因为要用到大量数学运算,所以,首先我们载入numpy库
import numpy as np
然后我们定义sigmoid函数
def sigmoid(z):#定义sigmoid激活函数
return 1/(1+np.exp(-z))
接下来是参数初始化
def initialize_parameters(n_x,n_h,n_y):#初始化参数(权重和偏置)
W1=np.random.randn(n_h,n_x)
b1=np.zeros((n_h,1))
W2=np.random.randn(n_y,n_h)
b2=np.zeros((n_y, 1))
parameters={"W1":W1,"b1":b1,"W2":W2,"b2":b2}
return parameters
然后我们定义前向传播函数
def forward_prop(X,parameters):#前向传播
W1=parameters["W1"]
b1=parameters["b1"]
W2=parameters["W2"]
b2=parameters["b2"]
Z1=np.dot(W1,X)+b1
A1=np.tanh(Z1)
Z2=np.dot(W2,A1)+b2
A2=sigmoid(Z2)
cache={"A1":A1,"A2":A2}
return A2,cache
损失函数的计算
def calculate_cost(A2,Y):#计算损失函数
cost=-np.sum(np.multiply(Y,np.log(A2))+np.multiply(1-Y,np.log(1-A2)))/m
cost=np.squeeze(cost)#从数组的形状中删除单维条目,即把shape中为1的维度去掉
return cost
反向传播的计算
def backward_prop(X,Y,cache,parameters):#反向传播(计算梯度)
A1=cache["A1"]
A2=cache["A2"]
W2=parameters["W2"]
dZ2=A2-Y
dW2=np.dot(dZ2,A1.T)/m
db2=np.sum(dZ2,axis=1,keepdims=True)/m
dZ1=np.multiply(np.dot(W2.T,dZ2),1-np.power(A1,2))
dW1=np.dot(dZ1,X.T)/m
db1=np.sum(dZ1,axis=1,keepdims=True)/m
grads={"dW1":dW1,"db1":db1,"dW2":dW2,"db2":db2}
return grads
梯度下降计算:
def updata_parameters(parameters,grads,learning_rate):#使用梯度下降更新参数
W1=parameters["W1"]
b1=parameters["b1"]
W2=parameters["W2"]
b2=parameters["b2"]
dW1=grads["dW1"]
db1=grads["db1"]
dW2=grads["dW2"]
db2=grads["db2"]
W1=W1-learning_rate*dW1
b1=b1-learning_rate*db1
W2=W2-learning_rate*dW2
b2=b2-learning_rate*db2
new_parameters={"W1":W1,"W2":W2,"b1":b1,"b2":b2}
return new_parameters
整合前面的函数,形成整体:
def model(X,Y,n_x,n_h,n_y,num_of_iters,learning_rate):#将上面的函数整合起来,成为训练函数整体
parameters=initialize_parameters(n_x,n_h,n_y)
for i in range(0,num_of_iters+1):
a2,cache=forward_prop(X,parameters)
cost=calculate_cost(a2,Y)
grads=backward_prop(X,Y,cache,parameters)
parameters=updata_parameters(parameters,grads,learning_rate)
if(i%100==0):
print('cost after iteration#{:d}:{:f}'.format(i,cost))
return parameters
定义预测函数:
def predict(X,parameters):#利用训练完的模型进行预测
a2,cache=forward_prop(X,parameters)
yhat=a2
yhat=np.squeeze(yhat)
if(yhat>=0.5):
y_predict=1
else:
y_predict=0
return y_predict
下面,我们用主程序训练,并测试
#主程序
np.random.seed(2)
X=np.array([[0,0,1,1],[0,1,0,1]])
Y=np.array([[0,1,1,0]])
m=X.shape[1]#训练样本数
n_x=2
n_h=2
n_y=1
num_of_iters=1000
learning_rate=0.3
#训练模型
trained_parameters = model(X, Y, n_x, n_h, n_y, num_of_iters, learning_rate)
#测试数据
X_test=np.array([[0],[1]])
y_predict=predict(X_test,trained_parameters)
print('NN for example({:d},{:d}) is {:d}'.format(X_test[0][0],X_test[1][0],y_predict))
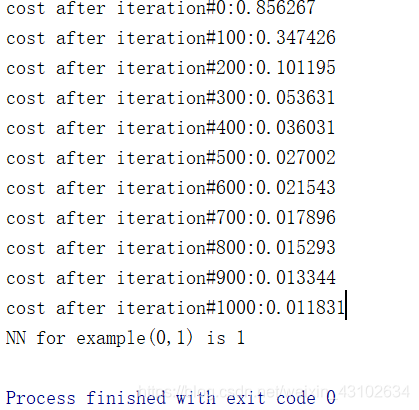
结果如下: