LifeCat系列学习项目(Hadoop)
LifeCat系统-搭建Hadoop分布式平台进行数据分析
最简单的MapReduce应用程序至少包含 3 个部分:
一个 Map 函数、一个 Reduce 函数和一个 main 函数。
在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:
map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。
main 函数将作业控制和文件输入/输出结合起来。
基于Hadoop分布式计算环境,
为lifecat系统图像运算提供高性能计算环境
同时对lifecat产生的数据进行处理与分析
MapReduce提供图像运算支持
image包
MapReduce提供数据分析支持
data包
MapReduce开发测试Demo
text包
基于MapReduce对文本文件的词频进行统计
并行读取文本中的内容,然后进行MapReduce操作
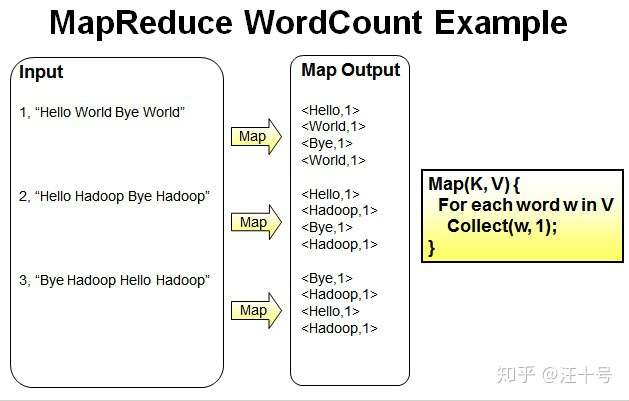
Map过程:并行读取文本,对读取的单词进行map操作,每个词都以<key,value>形式生成。
我的理解:
一个有三行文本的文件进行MapReduce操作。
读取第一行Hello World Bye World ,分割单词形成Map。
<Hello,1> <World,1> <Bye,1> <World,1>
读取第二行Hello Hadoop Bye Hadoop ,分割单词形成Map。
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>
读取第三行Bye Hadoop Hello Hadoop,分割单词形成Map。
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
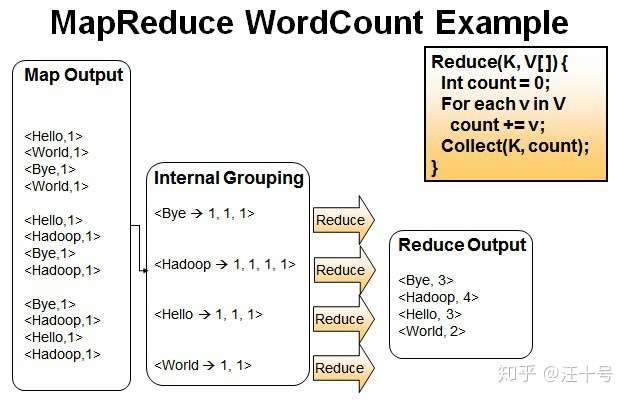
Reduce操作是对map的结果进行排序,合并,最后得出词频。
我的理解:
经过进一步处理(combiner),将形成的Map根据相同的key组合成value数组。
<Bye,1,1,1> <Hadoop,1,1,1,1> <Hello,1,1,1> <World,1,1>
循环执行Reduce(K,V[]),分别统计每个单词出现的次数。
<Bye,3> <Hadoop,4> <Hello,3> <World,2>
配置Apache Hadoop开发环境
Linux(ubuntu16.04)环境下配置Hadoop
分布式集群主机
使用1台linux(ubuntu)系统作为集群中心,负责任务的发布
Linux(centos7.4)环境下配置Hadoop
分布式集群环境
使用2台linux(centos)系统作为分布式环境,进行分布式计算
主机配置HDFS1
HDFS2
Windows10环境下配置Hadoop
开发环境
在windows10环境中通过伪分布式环境进行项目的开发
@项目源码
GitHub:kevinten10/Hadoop-lifecat