随着云时代的来临,大数据也吸引越来越多的关注,企业在日常运营中生成、积累的用户网络行为数据。这些数据是如此庞大,计量单位通常达到了PB、EB甚至是ZB。Hadoop作为一个开源的分布式文件系统和并行计算编程模型得到了广泛的部署和应用。本文将介绍Hadoop完全分布式集群的具体搭建过程与验证。
关键字 Hadoop,MapReduce,Yarn,HDFS
With the advent of the cloud era, big data also attracted more and more attention, enterprises in the daily operation of the generation, accumulation of user network behavior data. The data is so large that units of measurement usually reach Pb, Eb and even zb. Hadoop has been widely deployed and applied as an open source Distributed file system and parallel computing programming model.
This article will introduce the specific construction process and verification of Hadoop fully distributed cluster.
Keyword Hadoop,mapreduce,yarn,hdfs
随着微博等社会化媒体及电子商务的推广普及,人们越来越多地在网络上分享信息、发表见解,这些数据是政府和企业管理者分析舆情,设计管理策略的重要信息源。微博消息因具备时间、地理、点赞、评论和转发数等关键信息,消息内容又隐含文本主题、情感倾向等信息,因此极具分析挖掘价值。
对于海量的微博数据,使用目前主流软件工具很难在合理时间内获取、管理、处理、并整理,而hadoop这个框架主要解决海量数据的存储和海量数据的分析计算问题,具有高可靠性、高扩展性、高效性、高容错性等优点。

本文基于hadoop搭建了一个分布式存储平台,并进行验证。
第二章 研究内容
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统和MapReduce为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。HDFS的高容错性、高伸缩性等优点允许用户将Hadoop部署在低廉的硬件上,形成分布式系统,MapReduce分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。所以用户可以利用Hadoop轻松地组织计算机资源,从而搭建自己的分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
Hadoop已经发展成为包含多个子项目的集合。核心内容是MapReduce和Hadoop分布式文件系统(DHFS)。它也包含了Common、Avro、Chukwa、Hive、Hbase等子项目,他们在核心层的基础上提供了高层服务,为Hadoop的应用推广起到了重要
Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hbase
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
MapReduce
实现了MapReduce编程框架,用于大规模数据集的并行运算。能够使编程人员在不理解分布式并行编程概念的情况下也能方便将自己的程序运行在分布式系统上。
HDFS
分布式文件系统,其设计目标包括:检测和快速恢复硬件故障;数据流的访问;简化一致性模型等。
ZooKeeper
Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
本文基于Hadoop开源框架,搭建了一个分布式存储平台,包括HDFS分布式文件系统、MapReduce、以及yarn调度框架,并使用MapReduce运行wordcount程序,对短文单词进行统计,验证系统的可行性。
3.1 HDFS 产生背景
随着数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS 只是分布式文件管理系统中的一种。
3.2 HDFS 概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
3.3 HDFS 优缺点
3.3.1 优点
1) 高容错性
(1) 数据自动保存多个副本。它通过增加副本的形式,提高容错性。
(2) 某一个副本丢失以后,它可以自动恢复。
2) 适合大数据处理
(1) 数据规模:能够处理数据规模达到 GB、TB、甚至 PB 级别的数据。
(2) 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3) 流式数据访问
(1) 一次写入,多次读取,不能修改,只能追加。
(2)它能保证数据的一致性。
4)可构建在廉价机器上,通过多副本机制,提高可靠性
3.3.2 缺点
1) 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2) 无法高效的对大量小文件进行存储
(1)存储大量小文件的话,它会占用 NameNode 大量的内存来存储文件、目录和块信息。这样是不可取的,因为 NameNode 的内存总是有限的。
(2)小文件存储的寻址时间会超过读取时间,它违反了 HDFS 的设计目标。
3)并发写入、文件随机修改
(1)一个文件只能有一个写,不允许多个线程同时写。
(2)仅支持数据 append(追加),不支持文件的随机修改。
3.4 HDFS 架构
这种架构主要由四个部分组成,分别为 HDFS Client、NameNode、DataNode 和 Secondary NameNode。下面我们分别介绍这四个组成部分。
1)Client:就是客户端。
(1)文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block,然后进
(2)与 NameNode 交互,获取文件的位置信息。
(3)与 DataNode 交互,读取或者写入数据。
(4) Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
(5) Client 可以通过一些命令来访问 HDFS。
2) NameNode:就是 master,它是一个主管、管理者。
(1) 管理 HDFS 的名称空间。
(2) 管理数据块(Block)映射信息
(3) 配置副本策略
(4) 处理客户端读写请求。
3) DataNode:就是 Slave。NameNode 下达命令,DataNode 执行实际的操作。
(1) 存储实际的数据块。
(2) 执行数据块的读/写操作。
Mapreduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析应用”的核心框架。
Mapreduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 hadoop 集群上。
4.2 MapReduce 优缺点
4.2.1 优点
1)MapReduce 易于编程。它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。
2)良好的扩展性。当你的计算资源不能得到满足的时候,你可以通过简单的增加机器
来扩展它的计算能力。
3)高容错性。MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
4)适合 PB 级以上海量数据的离线处理。这里加红字体离线处理,说明它适合离线处理而不适合在线处理。比如像毫秒级别的返回一个结果,MapReduce 很难做到。
4.2.2 缺点
MapReduce 不擅长做实时计算、流式计算、DAG(有向图)计算。
1)实时计算。MapReduce 无法像 Mysql 一样,在毫秒或者秒级内返回结果。
2)流式计算。流式计算的输入数据是动态的,而 MapReduce 的输入数据集是静态的,不能动态变化。这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。
3)DAG(有向图)计算。多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做,而是使用后,每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。
4.3 MapReduce 核心思想
1) 分布式的运算程序往往需要分成至少 2 个阶段。
2) 第一个阶段的 maptask 并发实例,完全并行运行,互不相干。
3) 第二个阶段的 reduce task 并发实例互不相干,但是他们的数据依赖于上一个阶段的所有
maptask 并发实例的输出。
4)MapReduce 编程模型只能包含一个 map 阶段和一个 reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 mapreduce 程序,串行运行。
一个完整的 mapreduce 程序在分布式运行时有三类实例进程:
1) MrAppMaster:负责整个程序的过程调度及状态协调。
2) MapTask:负责 map 阶段的整个数据处理流程。
3) ReduceTask:负责 reduce 阶段的整个数据处理流程。
5.1 Hadoop集群资源规划设计
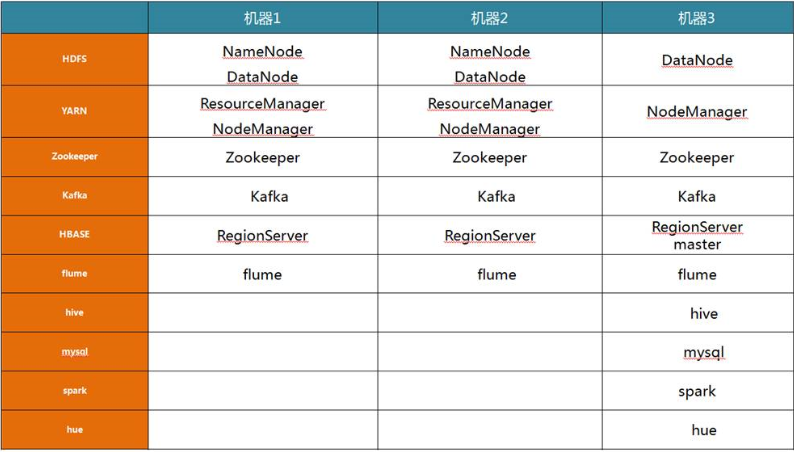
5.1Hadoop集群资源规划设计
集群中包括3个节点:1个master,2个Salve,节点之间局域网连接,可以相互ping通,节点IP地址分布如下:
| 机器名称 |
IP地址 |
系统 |
| Jaleel1 |
192.168.1.11 |
CentOS7-x86_64 |
| Jaleel2 |
192.168.1.12 |
CentOS7-x86_64 |
| Jaleel3 |
192.168.1.13 |
CentOS7-x86_64 |
5.2 linux环境准备与设置
5.2.1 安装JDK:
- master上安装JDK:
- 其它三台主机也要部署JDK
5.2.2 安装Hadoop
- 配置Hadoop环境变量:
- 解压Hadoop文件并建立相应的目录:
- 设定Hadoop集群中Slaves角色主机:
5.3 Hadoop分布式集群配置-HDFS
安装hdfs需要修改4个配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml和slaves
5.3.1 hadoop-env.sh
#vi hadoop-env.sh
#java环境变量修改为export JAVA_HOME=/opt/module/jdk1.8.0_202
5.3.3 hdfs-site.xml
5.4 Hadoop分布式集群配置-YARN
安装yarn需要修改4个配置文件:yarn-env.sh、mapred-env.sh、yarn-site.xml和mapred-site.xml
5.5 分发到其他各个机器节点
hadoop相关配置在第一个节点配置好之后,可以通过脚本命令分发给另外两个节点即可,具体操作如下所示。
5.6 HDFS启动集群运行测试
hdfs相关配置好之后,可以启动hdfs集群。
三个DataNode
Yarn启动成功
MapReduce、NameNode、DataNode启动成功
5.8 YARN集群运行MapReduce程序测试
前面hdfs和yarn都启动起来之后,可以通过运行WordCount程序检测一下集群是否能run起来。
在文件输入以下内容:
文件上传成功
执行成功
MapReduce经过处理,把短文的单词进行了统计,但耗时稍长。
结合上面所得到的数据和分析情况,由于当前Hadoop分析平台的性能的硬件性能并不是很好,上述文档处理后大小为126m,数据量分析就要使用到差不到300秒时间。但随着数据量的增加,查询时间并不会随着数据量的增大而明显的增大。所以Hadoop更加适合大数据的处理,但是在计算处理Spark略胜一筹。
另外,云计算在短短的几年内获得了迅猛的发展,得到了几乎所有的IT行业巨头的青睐。云计算分布式的特点,方便的用户接入使用,高度的可靠性、可扩展性都为其发展带来了巨大的优势。以Google、IBM、Microsoft、Amason等云计算平台为代表的一系列应用迅猛地发展起来。
总之,大数据的研究和应用还有一片广阔的前景,今后需要研究地问题还很多,我们应该不断地学习,利用自己所学的知识,为该领域的相关研究做出自己应有地贡献。
[1] JIANG S,HONG W X.A vertical news recommendation system:CCNS—an example from Chinese campus news reading system[C].ICCSE 2014: Proceedings of the 2014 9th International Conference on Computer Science & Education.Piscataway,NJ: IEEE,2014: 1105-1114.
[2] 杨武,唐瑞,卢玲.基于内容的推荐与协同过滤融合的新闻推荐方法[J].计算机应用, 2016, 36(2):414-418.
[3] 刘金亮.基于主题模型的个性化新闻推荐系统的研究与实现[D].北京: 北京邮电大学,2013.
[4] 彭菲菲,钱旭.基于用户关注度的个性化新闻推荐系统[J].计算机应用研究,2012,29(3) : 1005-1007.
[5] 文鹏,蔡瑞,吴黎兵.一种基于潜在类别模型的新闻推荐方法[J].情报杂志,2014,33(1):161-166.
[6] 项亮.推荐系统实践[M].北京: 人民邮电出版社,2012.
[7] 曹一鸣. 基于协同过滤的个性化新闻推荐系统的研究与实现[D]. 北京:北京邮电大学, 2013
[8]Tom Wbite.Hadoop权威指南,清华大学出版社
[9]陆嘉恒.Hadoop实战(第2版).机械工业出版社
[10]Garry Turkington.Hadoop基础教程.人民邮电出版社