本文针对Ngram语言模型的训练过程进行描述,针对神经网络在语言模型中的应用
不在本文范围之内,后续有兴趣可进行研究。1. 训练工具
常用的LM训练工具有Srilm,IRSTLM,MITLM,Kenlm等。
SRILM诞生于1995年,由SRI实验室负责开发维护。SRILM用来构建和应用统计语言模型,主要用于语音识别,统计标注和切分,以及机器翻译。其主要目标是支持语言模型的估计和评测。
2. 训练过程
- 大文本数据切分
split -d -C 100m trainfile.txt filedir/- 切分文件列表写入filepath
ls \$(echo $PWD)/filedir/* > filepath- 各文本单词统计词频,合并,去掉低频词,构建词典
make-batch-counts filepath 1 cat ./counts1 -order 1
merge-batch-counts ./counts1
...(脚本处理count1/*.ngram.gz => vocab1)- 各文本统计3gram词频,合并
make-batch-counts filepath 1 cat ./counts3 -order 3
merge-batch-counts ./counts3- 训练语言模型
make-big-lm -read counts3/*.ngrams.gz -vocab vocab1 -lm train.lm -order 3 [-interpolate -kndiscount]训练得到的语言模型还可通过剪枝减小模型大小,或者合并多个语言模型。
- 语言模型剪枝
ngram -lm \${oldlm} -order 3 -prune \${thres} -write-lm \${newlm}其中,-prune threshold 删除一些ngram,满足删除以后模型的ppl增加比例小于threshold,越大剪枝剪得越狠。
- 语言模型合并
ngram -lm \${mainlm} -order 3 -mix-lm \${mixlm} -lambda 0.8 -write-lm \${mergelm}其中, -mix-lm 用于插值的第二个ngram模型,-lambda 主模型(-lm对应模型)的插值比例。
3. 模型评估
语言模型的评估可通过困惑度(preplexity)来进行,基本思想是给测试集的句子赋予较高概率值的语言模型较好。
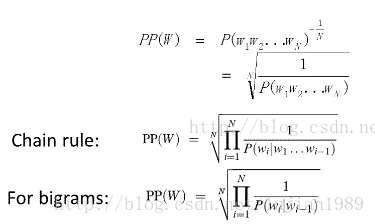
由以上公式可知,困惑度越小,句子概率越大,语言模型越好。
计算ppl方法如下:
ngram -ppl testfile -order 3 -lm train.lm -debug 0 > file.ppl其中testfile为测试文本, -debug 0 只对整体情况进行困惑度计算,-debug 1 具体到句子, -debug 2具体每个词的概率,最后 将困惑度的结果输出到file.ppl。
4. 参考文章
大牛讲堂 | 语音专题第二讲,语言模型技术 http://www.leiphone.com/news/201609/Nl14feo83UoL7Sc4.html
xmdxcsj 语言模型 http://blog.csdn.net/xmdxcsj/article/category/5981983
斯坦福大学自然语言处理第四课 “语言模型(Language Modeling)” http://52opencourse.com/111/%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E7%AC%AC%E5%9B%9B%E8%AF%BE-%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%EF%BC%88language-modeling%EF%BC%89