使用scrapy爬取新浪新闻
思路:通过观察,获取某节点作为当前节点,然后依次遍历大类链接 小类链接 子链接
要点:注意item和meta参数的使用。详情见代码newsina.py里面相关的注释
总结:个人因为item的位置,导致浪费了好多时间。
流程如下:
创建爬虫项目sina2
scrapy startproject sina2设置items.py文件,存储要爬取的数据类型及字段名字
# -*- coding: utf-8 -*- import scrapy class Sina2Item(scrapy.Item): # 大类链接和url,如新闻 体育等 parentUrl = scrapy.Field() parentTitle = scrapy.Field() # 小类链接和url,如新闻下面的国内 社会等 subUrl = scrapy.Field() subTitle = scrapy.Field() # 小类存储路径 subpath = scrapy.Field() # 子链接 sonUrl = scrapy.Field() # 子链接里面的标题和内容 head = scrapy.Field() content = scrapy.Field()创建爬虫文件newsina.py
# -*- coding: utf-8 -*- import os import scrapy from sina2.items import Sina2Item class NewsinaSpider(scrapy.Spider): name = 'newsina' allowed_domains = ['sina.com.cn'] start_urls = ['http://news.sina.com.cn/guide/'] def parse(self, response): # 通过某节点作为根节点进行大类链接遍历 for each in response.xpath("//div[@id='tab01']/div[@data-sudaclick!='citynav']"): # 获取大类链接和大类标题 parentUrl = each.xpath('./h3/a/@href').extract()[0].encode('utf-8') parentTitle = each.xpath('./h3/a/text()').extract()[0].encode('utf-8') # 设置大类存储路径 parentpath = './data/' + parentTitle if not os.path.exists(parentpath): os.makedirs(parentpath) # 遍历小类链接 for other in each.xpath("./ul/li/a"): # 获取以大类链接开头的小类链接 if other.xpath('./@href').extract()[0].startswith(parentUrl): # 注意item的位置,不同的位置会导致不同的结果。尽量不要把item的数据在外循环和内循环里面分别获取,如必须这样做,则创建空列表添加item来解决。 item = Sina2Item() subUrl = other.xpath('./@href').extract()[0].encode('utf-8') subTitle = other.xpath('./text()').extract()[0].encode('utf-8') subpath = parentpath + '/' + subTitle item['parentUrl'] = parentUrl item['parentTitle'] = parentTitle item['subUrl'] = subUrl item['subTitle'] = subTitle item['subpath'] = subpath if not os.path.exists(subpath): os.makedirs(subpath) # 发送小类链接请求,使用meta参数把item数据传递到回调函数里面,通过response.meta['']得到数据 yield scrapy.Request(url=item['subUrl'],meta={'meta_1':item},callback=self.second_parse) def second_parse(self,response): # 获取meta参数里面键为'meta_1'的值 meta_1 = response.meta['meta_1'] items = [] # 遍历小类里面的子链接 for each in response.xpath('//a/@href'): # 获取的子链接,以大类链接开头,以.shtml结尾 if each.extract().encode('utf-8').startswith(meta_1['parentUrl']) and each.extract().encode('utf-8').endswith('.shtml'): item = Sina2Item() item['parentUrl'] = meta_1['parentUrl'] item['parentTitle'] = meta_1['parentTitle'] item['subUrl'] = meta_1['subUrl'] item['subTitle'] = meta_1['subTitle'] item['subpath'] = meta_1['subpath'] item['sonUrl'] = each.extract().encode('utf-8') items.append(item) # 发送子链接请求 for each in items: yield scrapy.Request(each['sonUrl'],meta={'meta_2':each},callback=self.detail_parse) def detail_parse(self,response): item = response.meta['meta_2'] # 获取标题和内容不为空的子链接 # if len(response.xpath("//h1[@class='main-title']/text()")) != 0 and len(response.xpath("//div[@class='article']/p/text()")) != 0: # item['head'] = response.xpath("//h1[@class='main-title']/text()").extract()[0].encode('utf-8') # item['content'] = ''.join(response.xpath("//div[@class='article']/p/text()").extract()).encode('utf-8') # yield item item['head'] = response.xpath("//h1[@class='main-title']") item['content'] = ''.join(response.xpath("//div[@id='artibody']/p/text()").extract()).encode('utf-8') yield item创建管道pipelines.py文件
# -*- coding: utf-8 -*- class Sina2Pipeline(object): def process_item(self, item, spider): # 设置保存的文件名,把子链接去掉'http://'和'.shtml',把'/'替换成‘_’,保存为txt文件格式 self.filename = item['sonUrl'][7:-6].replace('/','_') + '.txt' self.file = open(item['subpath'] + '/' + self.filename,'w') self.file.write(item['sonUrl'] + '\n' + item['content']) self.file.close() return item修改配置settings.py文件
# -*- coding: utf-8 -*- BOT_NAME = 'sina2' SPIDER_MODULES = ['sina2.spiders'] NEWSPIDER_MODULE = 'sina2.spiders' USER_AGENT = 'User-Agent:Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0;' # Disable cookies (enabled by default) COOKIES_ENABLED = False # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'sina2.pipelines.Sina2Pipeline': 300, }终端测试
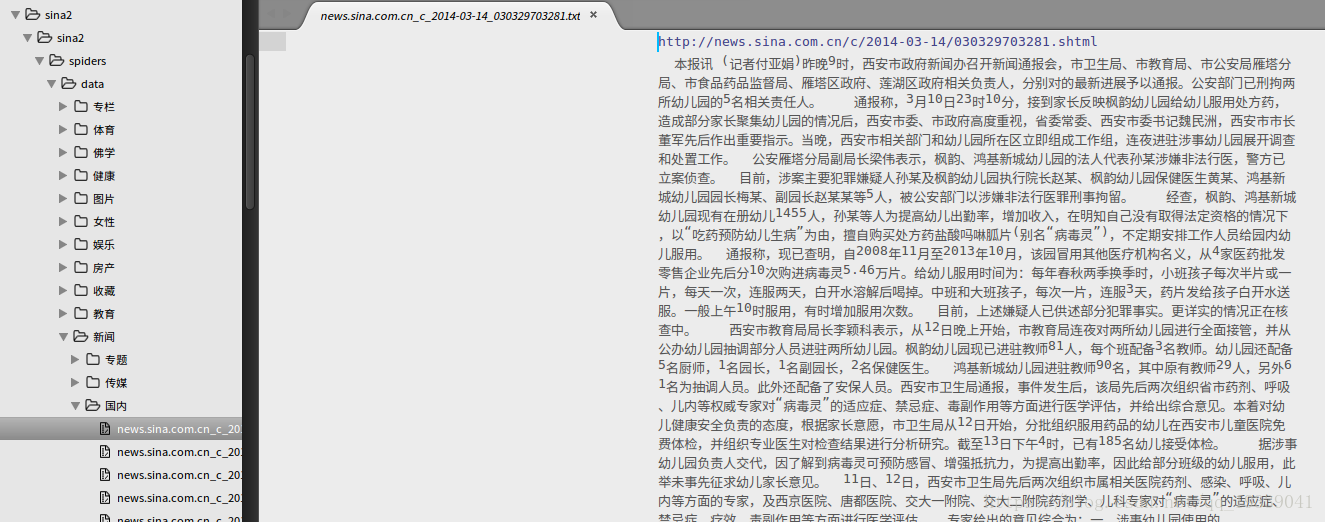
scrapy crawl newsina测试图片如下:结果里面也有空的,那是因为没有过滤内容和标题,关于过滤的看爬虫文件最下面的注释代码