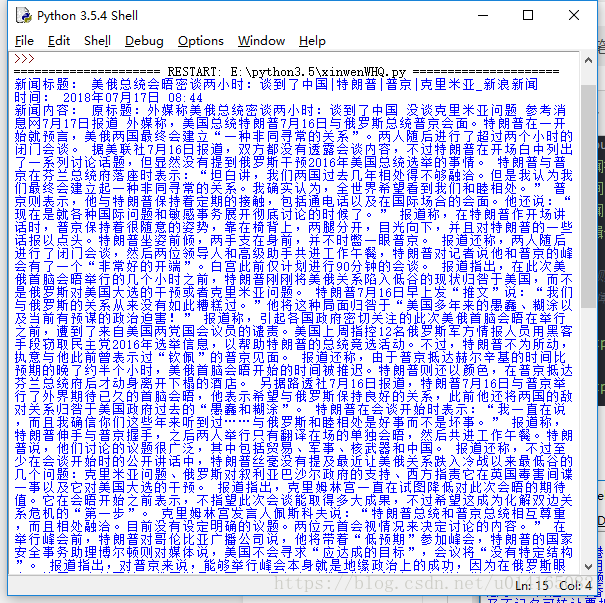
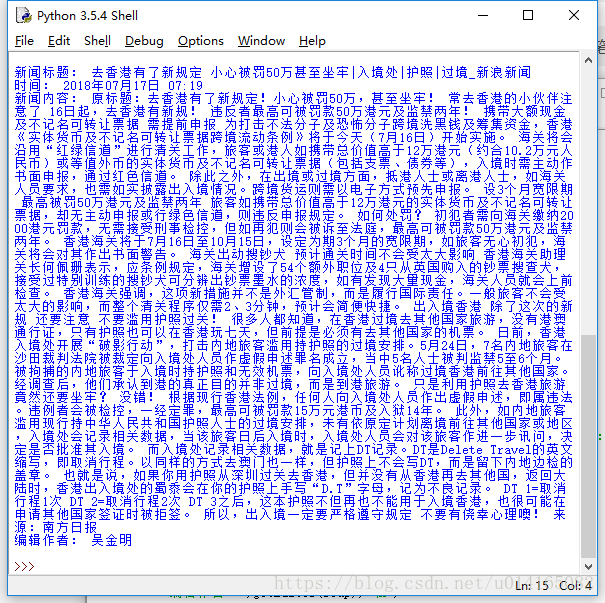
以爬取新浪新闻为例
import re
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetime
def getSoup(newsurl):
res=requests.get(newsurl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
return soupnewsurl为新浪新闻sh首页某则新闻的链接
打印出soup查看结构

title=soup.select('title')[0].text
def getArtcle(soup):
article=[]
for p in soup.select('#article p')[:-1]:
article.append(p.text.strip())
return ' '.join(article)
print(getArtcle(getSoup('http://news.sina.com.cn/w/2018-07-17/doc-ihfkffam0100205.shtml')))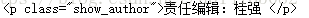
注意像这种格式的不能直接用soup.select('#show_author')[0].text.strip('责任编辑:') 而应该用下面这种语法:
editor=soup.select('p[class="show_author"]')[0].text.strip('责任编辑:')最后贴出完整的代码
import re
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetime
def getSoup(newsurl):
res=requests.get(newsurl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
return soup
def getTitle(soup):
title=soup.select('title')[0].text
return title
def getArtcle(soup):
article=[]
for p in soup.select('#article p')[:-1]:
article.append(p.text.strip())
return ' '.join(article)
def getEditor(soup):
editor=soup.select('p[class="show_author"]')[0].text.strip('责任编辑:')
return editor
def getTime(soup):
time=soup.select('span[class="date"]')[0].text
return(time)
def catch_all(newsurl):
soup=getSoup(newsurl)
print('新闻标题:',getTitle(soup),'\n'
'时间:',getTime(soup),'\n'
'新闻内容:',getArtcle(soup),'\n'
'编辑作者:',getEditor(soup),'\n')
#新浪新闻首页某则新闻的链接作为catch_all的参数输入,
#即可输出该则新闻的标题、时间、内容、作者
catch_all('http://news.sina.com.cn/w/2018-07-17/doc-ihfkffam0100205.shtml')
catch_all('http://news.sina.com.cn/c/2018-07-17/doc-ihfkffak9643422.shtml')