目录
什么是Hadoop
Hadoop 是一个适合大数据的分布式存储和计算平台。
Hadoop的广义和狭义区分:
狭义的Hadoop:指的是一个框架,Hadoop是由三部分组成:HDFS:分布式文件系统--》存储;MapReduce:分布式离线计算框架--》计算;Yarn:资源调度框架。
广义的Hadoop:广义Hadoop是不仅仅包含Hadoop框架,除了Hadoop框架之外还有一些辅助框架。Flume:日志数据采集,Sqoop:关系型数据库数据的采集;
Hive:深度依赖Hadoop框架完成计算(sql),Hbase:大数据领域的数据库(mysql)Sqoop:数据的导出广义Hadoop指的是一个生态圈。
Hadoop的特点
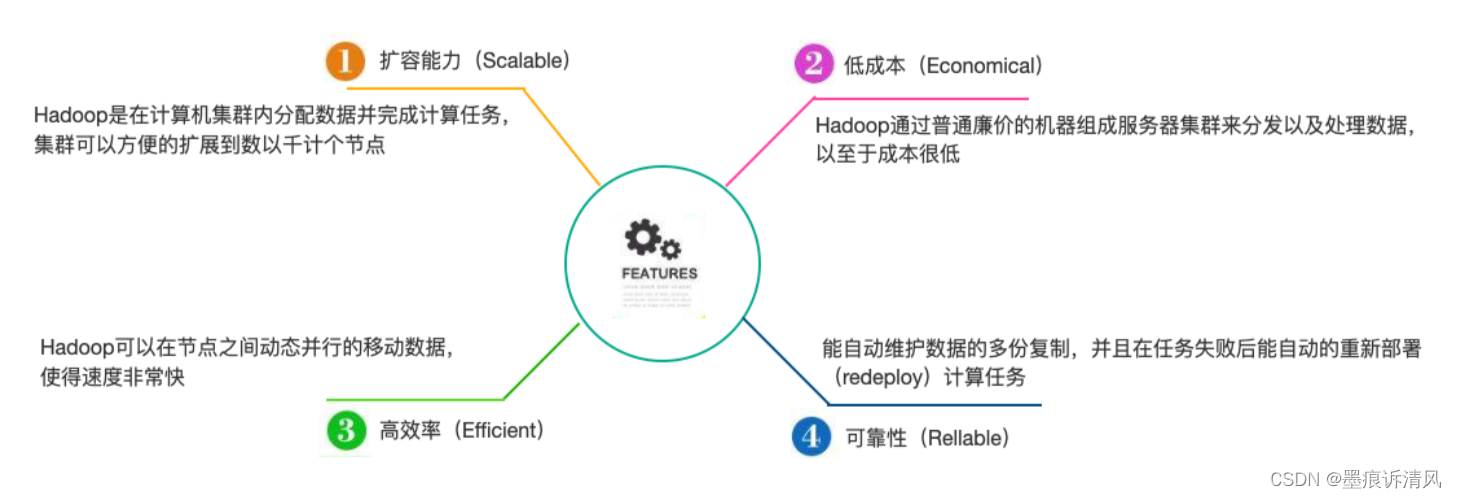
Hadoop优点
1.Hadoop具有存储和处理数据能力的高可靠性。
2.Hadoop通过可用的计算机集群分配数据,完成存储和计算任务,这些集群可以方便地扩展到数以千计的节点中,具有高扩展性。
3.Hadoop能够在节点之间进行动态地移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性。
4.Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配,具有高容错性。
Hadoop的缺点
1.Hadoop不适用于低延迟数据访问。
2.Hadoop不能高效存储大量小文件。
3.Hadoop不支持多用户写入并任意修改文件。
Hadoop的重要组成
1. Hadoop=HDFS(分布式文件系统)+MapReduce(分布式计算框架)+Yarn(资源协调框架)+Common模块。
Hadoop HDFS:(Hadoop Distribute File System )一个高可靠、高吞吐量的分布式文件系统 --核心思想,分而治之,数据切割、制作副本、分散储存。
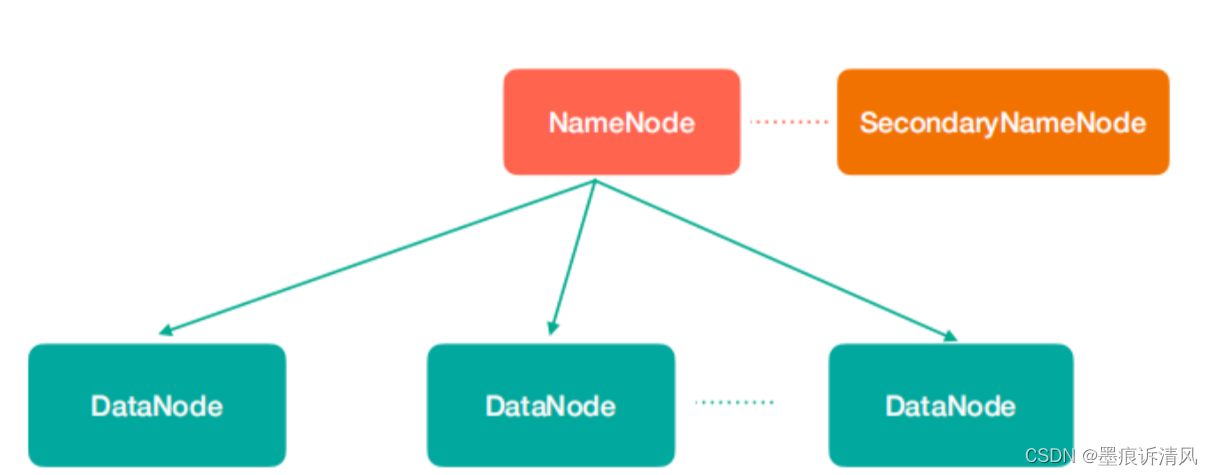
图中涉及到几个角色:
NameNode(nn):存储文件的元数据,比如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等
SecondaryNameNode(2nn):辅助NameNode更好的工作,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据快照。
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验。
注意:NN,2NN,DN这些既是角色名称,进程名称,代指电脑节点名称!!
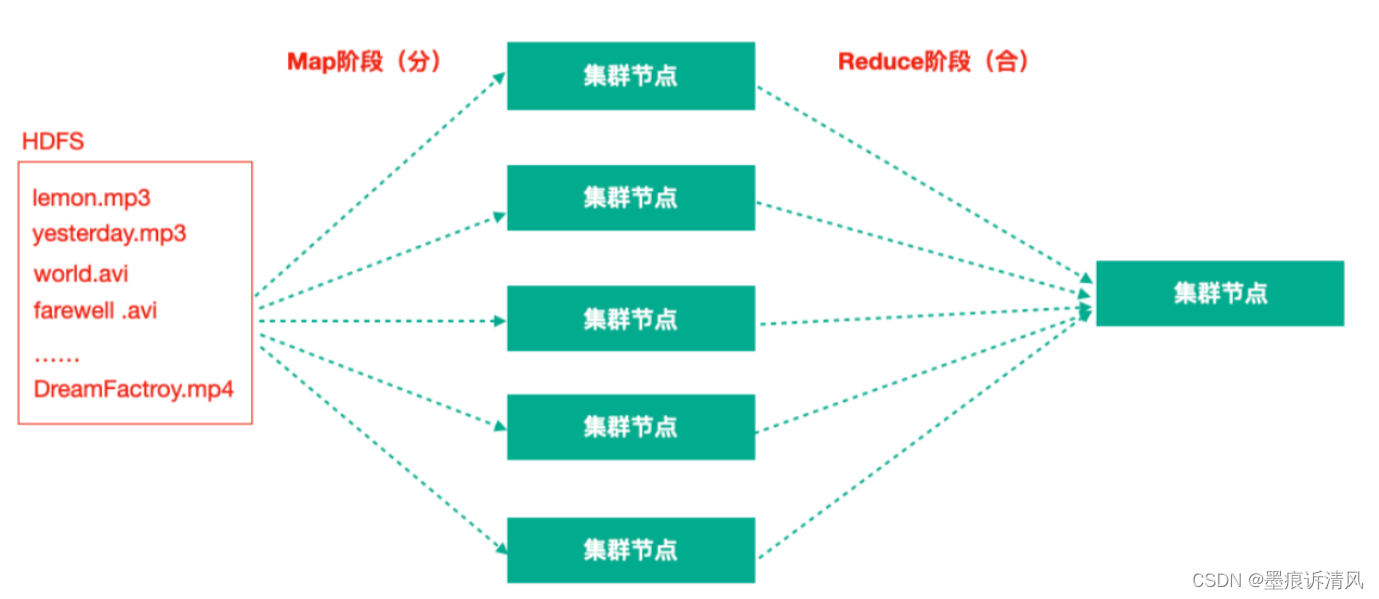
2. Hadoop MapReduce:一个分布式的离线并行计算框架
拆解任务、分散处理、汇整结果
MapReduce计算 = Map阶段 + Reduce阶段
Map阶段就是“分”的阶段,并行处理输入数据;
Reduce阶段就是“合”的阶段,对Map阶段结果进行汇总;
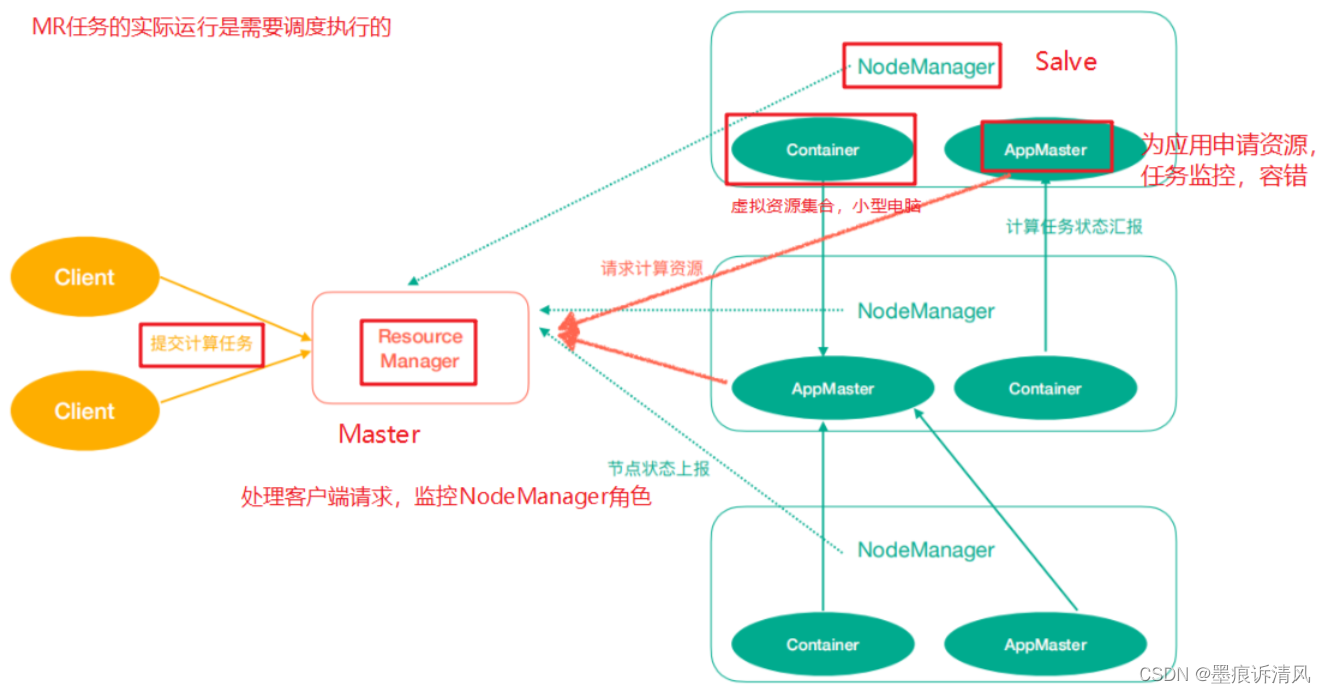
3. Hadoop YARN:作业调度与集群资源管理的框架
计算资源协调
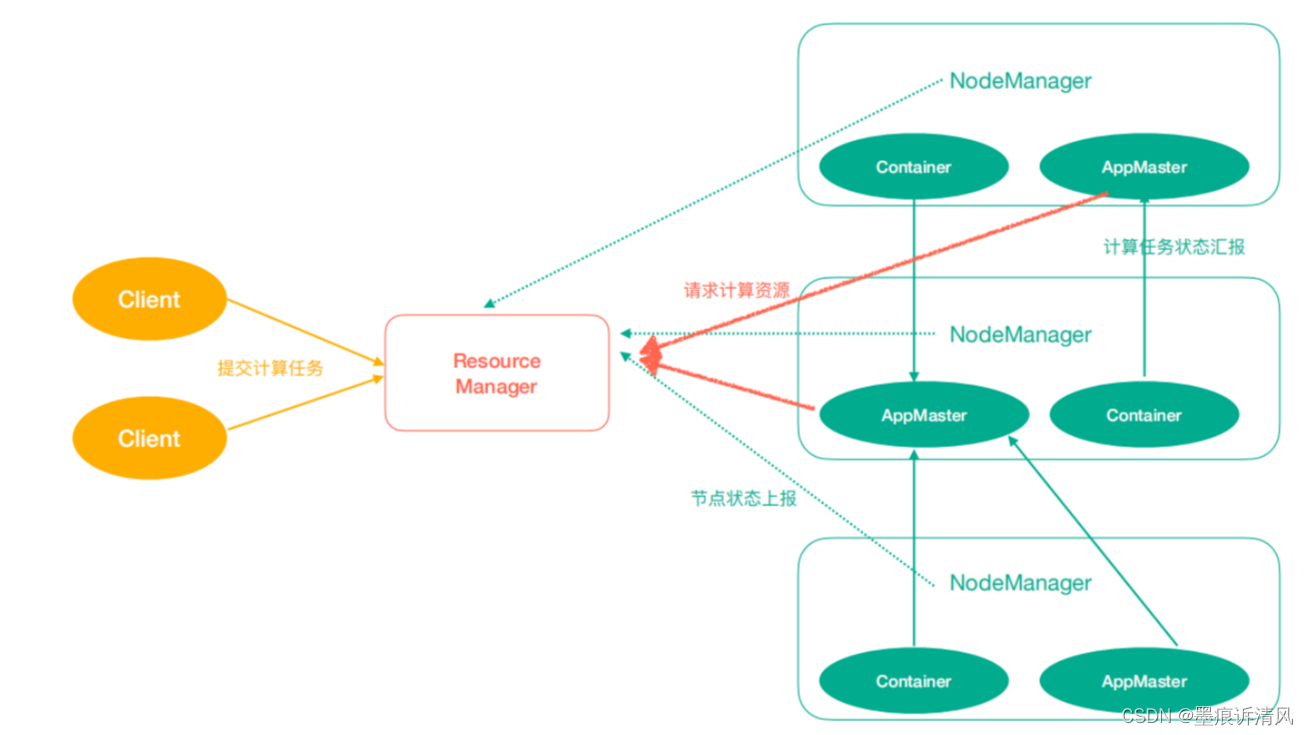
Yarn中有如下几个主要角色,同样,既是角色名、也是进程名,也指代所在计算机节点名称。
- ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
- NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
- ApplicationMaster(am):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错
- Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
- ResourceManager是老大,NodeManager是小弟,ApplicationMaster是计算任务专员。
4. Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
信息安全
通过Hadoop安全部署经验总结,开发出以下十大建议,以确保大型和复杂多样环境下的数据信息安全。
1、先下手为强!在规划部署阶段就确定数据的隐私保护策略,最好是在将数据放入到Hadoop之前就确定好保护策略。
2、确定哪些数据属于企业的敏感数据。根据公司的隐私保护政策,以及相关的行业法规和政府规章来综合确定。
3、及时发现敏感数据是否暴露在外,或者是否导入到Hadoop中。
4、搜集信息并决定是否暴露出安全风险。
5、确定商业分析是否需要访问真实数据,或者确定是否可以使用这些敏感数据。然后,选择合适的加密技术。如果有任何疑问,对其进行加密隐藏处理,同时提供最安全的加密技术和灵活的应对策略,以适应未来需求的发展。
6、确保数据保护方案同时采用了隐藏和加密技术,尤其是如果我们需要将敏感数据在Hadoop中保持独立的话。
7、确保数据保护方案适用于所有的数据文件,以保存在数据汇总中实现数据分析的准确性。
8、确定是否需要为特定的数据集量身定制保护方案,并考虑将Hadoop的目录分成较小的更为安全的组。
9、确保选择的加密解决方案可与公司的访问控制技术互操作,允许不同用户可以有选择性地访问Hadoop集群中的数据。
10、确保需要加密的时候有合适的技术(比如Java、Pig等)可被部署并支持无缝解密和快速访问数据。