http://blog.csdn.net/pipisorry/article/details/78677580
语言模型的评估主要measure the closeness,即生成语言和真实语言的近似度。
Classification accuracy
Perplexity
perplexity is the geometric mean of the inverse probability for each predicted word.
For fair comparison, when computing the perplexity with the 5-gram LM, exclude all test words marked as 〈unk〉 (i.e., with low counts or OOVs) from consideration.
Meteor
[S. Banerjee and A. Lavie, “Meteor: An automatic metric for MT evaluation with improved correlation with human judgments,” in Proc. ACL Workshop Intrinsic Extrinsic Eval. Measures Mach. Transl. Summarization]
ROUGE
is a recall-oriented measure widely used in the summarization literature. It measures the n-gram recall between the candidate text and the reference text(s).
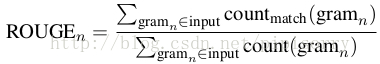
where count match denotes the number of n-grams co-occurring in the input and output.
一般ROUGE-1, 2 and W (based on weighted longest common subsequence).
[C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Proc. ACL Workshop Text Summarization Branches Out, 2004]
Blue
a form of precision of word n-grams between generated and reference sentences.Purely measuring recall will inappropriately reward long outputs. BLEU is designed to address such an issue by emphasizing precision.
n-gram precision scores are given by:
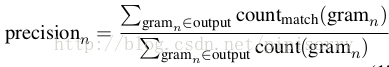
BLEU then combines the average logarithm of precision scores with exceeded length penalization.
most previous work report BLEU-1, i.e., they only compute precision at the unigram level, whereas BLEU-n is a geometric average of precision over 1- to n-grams.
[K. Papineni, S. Roukos, T. Ward, and W. J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” ACL2002]
Coherence Evaluation
Cider
it measures consistency between n-gram occurrences in generated and reference sentences, where this consistency is weighted by n-gram saliency and rarity.
不同评估方法的缺点讨论亦可参考[Vedantam, R., Lawrence Zitnick, C., & Parikh, D. Cider: Consensus-based image description evaluation. CVPR2015]
人工评估
ask for raters to give a subjective score
使用Amazon Mechanical Turk
如imge caption中following the guidelines proposed in [M. Hodosh, P. Young, and J. Hockenmaier, “Framing image description as a ranking task: Data, models and evaluation metrics,” J. Artif. Intell. Res.2013]
或者[Jaech, et al "Low-Rank RNN Adaptation for Context-Aware Language Modeling." arXiv2017]
from: http://blog.csdn.net/pipisorry/article/details/78677580
ref: [Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. TPAMI2017]
[Hoang, et al "Incorporating Side Information into Recurrent Neural Network Language Models." NAACL2016]