摘要
我们介绍Merlin语音合成工具包用于基于神经网络的语音合成。该系统将语言特征作为输入,采用神经网络来预测声学特征,然后将声学特征传递到声音合成机(vocoder)以产生语音波形。不同的神经网络架构已被实现,包括标准的前馈神经网络,混合密度神经网络,递归神经网络(RNN),长短时记忆(LSTM)递归神经网络,以及其他。该工具包开源,Python编写,可扩展。本文简要描述该系统,提供可自由获取的语料库上的一些基准结果。
索引词:语音合成,深度学习,神经网络,开源,工具包
1. 介绍
文字转语音(TTS)涉及给定文字输入,生成语音波形。一般可自由获取的工具包用到了两种广泛使用的方法:波形拼接,基于HMM的统计参数语音合成(简称SPSS)。即使好的波形拼接语音的自然度仍然通常情况下显著优于通过SPSS使用声音合成机生成的语音,灵活、可控制、小体量的优势,意味着SPSS依然是一个有吸引力的议题。
在SPSS中,一个重要的限制合成语音自然度的因素是声学模型,该模型学习语音和声学特征之间的关系,而这是一个复杂的非线性回归问题。过去几十年,隐马尔科夫模型(HMM)在声学建模中占支配地位。HMM参数化的方式很关键,这一般需要使用回归树进行模型聚类(或绑定)用于声学和语言学相关的上下文。然而必需的上下文交叉取平均相当地降低了合成语音的质量。有理由说基于HMM的SPSS应该更准确地成为基于回归树的SPSS,然后有一个明显的问题:为什么不使用一个比树更强大的模型呢?
近来,神经网络被“重新发现”用作SPSS声学模型。在1990年代,神经网络已经被用于学习语言和声学特征的关系,作为时长模型预测分段时长,从原始文本输入中提取语言特征。今天和1990年代的主要区别在于:更多的隐藏层,更多的训练数据,更先进的计算资源,更先进的训练算法,以及用于完整的参数化语音合成器的各种其他技术的重大进步,如声音合成机,参数补偿/增强/后值滤波技术。
1.1 神经网络语音合成的近期工作
近期的研究中,受限玻尔兹曼机(RBM)被用于取代高斯混合模型用于建模声学特征的分布。这项工作声称RBM可以建模频谱细节,得到更好质量的合成语音。深度置信网络(DBM)作为深层生成性模型被共同用于建模语言和声学特征的关系。深层混合密度网络和实值音轨神经自回归密度估计函数(trajectory real-valued neural autoregressive
density estimators)同样被用于预测声学特征的概率密度函数。
深度前馈神经网络(DNN)作为深层条件模型是文献中直接映射语言特征和声学特征的流行模型。DNN可被视为基于HMM语音中的决策树的替代。也可被用于直接建模高维频谱。在前馈框架中,一些技术被用于提高性能,如多任务学习,最小生成误差。然而。DNN逐帧执行映射而没有考虑上下文约束,即使堆叠的bottleneck特征可以包含一些短时上下文信息。
为了包含上下文约束,基于一个双向长短时记忆网络(LSTM)的RNN被用于表达TTS为一个序列到序列的映射问题,也就是将一个序列的语言特征映射到相应学列的声学特征上。包含递归输出层的LSTM也被提出以包含上下文约束。LSTM与基于RNN的门递归单元(GRU)和混合密度模型结合预测概率密度函数序列。基于LSTM的RNN的系统分析也被提出以提供关于LSTM的更好理解。
1.2 新工具包的需求
近来,即使语音合成中神经网络的使用有了爆发需求,荏苒却是一个真正的开源工具包。这样一个工具包能够支撑可复现的研究,允许竞争技术更精确的交叉比较,像是HTS工具包在基于HMM的工作中的方式一样。在本文中,我们介绍Merlin,一个基于神经网络的开源语音合成系统。这一系统已经被广泛用于许多近期研究论文的工作中。本文简要介绍工具包的设计和实现,并提供在一个可自由获取的语料库上的基准结果。
除了这儿的结论和上述一系列之前发表的论文,Merlin也是2016 Blizzard挑战赛的DNN基准系统。那儿,它与Ossian前端,WORLD声音合成机结合使用,这些都是开源的,使用不受限制,提供了一个简单可复现的系统。
2. 设计和实现
像HTS一样,Merlin不是一个完整的TTS系统。它提供了核心的声学建模功能:语言特征矢量化,声学和语言特征归一化,神经网络声学模型训练和生成。当前,波形生成模块支持两种声音合成机:STRAIGHT和WORLD,但是工具包可以在未来很容易扩展到其他声音合成机。也同样容易连接到不同的前端文本处理器。
Merlin用Python语言编写,基于theano库。一起推出的有源码的文档,以及一个示例样本集用于不同的系统配置。
2.1 前端
Merlin需要一个外部的前端,比如Festival或者Ossian。前端的输出当前必须被格式化为HTS风格的标签,带有state级对齐。工具包将标签转换为二进制连续特征向量作为神经网络的输入。特征通过使用HTS风格问题从label文件得到。也可以直接提供已经矢量化的输入特征,如果HTS类似的工作流不方便的话。
2.2 声音合成机
当前,系统支持两种声音合成机:STRAIGHT(C语言版)和WORLD。STRAIGHT不能包含在分发中因为它不是开源的,但是Merlin包含了WORLD声音合成机的一个修改版本。修改添加了独立的分析和合成执行文件,这对于SPSS是必须的。不难支持其他声音合成机,如何做的细节可以阅读包含文档。
2.3 特征归一化
在训练神经网络之前,归一化特征是很重要的。工具包支持两种归一化方法:最小最大,均值方差。最小最大归一化会归一化特征到[0.01 0.09]范围,均值方差归一化会归一化特征到零均值单位方差。当前,默认的语言特征做最小最大归一化,输出声学特征做均值方差归一化。
2.4 声学建模
Merlin包含若干当前流行的声学模型的实现,每种都以一个示例样本来描述其使用。
2.4.1 前馈神经网络
前馈神经网络是最简单的网络类型。有了足够多层,该结构通常成为深度神经网络(DNN)。通过若干隐藏单元的层,输入被用来预测输出,每个隐藏单元执行非线性函数,如下:
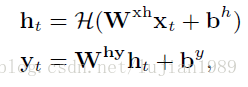
其中,H(.)是隐藏层的非线性激活函数,W(xh)和W(hy)是权重矩阵,b(h)和b(y)是偏置向量,W(hy).h(t)是一个线性回归,用于从之前隐藏层的激活来预测目标特征。图1是前馈神经网络的说明。
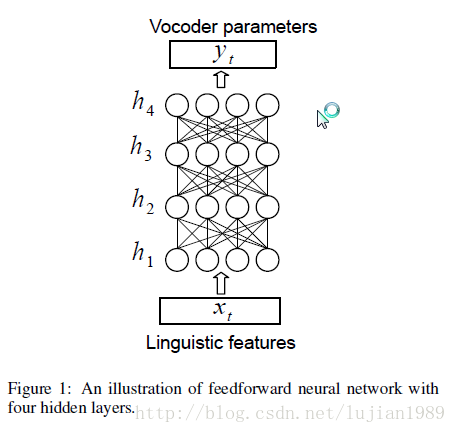
它将语言特征作为输入,通过若干隐藏层(图中为4层)来预测声音合成机的参数。在本文余下部分,我们将用DNN来表示这一类型的前馈神经网络。在工具包中,sigmoid和双曲线正切激活函数支持隐层。
2.4.2 基于LSTM的RNN
在DNN中,语言特征被逐帧映射到声音合成机参数而不考虑语音的连续自然。作为对比,递归神经网络(RNN)被设计为序列到序列的映射。长短时记忆(LSTM)单元是实现RNN的流行方式。
LSTM是语音识别中普遍使用的架构,他被表示为:
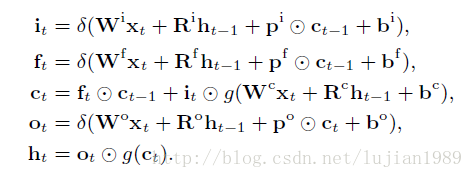
其中i(t),f(t)和o(t)分别是输入门,遗忘门,输出门。c(t)是所谓的记忆单元,h(t)是t时刻的隐藏激活,x(t)是输入信号,W(*)和R(*)是应用到输入和递归隐藏单元的权重矩阵。p(*)和b(*)是peep-hole连接和偏置。δ(.)和g(.)是sigmoid和双曲线正切激活函数,◎指element-wise
product。
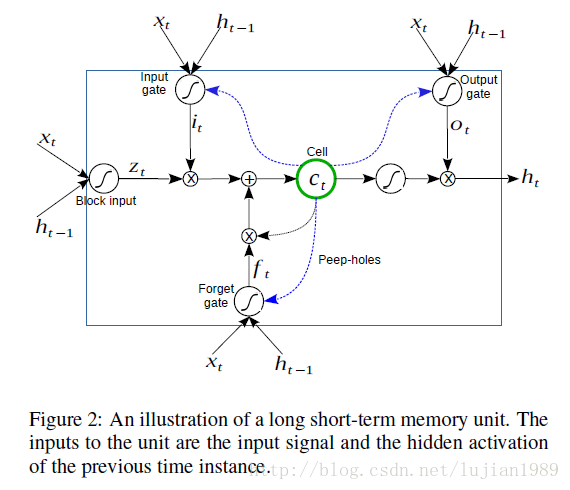
图2成仙了一个标准LSTM单元的说明。它将输入信号和前一时间实例的隐藏激活传送通过输入门,遗忘门,记忆单元和输出门来产生激活。在我们的实现中,其若干变体也同样适用。
2.4.3 双向RNN
在单向RNN中,只有来自过去时间实例的上下文信息被考虑,然而在双向RNN中可以学习时间中前向和后向传播的信息。一个双向RNN可以被定义为:
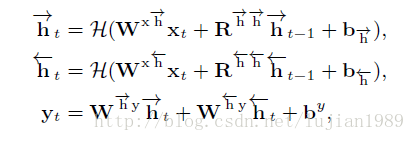
其中[前向h(t)]和[后向h(t)]分别是来自正反方向的隐藏激活,W(x[前向h(t)])和W(x[后向h(t)])是输入信号的权重矩阵,R([前向h(t)][前向h(t)])和R([后向h(t)][后向h(t)])分别是前后向的递归矩阵。
在双向RNN中,隐藏单元可以without gating,或者gated units such as LSTM。我们使用BLSTM来表示一个基于双向LSTM的RNN。
2.4.4 其他变体####
在Merlin中,神经网络的其他变体也实现了,比如门递归单元(GRU),简化LSTM和LSTM,GRU的其他变体。所有这些基础单元都可以通过简单改变配置文件组合到一起,以创建一个新的结构。例如,为了实现使用双曲线正切单元的4层前馈神经网络,可以在配置文件中简单指定如下结构:
[TANH, TANH, TANH, TANH]
相似的,一个基于双向LSTM的RNN可以在配置文件中被指定为
[TANH, TANH, TANH, BLSTM]
支持单元类型的更多细节可以在系统的文档中找到。
3. 基准性能
3.1 实验设置
为了描述工具包的性能,我们在Merlin中报告了若干架构实现的基准实验。实验中使用了来自于一个英国男性职业演讲者的可自由获取语料库。使用的语音信号采样率为48kHz。2400句作为训练集,70句作为开发集,72句作为评估集。所有集合是不相关的。
所有实验的前端是Festival。所有神经网络的输入特征为491维。其中482维由语言上下文得到,包括音节、词、短语中的五音子id,词性和位置信息,等等。剩下9维是音素内部位置信息:帧在HMM状态及音素中的位置,状态在前向后向音素中的位置,以及状态和音素时长。帧对齐和状态信息是由强制对齐取得,通过基于单音素HMM得新系统,其每个音素有5个发射状态。
我们在实验中使用了两种声音合成机:STRAIGHT和WORLD。STRAIGHT(C语言版)不开源,用来在5毫秒帧间隔上提取60维梅尔频谱系数(MCC),25 band aperiodicities(BAP),和对数尺度上的基频(log F0)。类似的,WORLD开源,用来在5毫秒帧间隔上提取60维MCC,5维BAP,及log F0。神经网络的输出特征包含了MCC、BAP、log F0以及他们的差分,差分的差分,加上浊音/轻音的二进制特征。
在训练之前,输入特征使用最小最大方法归一化到[0.01 0.09]范围,输出特征归一化到零均值单位方差。在合成时刻,最大似然参数生成(MLPG)被用于从非归一化神经网络输出中生成平滑参数音轨,然后频谱增强在倒谱域被用于MCC来增强自然度。语音信号处理工具包(SPTK)被用来实现频谱增强。
这儿我们报告4个基准系统:
DNN:6个前馈隐层,每个隐层1024个双曲线正切单元。
LSTM:混合结构,4个每层1024个双曲线正切单元的隐层,随后是单个512单元的LSTM层。
BLSTM:与LSTM相似的混合结构,但是用384单元的BLSTM层取代了LSTM层。
BLSTM-S:与BLSTM一样的结构。差分与差分的差分特征从输出特征向量发射,不使用MLPG。理论上,该BLSTM结构应该在训练中学习获得差分特征,并生成已经平滑的音轨。
3.2 客观结果
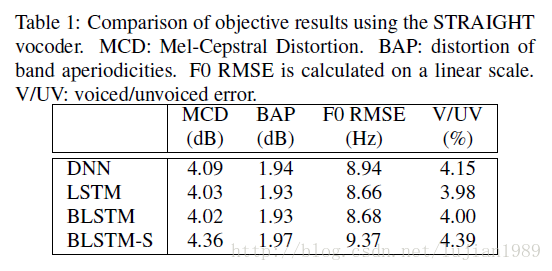
四个系统使用STRAIGHT声音合成机的客观结果呈现在表1中。LSTM和BLSTM和期望的一样,相比DNN获得了更好的结果。不在训练过程中使用动态特征也不采用MLPG的BLSTM-S比其他结构有更高的客观错误。
同样四个结构的客观结果呈现在表2,但这次使用了WORLD声音合成机。和使用STRAIGHT的结果类似。注意F0 RMSE和V/UV不能直接在表1和表2间比较,因为它们使用了不同的F0提取器。对于两个声音合成机,我们使用了各自工具创建者的默认设置。
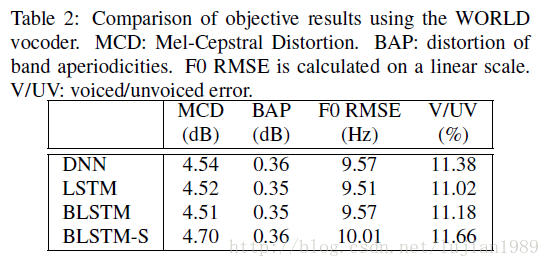
一般来说,客观结果证实了LSTM和BLSTM相比DNN能够获得更好的结果,但是动态特征和MLPG对于BLSTM仍然有用,即使它理论上有能力建模必需的音轨信息。
3.3 主观结果
我们进行了MUSHRA (MUltiple Stimuli with Hidden Reference and Anchor)听力测试来主观评估合成语音的自然度。我们在两个独立的MUSHRA测试中分别采用STRAIGHT和WORLD声音合成机,评估所有四个基准系统。
在每个MUSHRA测试中,有30位英国本地的英语听者,每位评价从评估集中随机选取的20个集合。每个集合中,一段有着相同语言内容的自然语音作为隐藏参照被包含。听者被指导给每个激励一个0到100间的分数,并给每个集合的其中之一评为100,这意味着是自然的。
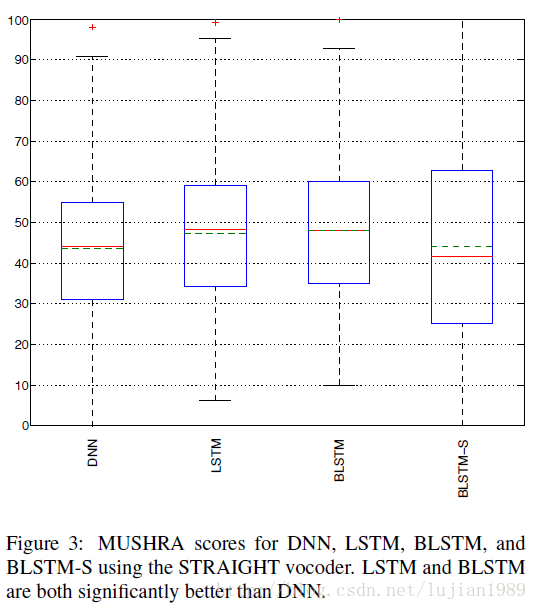
使用STRAIGHT的系统MUSHRA得分呈现在图3中。可观察到LSTM和BLSTM明显好于DNN。BLSTM比LSTM生成的语音稍微更自然一些,但是区别并不明显。也可以发现BLSTM比BLSTM-S明显更自然,这和上述报告的客观错误相一致。
使用WORLD的系统MUSHRA得分呈现在图4中。不同系统间相对差别和STRAIGHT例子类似
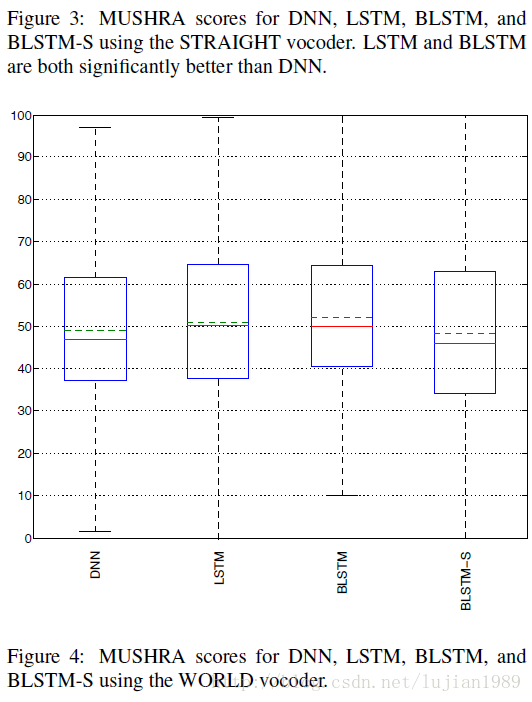
一般来说,主观结果和客观结果是一致的,不论哪个声音合成机趋势是相似的。客观和主观结果证实,LSTM和BLSTM相比DNN提供了更好的性能,MLPG对于BLSTM仍然有用。
4. 结论
在本文中,我们介绍了开源Merlin语音合成工具包,并在一个语料库上提供了可复现的基准结果。我们希望该系统的获得能够促进神经网络语音合成的开放研究,使不同神经网络配置间的比较更加容易,允许研究者报告可复现的结果。发布的工具包,包含可复现本文所有结果的示例样本,这也产生了我们近期的一些发表文章。我们的意向是,未来使用工具包发表的结果也能够伴随有示例样本。