分,分别是用户名和组名列表。例如,当用户进程访问一个HDFS上的文件或目录app时,HDFS都要对其进行权限检查。
6.1 用户身份
HDFS权限管理类似与UNIX的机制,文件用户分为文件属性主、文件组和其他用户,权限分为读、写、执行。
6.2 超级用户
超级用户即运行NameNode进程的用户。宽泛地讲,如果你启动了NameNode,你就是超级用户。超级用户可以干任何事情,因为超级用户能够通过所有的权限检查。
7. HDFS缺点
- 访问延迟:HDFS不太适合那些低延迟(数十毫秒)访问的应用程序,HDFS的设计主要是为了用于大吞吐量的数据,这是以一定的延迟为代价的。
- 对大量小文件的处理:因为NameNode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数量时NameNode的内存大小
了让HDFS能够处理好小文件,建议使用以下方法:
1)利用SequenceFile、MapFile、Har等方式归档小文件。这个方法的原理就是把小文件进行归档管理,HBase就是基于此的。对于这种方法,如果想找回原来的小文件
内容,就必须得知道其与归档文件的映射关系。
2)横向扩展。既然一个Hadoop集群能管理的小文件数量有限,那就把几个Hadoop集群拖在一个虚拟服务器后面,形成一个大的Hadoop集群。Google就这么干
过。
3)多Master设计。这个作用显而易见。正在研发中的GFS II要改为分布式多Master设计,还要支持Master的Failover,而且Block大小也要改为1M,要有意调优处
理小文件。
- 多用户写,任意文件修改:目前Hadoop只支持单用户写,不支持并发多用户写。可以使用Append操作在文件的末尾添加数据,但不支持在文件的任意位置进行修改。