大数据分布式计算组件:Hadoop丨Storm丨Spark
“工欲善其事,必先利其器”,具有特定功能的可复用组件正是计算机领域中的利器。在大数据的浪潮下,许多用于处理大数据的组件应运而生,分别应用在“数据传输”“数据存储”“数据计算”以及“数据展示”的环节中。
本文将介绍“数据计算”环节中常用的三种分布式计算组件——Hadoop、Storm以及Spark。
当前的高性能PC机、中型机等机器在处理海量数据时,其计算能力、内存容量等指标都远远无法达到要求。在大数据时代,工程师采用廉价的PC机组成分布式集群,以集群协作的方式完成海量数据的处理,从而解决单台机器在计算与存储上的瓶颈。Hadoop、Storm以及Spark是常用的分布式计算组件,其中Hadoop是对非实时数据做批量处理的组件;Storm和Spark是针对实时数据做流式处理的组件。
1.Hadoop
Hadoop是受Google Lab开发的MapReduce和Google File System(GFS) 的启发而实现的开源大数据处理平台。Hadoop的核心由HDFS分布式文件系统和MapReduce编程框架组成。前者已经在前述章节中有过介绍,它为海量数据提供了存储;后者则用于对海量数据的计算,是本节要着重介绍的内容。
MapReduce是一种通用的编程模型,下面对它做简单介绍,它的工作流程如图。
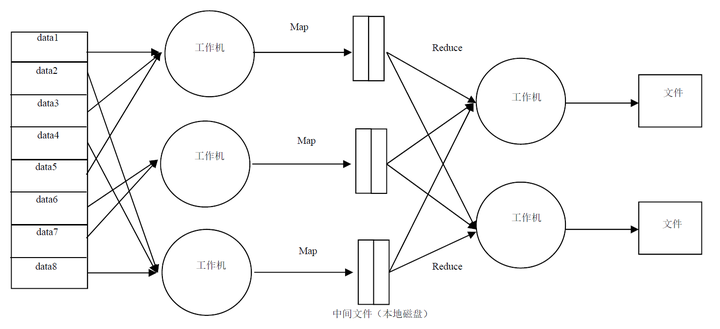
我们以字母统计为例说明上述流程。假设有文件内容为“Iamapanda, andIamfromChina”。首先,把大文件分割成data数据块;其次,把data发送到各个工作机;此时,工作机解析内容,形成Key-Value键值对数据。本例中形成的数据为, , , , , , , , ,这些数据保存在中间文件中,Map阶段结束。之后,根据Key值路由,把相同Key值的键值对路由到同一台工作机,并在工作机上实现单词计数。本例中计数结果, , , , , , 。最后,各Reduce工作机把结果写入文件,Reduce阶段结束。
Hadoop平台上通过JobTracker和TaskTracker协调调度,实现MapReduce的运行,其工作机制可以用下图说明。
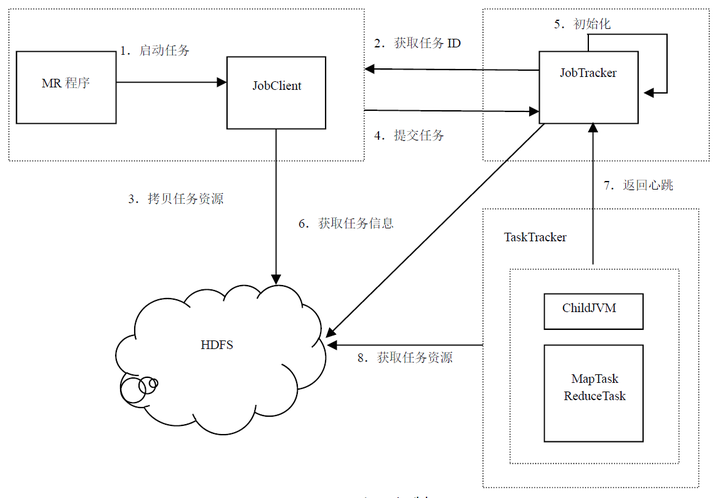
上图可知,JobTracker负责任务调度,而TaskTracker负责任务的执行;同时,需要处理的数据存储在HDFS中,TaskTracker根据MR程序读取并处理数据。
以上对Hadoop的介绍依据的是Hadoop1.0(第一代Hadoop)的整体框架,当前Hadoop2.0(第二代Hadoop)引入了YARN作为其资源调度的方式,架构与1.0略有不同,但依然采用MR的计算模型。
2.Storm
Storm是用Clojure语言编写的分布式实时流处理系统。Hadoop平台执行批处理操作,数据处理的延迟较高;而进入Storm的数据则像水流一样源源不断流入,并对其做实时处理。Storm集群架构如下。
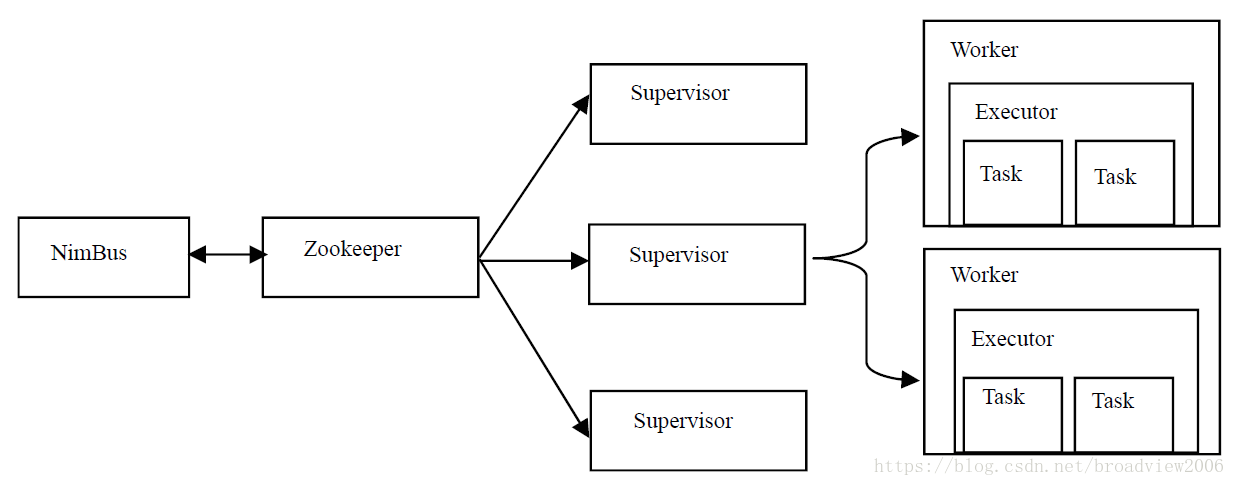
Nimbus与Hadoop中JobTracker的功能类似,负责资源的管理和任务的调度。从Zookeeper中读取各节点信息,协调整个集群的运行。
Supervisor与Hadoop中TaskTracker的功能类似,负责接受任务,负责自身Worker进程的创建和任务的执行。
Worker是机器上具体的运行进程,Executor是该进程中的线程。一个Executor可以执行多个Task。在该集群架构的方式下,Storm实现了如下的计算模型。
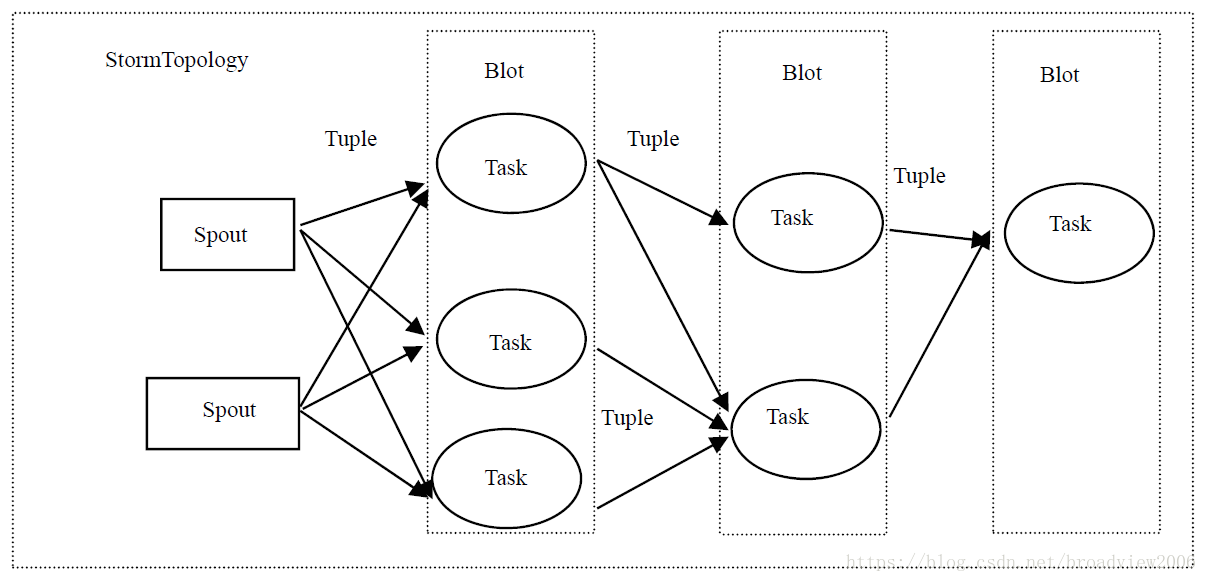
Spout是数据的入口,负责接受推送的数据,或者主动拉取数据。同时,把接收的数据转换为Tuple对象发送到Blot中处理。数据从Spout进入,封装成Tuple,传输到第一层的某个Blot中,该Blot处理完成后,路由到第二层的某个Blot中,依此类推直到最后一组Blot处理结束。
Blot是Storm实际的数据处理单元,接受Spout或者上一级Blot传输的数据并处理。根据并发度的设置,Blot会分散到集群的一台或多台集群上并发执行,从而有效利用集群的计算能力,提高数据处理的实时性。这和在单台机器上多线程处理有相似之处。
Tuple是一个或多个包含键值对的列表。数据会封装成Tuple对象在Spout与Blot之间传输。Storm支持7种路由策略,分别为
- Shuffle分组,Tuple随机分散传输到后续的多个Task中;
- Fields分组,根据指定field来做哈希,相同的哈希值传输到同一个Task;
- All分组,广播式地发送,把所有的Tuple发送到所有的Task中;
- Global分组,把所有的Tuple发送到一个Task中;
- None分组,也就是不关心如何路由,目前等同于shuffle分组;
- Direct分组,是一种特殊的分组,需要手动指定Task;
- Localorshuffle分组,如果目标Blot中的Task和产生数据的Task在同一个Worker中,就执行线程间的内部通信,否则等同于shuffle分组。
3.Spark
Spark是用Scala语言编写的分布式数据处理平台。Spark的核心数据处理引擎依然是运行MapReduce计算框架,并且围绕该引擎衍生出多种数据处理组件,共同打造了轻量级的数据处理生态圈。

Spark数据引擎是各组件库的核心。Spark与Hadoop的计算框架都是基于MapReduce模型的,Spark自身不包含类似HDFS的文件系统模块,而是借助外部的平台如HDFS、HBase等存取数据。Spark在执行MapReduce的过程中做了重要的优化:第一,计算的中间数据不写磁盘,全部在内存中执行(可以设置对磁盘的依赖);第二,支持任务的迭代。Hadoop任务必须依照Map→Reduce成对执行,然而Spark可以依据任务的DAG图,按照Map→Map→Reduce等任意方式执行。这两点改进极大缩短了任务时延。
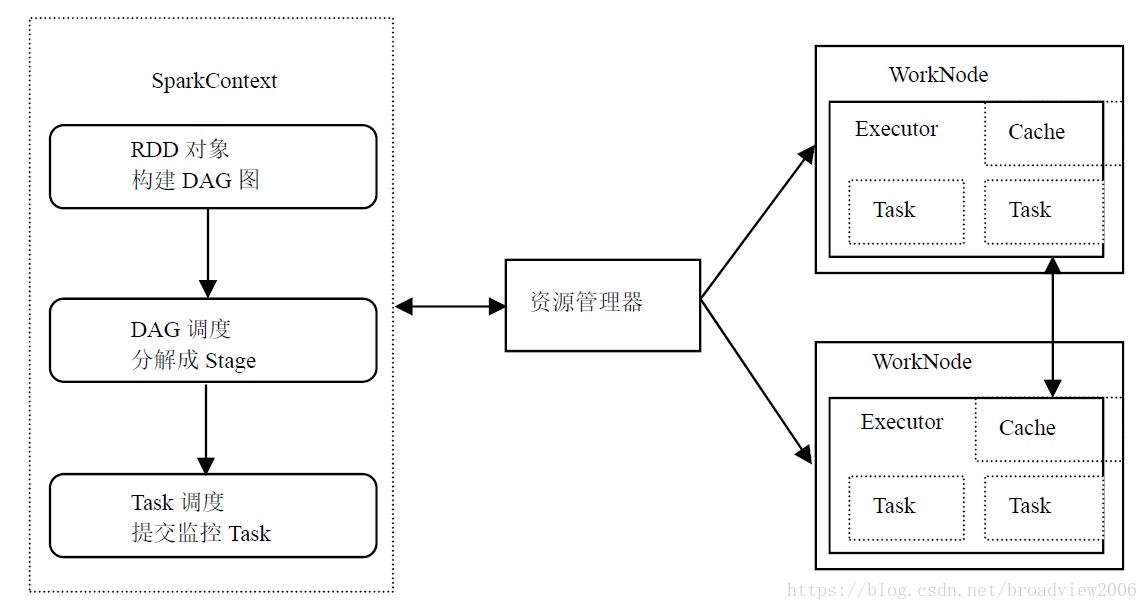
下图为Spark的工作流程。RDD是Spark的重要概念,代表了数据集和操作的结合。数据集来自内部或者外部,操作包含map,group,reduce等。我们下面给出一个RDD的示例。
-
val lines = sc.textFile("data.txt") -
val lineLengths = lines.map(s =>s.length) -
val totalLength = lineLengths.reduce((a, b) =>a + b)
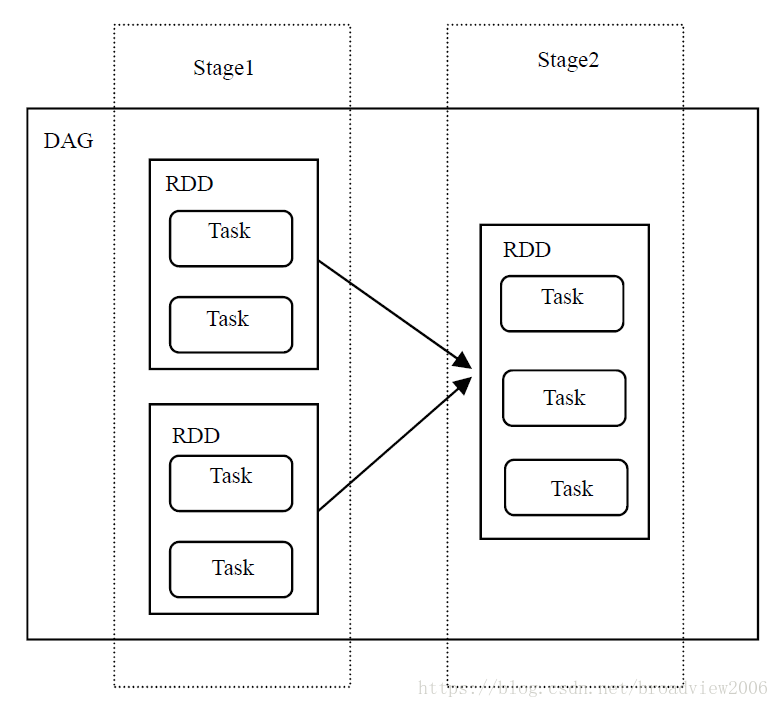
lineLengths就代表数据集lines和操作map组成的RDD。一个RDD又可以分多个Task执行,按照其执行的顺序组成DAG图。后续RDD的执行依赖先前RDD的执行,因此这种依赖关系又可以划分为Stage,下图直观说明了DAG、Stage、RDD以及Task的概念。
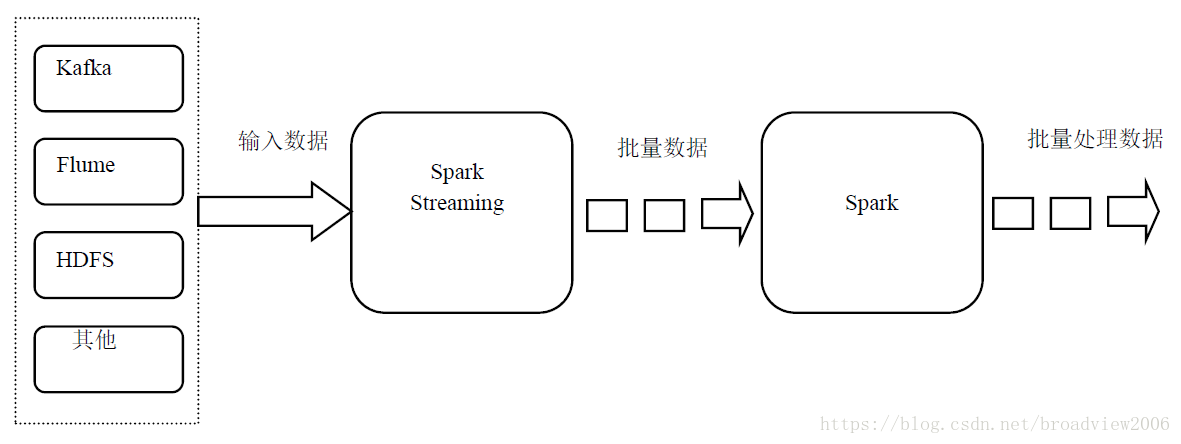
Spark Streaming是基于Spark核心处理引擎实现的高吞吐与低延迟的分布式流处理系统。与Storm相比,两者在功能上是一致的,都实现了数据流的实时处理;Storm的延迟在亚秒级别,而Spark Streaming是在秒级别,主要因为前者对数据的处理就像水流一样,来一条数据则处理一条,而后者是不断进行小批量处理,只有在某些苛刻的场景下才能对比出这两种方式的优劣。Spark Streaming数据处理流程如下。
SparkSQL是分布式SQL查询引擎,与Hive类似,并对Hive提供支持。Hive基于Hadoop的MapReduce实现查询,而SparkSQL则是基于Spark引擎,因此查询速度更快。但是,SparkSQL需要更多的内存,在实际应用中其功能的丰富性和稳定性却不如Hive。不过随着系统的不断演化,SparkSQL将逐渐取代Hive,成为分布式SQL查询引擎的佼佼者。
MLlib是Spark封装的一些常用的机器学习算法相关库。基于RDD的方式实现了二元分类、回归、系统过滤等一些算法。GraphX主要对并行图计算提供支持,开发并实现了一些和图像相关新的Spark API。
本文选自《Python绝技:运用Python成为顶级数据工程师》,作者黄文青,电子工业出版社2018年6月出版。