目的: 根据输入的x来预测输出的y,一共是3层:输入(1个神经元)——隐层(10个神经元)——输出(1个神经元)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#使用numpy 城生成200个随机点(-0.5到0.5均匀分布的200个随机点)
x_data=np.linspace(-0.5,0.5,200)[:,np.newaxis]#200行1列的数据
noise=np.random.normal(0,0.02,x_data.shape)#生成一些干扰项,形状和x_data一样
y_data=np.square(x_data)+noise#y_data是一个还算标准的U性的函数,+noise大致是U(初始模型)
#以上是样本
#定义2个占位符placeholder
x=tf.placeholder(tf.float32,[None,1])#任意形状,行不确定,1列
y=tf.placeholder(tf.float32,[None,1])#任意形状,行不确定,1列
#构建一个简单的神经网络,实现回归的问题(属入层是1个神经元,中间10个,输出层是1个)
#隐层(中间层)
#定义神经网络的中间层(权值和偏置),输入是1个,隐层输出是10个,10个神经元10个权值,10个偏置
Weights_L1=tf.Variable(tf.random_normal([1,10]))
biases_L1=tf.Variable(tf.zeros([1,10]))
#x矩阵和权值矩阵的乘机,矩阵的乘法函数matmul
Wx_plus_b_L1=tf.matmul(x,Weights_L1)+biases_L1
#激活函数(双曲正切)
L1=tf.nn.tanh(Wx_plus_b_L1)
#输出层
#定义神经网络的输出层 1个神经元 1个权值1个偏置
Weights_L2=tf.Variable(tf.random_normal([10,1]))
biases_L2=tf.Variable(tf.zeros([1,1]))
#x矩阵和权值矩阵的乘机,矩阵的乘法函数matmul,上一层的输出L1和偏置的乘积
Wx_plus_b_L2=tf.matmul(L1,Weights_L2)+biases_L2
#激活函数(双曲正切)
Prediction=tf.nn.tanh(Wx_plus_b_L2)
#损失函数
#二次代价函数
loss = tf.reduce_mean(tf.square(y-Prediction))
#定义一个梯度下降法来进行训练的优化器,学习率是0.1
#最小化代价函数,使用梯度下降法来训练
train_step= tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#定义会话
with tf.Session() as sess:
#变量初始化
sess.run(tf.global_variables_initializer())
#迭代2000次 feed_dict相当于传值,根据传入的真实值来训练模型
for _ in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#获取预测值
Prediction_value=sess.run(Prediction,feed_dict={x:x_data})
#结果用画图的形式展现出来
plt.figure()
#把真实值和预测值同时用图的形式显示
plt.scatter(x_data,y_data)
#红色实现,宽度是5
plt.plot(x_data,Prediction_value,'r-',lw=5)
plt.show()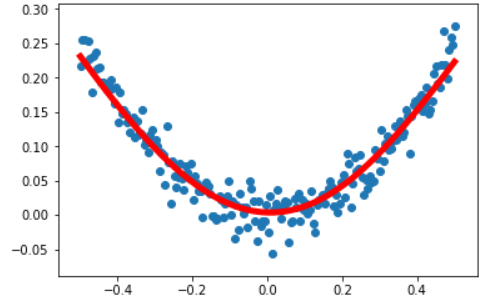
图:蓝色的是之前离散的点,红色是后期的预测的函数。
运行错误: RuntimeError: Attempted to use a closed Session.
解决办法:因为利用with tf.Session() as sess:在会话使用完毕后,会自动关闭会话,所以,之后的操作利用缩进来在会话下,不会出现错误。