前两天把python基础语法看了下,简单做了点练习,今天开始做了第一个python爬虫项目,用了scrapy框架,从安装python开始记录下步骤。
一。安装python和pycharm
1.从官网:https://www.python.org/downloads/ 下载python3.6.5,不装在默认位置,我选择安装在D:\py\python3.6.5下。
2.从官网:http://www.jetbrains.com/pycharm/ 下载pycharm,选择professional版,安装在D:\ProgramFiles下,安装路径不要有空格,不然无法安装。
3.设置python环境变量:在path下添加python的安装路劲 D:\py\python3.6.5\python.exe

二。安装scrapy库
scrapy库安装可费劲了,安装过程两部一个坑,感觉跟配置spring xml一样哈哈,扯远了。下面我们就来看看具体步骤。
网上很多教程都教我们在命令行里安装,其实这样挺麻烦的,既然有工具,为什么不用工具呢!OK,我们打开刚安装好的pycharm,新建一个工程,注意新建工程时有个选项 Project Virtual Interpreter,点开,选择Existing interpreter,选择我们上面安装好的python.exe,不然pycharm就会创建新的python环境,我们前面已经安装好了,这不是多此一举嘛。

然后一次点击File-Default Settings-Project Interpreter,在Project Interpreter那里选择我们上面安装好的python.exe
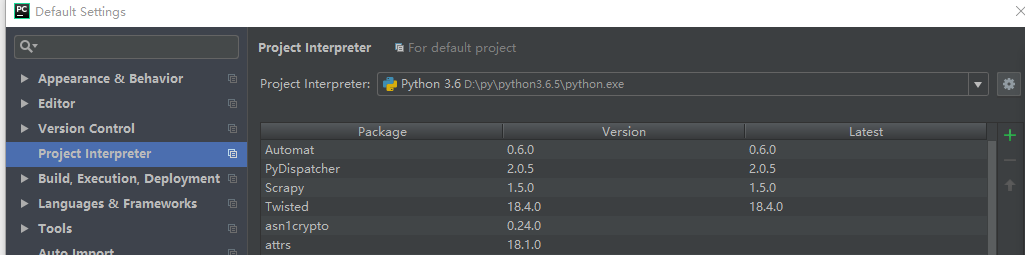
然后点击File-Settings-Project Interpreter,这里的Project Interpreter应该也更新了。点击右侧的绿色加号,搜索要安装的包,点击install package依次安装以下库:
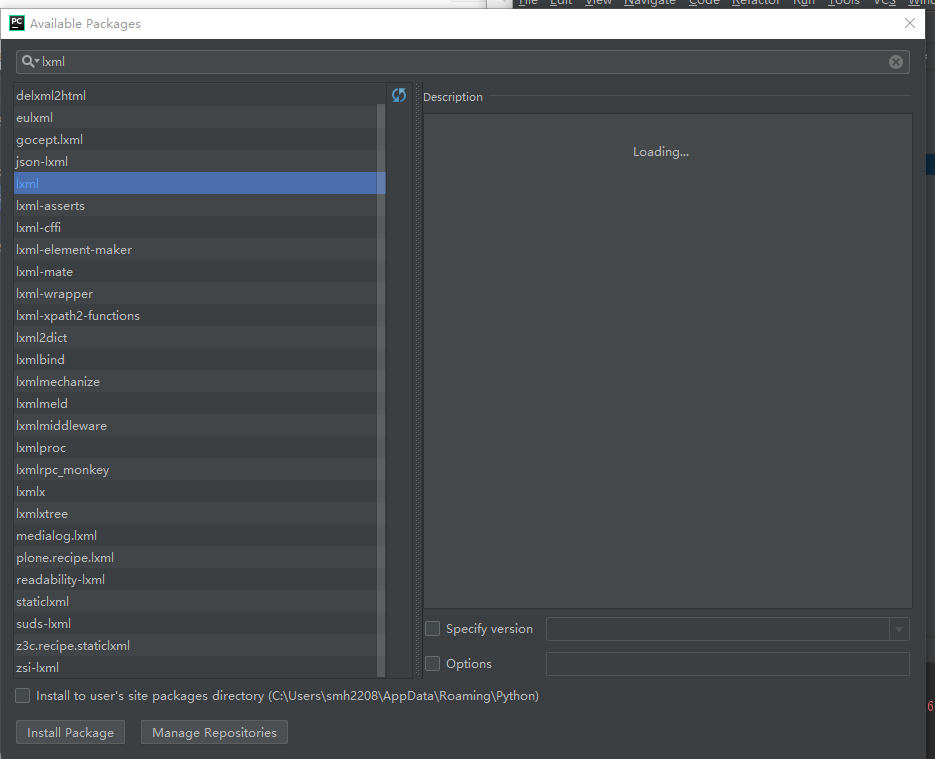
1.lxml
2.zope.interface
3.twisted:安装时可能会提示error:Microsoft Visual C++ 10.0 is required (Unable to find vcvarsall.bat),改为手动安装。
https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml 在这个网站下载对应的twisted库,我的python版本是3.6.5,所以选择
- Twisted‑18.4.0‑cp34‑cp34m‑win32.whl ,文件放在了D:\py\python3.6.5\Scripts。命令行里进入D:\py\python3.6.5\Scripts目录
- 执行命令 pip install Twisted-18.4.0-cp36-cp36m-win32.whl,片刻后安装成功。
- 4.回到pycharm,安装OpenSSL
- 5.安装scrapy,安装成功
- 三。创建scrapy项目
- 1.先按照上面的方法把scrapy添加到环境变量里,命令行里执行 scrapy startproject scrapy_exam,可以看到生成了scrapy工程,
- 用pycharm打开这个项目,编辑Items.py文件
import scrapy from scrapy import Item,Field class ScrapyExamItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class TestItem(Item): address = Field() price = Field() lease_type = Field() bed_amount = Field() suggestion = Field() comment_star = Field() comment_amount = Field()
2.在spiders目录下创建python文件spider_test.py:
import scrapy from scrapy.spiders import CrawlSpider from scrapy.selector import Selector from scrapy.http import Request from scrapy_exam.items import TestItem from scrapy import cmdline class xiaozhu(CrawlSpider): name = 'xiaozhu' start_urls = ['http://bj.xiaozhu.com/search-duanzufang-p1-0/'] def parse(self, response): item = TestItem() selector = Selector(response) commoditys = selector.xpath('//ul[@class="pic_list clearfix"]/li') for commodity in commoditys: address = commodity.xpath('div[2]/div/a/span/text()').extract()[0] price = commodity.xpath('div[2]/span[1]/i/text()').extract()[0] lease_type = commodity.xpath('div[2]/div/em/text()').extract()[0].split('/')[0].strip() bed_amount = commodity.xpath('div[2]/div/em/text()').extract()[0].split('/')[1].strip() suggestion = commodity.xpath('div[2]/div/em/text()').extract()[0].split('/')[2].strip() infos = commodity.xpath('div[2]/div/em/span/text()').extract()[0].strip() comment_star = infos.split('/')[0] if '/' in infos else '无' comment_amount = infos.split('/')[1] if '/' in infos else infos item['address'] = address item['price'] = price item['lease_type'] = lease_type item['bed_amount'] = bed_amount item['suggestion'] = suggestion item['comment_star'] = comment_star item['comment_amount'] = comment_amount yield item urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(str(i)) for i in range(1, 14)] for url in urls: yield Request(url, callback=self.parse) cmdline.execute("scrapy crawl xiaozhu".split())
3.右击spider_test.py,选择Run spider_test.py,可以看到输出:

今天先写到这里,明天再分析一下程序