笔者最近对基于Gan的神经网络Vocoder进行了一系列实验。 简单做一下总结并提出一些列疑问,一起与行业大佬探讨遇到的问题。
先来看melgan的模型结构,包括两部分: Generator(生成器) 和 Discriminator(判别器)。
Generator
输入为mel-spectrogram,输出为raw waveform. 从 mel-spectrogram到 audio的过程很显然是一个上采样的过程。
这里的上采样是由一维反卷积(transpose1d)实现的,上采样的倍数如何确定呢?
需要注意一下,上采样的倍数是由hop_size来决定的,为什么呢?
需要明白一点,mel帧数 * 帧移 = 音频长度(采样点个数,可换算为音频时长,具体怎么做不用说了吧)
因此,对于22050采样率, hopsize大小设置为256, 那么对应的mel-spectrogram需要上采样 256倍
如果是16000采样率呢? 使用帧长是50ms,帧移 12.5ms 那么hopsize就是200啦,所以上采样倍数就是200倍啦.
搞清楚了这些,那么Generator Upsampling层中的上采样倍数也就好理解了,22050的采样倍数为 8 X 8 X 2 X 2 = 256
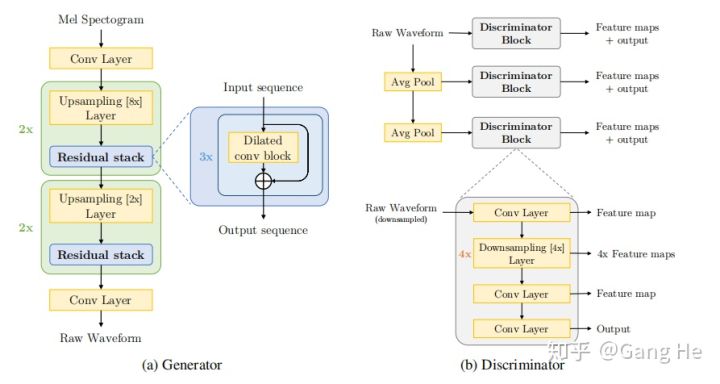
图1 melgan模型结构
另外一点需要搞清楚的是反卷积是如何做上采样的?
如果有人不明白反卷积(上采样)是如何工作的,那就看一下这篇文章《Understanding transpose-convolutions》,里面通过卷积矩阵的方式来讲解了卷积运算和反卷积运算的过程。
上采样的方法有很多种,除了反卷积之外,还有最近邻、双线性插值等,这些方法在Wave net的实现里也都用到了。具体算法实现,自行研究。
每一层Upsampling Layer之后会接一层的RedidualStack(由三层的dilatend 一维卷积构成), ResidualStack层通过三层不同dilation系数(1,3,9)的空洞卷积获得了大小为27的感受野,来扩大时域上的感知能力,能够更好的建模时域上的长距离依赖关系。
Generator网络的最后一层是一个一维卷积层 + tanh函数,输出范围为-[1,1], 满足音频的数值点的取值范围。该层的输出通道数为1,这里的通道数对应的输出的是全波段音频(full band),这里就与后续要讲的multi-band melgan模型Generator的区别.
最后一点,棋盘效应(checkerboard artifacts). 具体什么是棋盘效应,及如何减弱棋盘效应导致的音频高频镜像问题(无法完全解决),请查看这篇博文. 如果选择的卷积核与stride大小不合适,会产生严重的棋盘效应,体现在音频频谱上就是高频横纹比较多,音质上滋滋的电流声(如有不对,欢迎讨论)。
讲完了Generator, 我们再来说说Discriminator.
Discriminator
论文提出了multi-scale的discriminator, 基于的假设是每个scale的discriminator可以学习到不同频率段的音频的特征。
每个discriminator的网络结构是由前后各一层1维卷积 和 4层分组卷积构成的downsampling layer构成. discriminator输入是由ground truth的音频和gererator生成的fake音频两部分构成的。 输入维度为[B, T, 1], 输出维度也是[B,T,1], 中间变换的只是通道数的变化, 最后一层的输出和倒数第二层卷积网络的输出被分别用来计算 featuremap 和 feature_score, 这两部分被用来计算 generator的feature_matching_loss(L1_loss) 和discriminator的mse_loss
.上面我们知道了Generator输入mel-spectrogram,生成音频audio, 这个音频可以表示为G (s), s为mel-spectrogram. 判别器要判断生成器生成音频的真假,这里就涉及到Gan模型的原理啦,
Generator输入mel-spectrogram生成音频(fake), Discriminator输入真(real)音频和假(fake)音频,学习一个二分类器(可以这么理解),这里使用的是mse损失来最小化real与1的差异,fake与0的差异。
通过对抗学习,使得generator生成的音频达到判别器无法判断真假的效果(loss接近0.5)。
这就是melgan学习训练的过程。
几点总结
1 生成音频的时候(推理),只用Generator。discriminator只在训练过程中辅助学习。
2 Gan模型的训练,generator 和 discriminator是交替训练的,先固定discriminator,训练generator一个step,然后固定generator,训练discriminator一个step.
3 训练过程会比较长,单卡V100 GPU,能跑半个月,这个后续如果替换featurematching_loss为multi-resolution stft loss会缩短收敛时间。
4 训练过程中间生成的音频最开始会有很严重的棋盘效用,随着迭代次数增加,这种效用会慢慢减弱。
5 melgan音频高频部分details不明显,会有发音抖动和沙沙的底噪,此问题比较严重。
给出一个采样率为16KHZ的样例,此样例为melgan ground truth训练中生成的音频频谱。