文章目录
环境:只有一台vmware虚拟机,ip为172.16.193.200.
一、手工部署
1、关闭防火墙、SELinux
systemctl stop firewalld
sed -i '/SELINUX/s/enforcing/disabled/g' /etc/selinux/config
2、设置主机名
hostnamectl set-hostname huatec01
3、安装jdk1.8
https://blog.csdn.net/weixin_44571270/article/details/102939666
4、下载hadoop
wget http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.8.5/hadoop-2.8.5.tar.gz
mv hadoop-2.8.5.tar.gz /usr/local
cd /usr/local
tar xvf hadoop-2.8.5.tar.gz
mv hadoop-2.8.5 hadoop
5、修改hadoop配置文件
cd /usr/local/hadoop/etc/hadoop/
- hadoop.env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
(1)hadoop.env.sh
该文件为Hadoop的运行环境配置文件,Hadoop的运行需要依赖JDK,我们将其中的export JAVA_HOME的值修改为我们安装的JDK路径,如下所示:
export JAVA_HOME=/usr/local/jdk1.8.0_141
(2)core-site.xml
该文件为Hadoop的核心配置文件,配置后的文件内容如下所示:
<configuration>
<property>
<name>fs.defaultFS </name>
<value>hdfs://huatec01:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/huatec/hadoop-2.8.5/tmp</value>
</property>
</configuration>
在上面的代码中,我们主要配置了两个属性,第一个属性用于指定HDFS的NameNode的通信地址,这里我们将其指定为huatec01;第二个属性用于指定Hadoop运行时产生的文件存放目录,这个目录我们无需去创建,因为在格式化Hadoop的时候会自动创建。
(3)hdfs-site.xml
该文件为HDFS核心配置文件,配置后的文件内容如下所示:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Hadoop集群的默认的副本数量是3,但是现在我们只是在单节点上进行伪分布式安装,无需保存3个副本,我们将该属性的值修改为1即可。三个节点是完全分布式。
(4)mapred-site.xml
这个文件是不存在的,但是有一个模版文件mapred-site.xml.template,我们将模版文件改名为mapred-site.xml,然后进行编辑。该文件为MapReduce核心配置文件,配置后的文件内容如下所示:
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
之所以配置上面的属性,是因为在Hadoop2.0之后,mapreduce是运行在Yarn架构上的,我们需要进行特别声明。
(5)yarn-site.xml
该文件为Yarn框架配置文件,我们主要指定我们的ResourceManager的节点名称及NodeManager属性,配置后的文件内容如下所示:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>huatec01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
在上面的代码中,我们配置了两个属性。第一个属性用于指定ResourceManager的地址,因为我们是单节点部署,我们指定为huatec01即可;第二个属性用于指定reducer获取数据的方式。
6、格式化文件系统
初次启动需要先执行hdfs namenode -format格式化文件系统,然后再启动hdfs和yarn,后续启动直接启动hdfs和yarn即可。
/usr/local/hadoop/bin/hdfs namenode -format
7、启动hdfs和yarn
cd /usr/local/hadoop/sbin/
sh start-dfs.sh
sh start-yarn.sh
#关闭hadoop
sh stop-dfs.sh
sh stop-yarn.sh
8、查看hadoop进程
jps
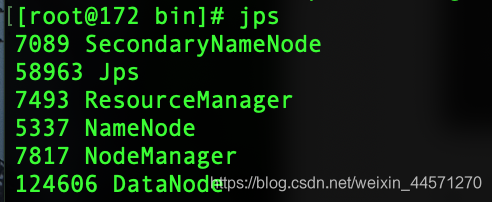 访问一下172.16.193.200:50070
访问一下172.16.193.200:50070
 访问172.16.193.200:8088,进入MapReduce管理界面:
访问172.16.193.200:8088,进入MapReduce管理界面:
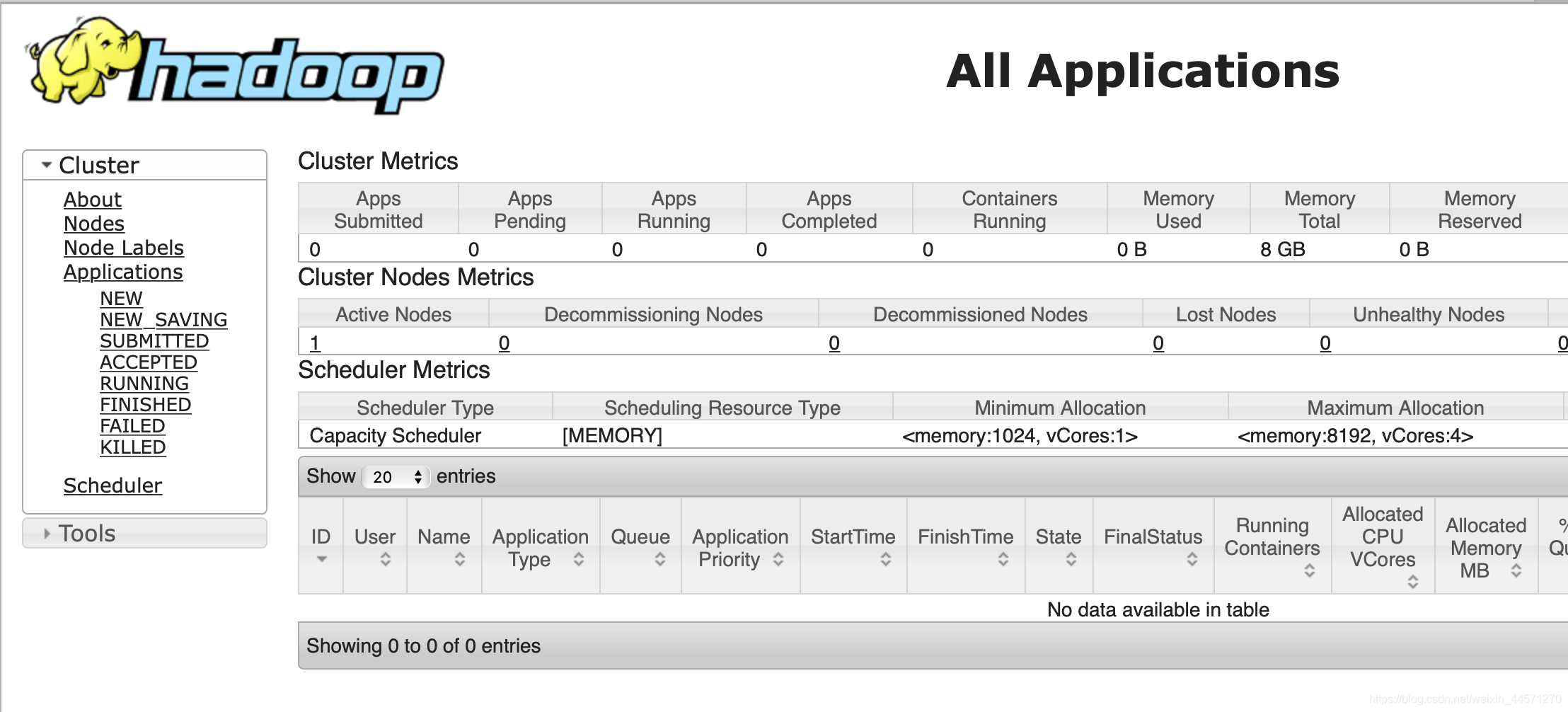 部署成功!
部署成功!
二、自动化伪分布式部署hadoop
#!/bin/bash
#authored by WuJinCheng
#This shell script is written in 2020.3.17
JDK=jdk1.8.tar.gz
HADOOP_HOME=/usr/local/hadoop
#------初始化安装环境----
installWget(){
echo -e '\033[31m ---------------初始化安装环境...------------ \033[0m'
sed -i '/SELINUX/s/enforcing/disabled/g' /etc/selinux/config
systemctl stop firewalld
wget -V
if [ $? -ne 0 ];then
echo -e '\033[31m 开始下载wget工具... \033[0m'
yum install wget -y
fi
}
#------JDK install----
installJDK(){
ls /usr/local/|grep 'jdk*'
if [ $? -ne 0 ];then
echo -e '\033[31m ---------------开始下载JDK安装包...------------ \033[0m'
wget http://www.wujincheng.xyz/$JDK
if [ $? -ne 0 ]
then
exit 1
fi
mv $JDK /usr/local/
cd /usr/local/
tar xvf $JDK
mv jdk1.8.0_141/ jdk1.8
ls /usr/local/|grep 'jdk1.8'
if [ $? -ne 0 ];then
echo -e '\033[31m jdk安装失败! \033[0m'
fi
echo -e '\033[31m jdk安装成功! \033[0m'
fi
}
JDKPATH(){
echo -e '\033[31m ---------------开始配置环境变量...------------ \033[0m'
grep -q "export JAVA_HOME=" /etc/profile
if [ $? -ne 0 ];then
echo 'export JAVA_HOME=/usr/local/jdk1.8'>>/etc/profile
echo 'export CLASSPATH=$CLASSPATH:$JAVAHOME/lib:$JAVAHOME/jre/lib'>>/etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin'>>/etc/profile
source /etc/profile
fi
}
#------hadoop install----
installHadoop(){
hostnamectl set-hostname huatec01
ls /usr/local/|grep "hadoop*"
if [ $? -ne 0 ];then
echo -e '\033[31m ---------------开始下载hadoop安装包...------------ \033[0m'
wget http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.8.5/hadoop-2.8.5.tar.gz
if [ $? -ne 0 ]
then
exit 2
fi
mv hadoop-2.8.5.tar.gz /usr/local
cd /usr/local
tar xvf hadoop-2.8.5.tar.gz
mv hadoop-2.8.5 hadoop
fi
}
#------hadoop conf----
hadoopenv(){
sed -i '/export JAVA_HOME=/s#${JAVA_HOME}#/usr/local/jdk1.8#g' /usr/local/hadoop/etc/hadoop/hadoop-env.sh
}
coresite(){
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS </name>
<value>hdfs://huatec01:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/huatec/hadoop-2.8.5/tmp</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/core-site.xml
}
hdfssite(){
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/hdfs-site.xml
}
mapredsite(){
mv $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
echo '<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/mapred-site.xml
}
yarnsite(){
echo '<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>huatec01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>'>$HADOOP_HOME/etc/hadoop/yarn-site.xml
}
#------hdfs 格式化----
hdfsFormat(){
echo -e '\033[31m -----------------开始hdfs格式化...------------ \033[0m'
$HADOOP_HOME/bin/hdfs namenode -format
if [ $? -ne 0 ];then
echo -e '\033[31m Hadoop-hdfs格式化失败! \033[0m'
exit 1
fi
echo -e '\033[31m Hadoop-hdfs格式化成功! \033[0m'
}
install(){
installWget
installJDK
JDKPATH
installHadoop
hadoopenv
coresite
hdfssite
mapredsite
yarnsite
hdfsFormat
}
case $1 in
install)
install
echo -e '\033[31m Hadoop自动化部署完成! \033[0m'
;;
JDK)
installWget
installJDK
JDKPATH
;;
Hadoop)
installWget
installHadoop
echo -e '\033[31m Hadoop安装完成! \033[0m'
;;
confHadoop)
hadoopenv
coresite
hdfssite
mapredsite
yarnsite
echo -e '\033[31m Hadoop配置完成! \033[0m'
;;
format)
hdfsFormat
;;
*)
echo "Usage:$0 {install|JDK|Hadoop|confHadoop|format}";;
esac
三、报错解决
1、在第七步启动hadoop时可能会出现无法登录!拒绝登录
 出现这句话。
出现这句话。
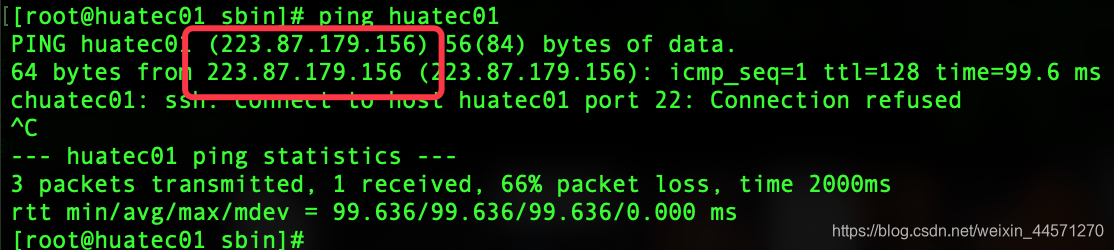 ping一下我们这个主机!结果发现它把huatec01当域名解析了。所以
ping一下我们这个主机!结果发现它把huatec01当域名解析了。所以
vim /etc/resolv.conf
 这样就好了!
这样就好了!
2、datanode启动了,但hadoop界面无datanode
考虑到时多次执行第六步格式化造成的clusterid不一致!
cd /tmp/hadoop-root/dfs/
name下current下的VERSION中的clusterid
和
data下的current下的VERSION中的clusterid不一致
需修改成一致的,重启hadoop服务!
