分布式大数据处理系统概览(四)
本博文主要对现如今分布式大数据处理系统进行概括整理,相关课程为华东师范大学数据科学与工程学院《大数据处理系统》,参考大夏学堂,下面主要整理HDFS/MapReduce/Spark/Yarn/Zookeeper/Storm/SparkStreaming/Lambda/DataFlow/Flink/Giraph有关的内容。
分布式大数据处理系统大纲
- 分布式大数据处理系统概览(一):HDFS/MapReduce/Spark
- 分布式大数据处理系统概览(二):Yarn/Zookeeper
- 分布式大数据处理系统概览(三):Storm/SparkStreaming
- 分布式大数据处理系统概览(四):Lambda/DataFlow/Flink/Giraph
10 批流融合系统
10.1 批处理与流计算对比:
(1)批处理系统适合处理大批量数据volume,实时性要求不高的应用场景;
(2)流计算系统适合处理快速产生的数据velocity,实时性要求高的应用场景;
10.2 Lambda
(1)设计思想:Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
(2)架构:
# Batch Layer:批处理层(全量计算——针对全体数据进行预运算),主要功能用于存储全体数据集(Master Dataset,不可变),针对这个数据集进行预运算,计算出查询函数,构建对应的view:batch view = funciton1(master data)
# Speed Layer:加速层(增量运算——只对新增的实时数据进行运算):用来处理增量的实时数据(最近增量的数据),并不但更新Realtime View:realtime view = function2(realtime view, new data)
# Servimg Layer:服务层用于响应用户的查询请求,合并Batch View和Realtime View中的结果数据集到最终的数据集。Query = function3(batch view, relatime view)


(3)优缺点:
# 优点:平衡了重新计算高开销和需求低延迟的矛盾
# 缺点:开发复杂,实时数据与全体数据合并困难,运维复杂等
10.3 DataFlow
(1)设计思路:由于Lambda架构仅是将批处理与流处理两个不同的计算框架简单地拼接起来,并不能本质上解决问题。Dataflow计算模型,则是希望从编程模型的源头上,统一解决传统的流式和批量这两种计算语意所希望处理的问题。
(2)数据类型:
# 有界(bounded):系统处理的数据是有界的,对应于批处理数据;
# 无解(unbounded):系统处理的数据是无限的,对应于流数据。
(3)窗口操作:Dataflow认为batch的处理模式只是streaming处理模式的一个子集。在无边界数据集的处理过程中,要及时产出数据结果,无限等待显然是不可能的,所以必然需要对要处理的数据划定一个窗口区间,从而对数据及时的进行分段处理和产出,而各种处理模式(stream,micro batch,session,batch),本质上,只是窗口的大小不同,窗口的划分方式不同而已。

(4)Dataflow时间概念:
# 事件事件Event Time:该事件实际发生的时间;事件一旦发生永远不会变
# 处理时间Processing Time:在数据处理时被系统观察到的时间;持续变化
(5)输入数据的特点:由于各种原因,数据采集,传输到达处理系统的时间可能会有长短不同的延迟,在分布式应用场景环境下,出现延迟,数据乱序到达往往是常态。数据处理过程中需要注意的:

# 操作原语:1、ParDo:用于进行通用的并行化处理;GroupByKey:用来按键将元素重新分组;
# 窗口表达:Dataflow系统中,将常见的流式计算框架中的[key,value]两元组tuple形式的信息数据,变换成了[key,value, event time, window]这样的四元组模型。基于窗口的原子操作(窗口合并、窗口分组、按键分组等)
# 触发器:在某一处理时间决定处理窗口的聚合结果,窗口的语义需要根据事件时间,触发器则需要利用水位线

10.4 一体化执行引擎
(1)将批流系统分开编程变为统一编程:Dataflow、Beam等;将两套执行引擎变为一体化的批流融合执行引擎:Spark Structured Streaming、Flink:
# 以批处理为核心(微批处理——基于批处理来处理无界数据):将无界数据集划分为小批量数据,并启动短作业处理
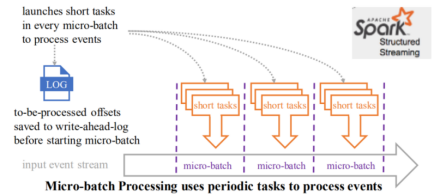
# 以流计算为核心(连续处理):对于有界数据集来说,相当于系统接收一定量的记录之后就不再接收新的记录了,需要启动长作业处理。
11 批流融合系统Flink
11.1 设计思想:
(1)数据模型:Flink将输入数据看做是一个不间断的无界的连续数据项序列DataStream;
(2)迭代模型:Flink将迭代的整体视为一个算子,是一个DAG;
迭代对比:

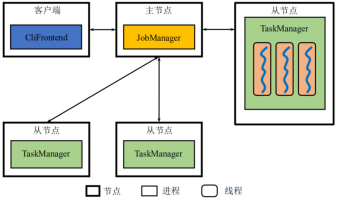
(3)架构:
# Client:JobClient负责接受用户的程序代码,然后创建数据流,并翻译为逻辑执行图并进行chaining优化,将优化后的逻辑执行图提交给 JobManager 以便进一步执行。执行完成后,JobClient将结果返回给用户。
# JobManager(作业管理器):负责协调系统任务执行(任务分配调度、状态快照),管理checkpoint ,故障恢复等;
# TaskManager(任务管理器):从 Job Manager 处接收需要部署的 Task。Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点。任务执行的并行性由每个Task Manager上可用的任务槽决定。 每个任务代表分配给任务槽的一组资源。 例如,如果 Task Manager 有四个插槽,那么它将为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。TaskManager 将内存抽象为多个TaskSlot,Task Manager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。

(4)chainning优化:将某些算子合并到一个Task中执行
11.2 工作原理:
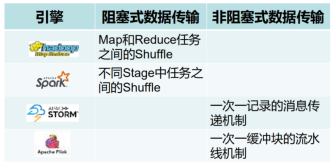
(1)非迭代任务之间的数据交换:
# Flink采用流水线方式进行数据交换,上游的Task将数据存储在buffer缓存中,一旦满了或超时,则向下游的Task发送;Flink的pipeline流水线是不同Task之间的数据传输(相比之下,Spark的pipeline是stage内部同一个Task的多个不同算子之间的数据传输)
# Task之间数据交换方式:阻塞式和非阻塞式:

(2)迭代算子内部的数据交换
# 流式迭代:下左图

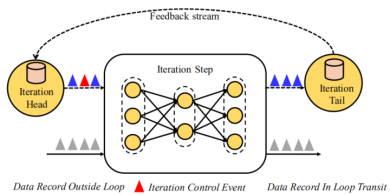
# 批式迭代:当满足迭代停止条件时,iterationHead发出特殊的控制事件,iterationTail不再反馈数据(上右图)
(3)Dataflow模型:
# 事件时间:时间发生的时间;
# 水位线:水位线所示的事件时间表示早于该时间的记录已经完全被系统观察到;
# 窗口与触发器
# 算子的watermaker:上游的算子将watermaker传递给下游算子
(4)Window操作:
# window assigner:负责将元素分配到不同的window;
# trigger:触发器,定义什么情况触发计算;
# 窗口类型:基于处理时间、基于事件时间
11.3 容错
(1)状态管理
# 定义:一种特殊的数据结构,用于记录需要保存的算子计算结果;
# 有状态算子:具备记忆能力的算子(可以保留和已经处理完的输入相关的信息,并对后续输入的处理造成影响);无状态算子:只考虑当前的元素,不会受到处理完毕的元素的影响,也不会影响后续待处理的元素;
# 状态保存与恢复由系统负责;
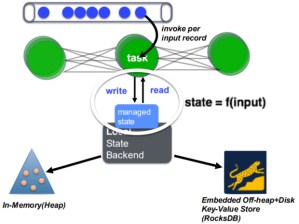
# 状态快照:DAG中若干算子的状态需要同一时刻被保存;
# 系统主要划分三类数据,分别是:进入系统且已成功处理的数据(有状态快照);进入系统但未成功处理的数据;未进入系统的数据;
# 恢复办法:

(2)非迭代计算过程中容错:
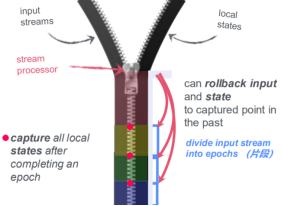
# 同步快照:将数据划分为一系列的片段,处理一个片段时记录所有算子的状态,处理完一个片段后处理下一个片段;类似微批处理,延时高;
# 异步快照:在输入数据时加入一个barrier(屏障),在处理第一个片段时允许下一个片段进入系统;当某一个算子(结点)接收到一个屏障时,需要暂停接收该屏障所在的数据流,等待接收其他所有屏障(该步骤称为片段对齐),避免给算子保存的状态处理到下一个片段的数据
(3)迭代计算过程中的容错:
# 首先向每一个数据源发送屏障,
# 如果节点有多条输入流,在接收到某一条流的屏障之后需要暂时停止对该流的接收,直到接收到该节点所有输入流中的屏障。
# 对于某一个有倒向输入流的节点,记录下每一个倒向流动的数据,直到收到一个倒向的屏障(比如下图图c)。收到倒向的屏障之后,生成当前快照。当前快照的内容包括当前节点的运行状态信息(这个跟有向无环图一样),还包含所有所记录的倒向的数据。在下图中,倒向的数据是被长方形圈住的三个红点。
12 图处理
(1)图处理的设计思想:
# 对图处理算法的调用;
# 支持大规模图处理;
# 自身具备容错能力;
# 为图处理进行优化
(2)MapReduce图处理
# 将图转换为key-value格式的文件;
# 将图计算作为一般的迭代过程;
# 系统为针对迭代进行优化;
# 图计算过程中可能仅需要更新部分结点;
13 Giraph/Pregel模型
(1)数据模型:
# 邻接表&邻接矩阵;
# 顶点与边:[vertextID,value,[targetID,weight1],[targetID2,weight2],…]

(2)计算模型:
# 以顶点为主进行数据表示,顶点执行用户自定义的计算;
# 边不会执行计算;
# Combiner:根据定义的combine()函数将发往同一个顶点的U盾讴歌消息进行合并成一个消息,减少传输和缓存的开销;
# Aggregator:全局通信、监控和数据查看的机制:每个顶点都可以向某个aggregator提供数据,系统对这些值聚合后形成一个值,所有顶点可获取这个值;
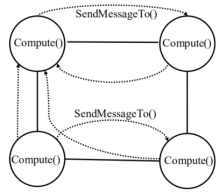
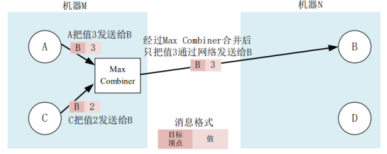
(3)迭代模型:

# BSP模型(Bulk Synchronous Parallel):整体同步准则(超步superstep)
# BSP程序有一系列串行的超步组成,一个超步分为三个阶段:局部计算阶段(每个处理器只对存储本地内存的数据进行本地计算)、全局通信阶段(对非本地的数据进行操作)、栅栏同步阶段(等待所有通信行为的结束)

# Giraph/Pregel的BSP过程:


- 局部计算:读取上一超步得到的消息,并根据自定义的compute函数执行本地计算,更新当前顶点的value以及以该顶点为源点的所有边上的权值;
- 全局通信,通过SendMessageTo函数将消息发送给其他顶点;其他顶点获得消息后继续执行;
- 栅栏阶段:所有顶点等待同步;
14 Pregel架构
(1)Master:负责管理各个Worker执行任务:
# 协调各个Worker执行任务,Worker向Master发送注册信息,Master为Worker分配唯一的ID;
# Master维护Worker的地址信息、ID信息、以及被分配到的分区信息;
# Master维护的数据信息的大小只与分区数量有关,与顶点和边的数量无关;
(2)Worker系统将图进行划分,形成若个分区,每个Worker负责一个或多个分区,并负责针对该分区的计算任务;其所管辖的分区的顶点描述信息时保存在内存中的:
# 顶点与边的值;
# 消息:包含所有接收到的、发送的消息;
# 标志位:用来标记顶点是否处于活跃状态
(3)Coordination Service:协调Master与worker以及worker之间;
15 Giraph
15.1 架构

(1)Giraph参考Pregel体系,而实现过程中借用MapReduce启动Master和Worker进程,执行Giraph作业只启动了Map任务;
(2)Giraph采用Zookeeper服务管理体系,通过分布式选主,选择一个Map任务作为Giraph Master;同时Zookeeper支持BSP模式中的栅栏同步;
(3)运行流程:



15.2 工作原理
(1)图数据的划分:
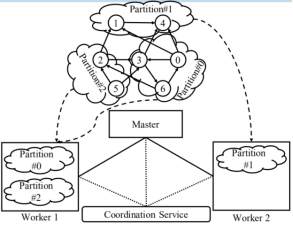
# Giraph将一张图根据顶点分解为多个分区,再根据ID将顶点分配到各个分区,默认划分函数Hash(ID) mod N,其中N为分区的总数;
# 数据划分实际上是完成输入数据(HDFS上的划分可能是对数据的排序,Giraph则是按照取模)到Giraph期望分区的调整;
(2)超步计算:


# MegStore:存储两份信息:(t)存储在超步t-1全局通信阶段获取的消息,此消息用于t超步的compute计算;(t+1)在超步t获取的消息,用于t+1超步的compute计算。亦即:在当前t阶段,既要存储上一超步得到的消息并在此时进行计算的同时,还要接收当前收到的新信息;
# 当前超步t中,需要存储两份标志位:

某一顶点的处理过程:

(3)Worker同步:
# 多个worker同时进行超步计算,同步控制保证每个worler都完成超步t后再进入t+1;Master与Giraph通过Zookeeper完成同步;
# 超步同步完成后根据StatStore t+1信息把在下一个超步还处于活跃状态的顶点数目通知Master,若数量为0,则迭代过程结束,Worker对各自计算结果进行持久化存储;该部分与MapReduce区别在于MapReduce迭代过程中每次产生中间结果都需要反复读写HDFS,而Giraph的中间结果存储在内存中;
15.3 容错
(1)主节点JobTracker故障:重启;
(2)从节点:
# Master故障:
# Worker故障:设置检查点:设置检查点间隔,即每个一定超步,Master通知所有的Worker将管辖的分区状态(顶点、边、接收到的消息)写入持久化存储中;
# Worker故障恢复:

分布式大数据处理系统大纲
- 分布式大数据处理系统概览(一):HDFS/MapReduce/Spark
- 分布式大数据处理系统概览(二):Yarn/Zookeeper
- 分布式大数据处理系统概览(三):Storm/SparkStreaming
- 分布式大数据处理系统概览(四):Lambda/DataFlow/Flink/Giraph
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。喜欢请关注+点赞o( ̄▽ ̄)d
