在我们处理爬虫的时候,有许多文本信息,如电影简介、新闻报道以及评论等,而关键词提取是指从大量文本中提出最核心、最主要的关键词,而实现关键词提取算法的算法有两种:1. TextRank: 基于词与词直接的上下文关系构建共现网络,将处于网络核心位置的词作为关键词、2. TF-IDF:选出一般不常用但是在指定环境文本中频繁出现的词作为关键词。
信息的抽取是从非结构化文本中抽取出有意义或者感兴趣的字段。例如对于一篇新闻报告,从里面提取出标题,事件,时间,主人公等字段,从而将非结构化文本转化为结构化数据,便于信息管理和数据分析。
使用jieba分词处理中文
中文分词的模型实现主要分为两大类: 基于规则和基于统计。jieba提供3种粉刺模式:1. 精确模式--将句子最精确地切开,适合文本分析。2. 全模式--把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。 3. 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词。
import jieba.analyse
def main():
content = u'目前骑士队和勇士队的总决赛已经打了两场,而这两场比赛均以骑士队输球告终,看起来骑士队好像真的很难与勇士队相抗衡。\
而不同于往年激烈的总决赛中,大家都在讨论比赛。今年的总决赛,大家都把点放在詹姆斯到底会去哪支球队,以及火箭队到底会引进哪位超级巨星上。\
即使很多人都说詹姆斯可能会在今年夏天做出决定三,甚至有很多NBA球员都已经开始建议詹姆斯去火箭队一起对抗勇士了,\
但是骑士队也没有放弃尝试续约詹姆斯。据夏洛特当地媒体《夏洛特观察家》的记者里克·博纳尔报道称,骑士队已经开始有所动作,\
他们尝试用手中的8号签以及两名球员为主体换来黄蜂队的当家控卫肯巴·沃克。其实在本赛季交易截止日之前,就有球队问价黄蜂队,\
希望得到沃克,但是当时黄蜂队的要求是必须打包巴图姆,因为巴图姆的上亿合同已经影响到了黄蜂队未来的引援补强工作。\
而这次骑士队已经再一次尝试报价沃克,据,骑士队能够给出的筹码会是8号签+乔治·希尔再加特里斯坦汤普森,\
但是不知道这样的筹码够不够吸引黄蜂队。要知道沃克在黄蜂队这几年打出了全明星身价,场均得分22分,还有5.4次助攻,\
沃克要是真的去骑士队的话,完全配的上是詹姆斯身边的第三巨头。但是目前最大的问题是合同和筹码问题,\
黄蜂队不可能轻易放走沃克,更不会轻易接受TT的垃圾合同。所以如果骑士队真的像通过招募第三巨头留下詹姆斯的话,\
必定是要下血本的。而当里克·博纳尔报到出这一则消息之后,很多球迷表示,其实并不一定希望詹姆斯就离开骑士队,\
只是希望詹姆斯能够有更好的队友,希望詹姆斯能够不再孤立无援。如果骑士队真的能够组建更好的阵容,\
詹姆斯留在骑士队也是不错的选择。那么各位球迷是否看好骑士队的交易动向,又对詹姆斯的未来有什么看法呢?'
key_words = jieba.analyse.extract_tags(content, topK=10, withWeight=True, allowPOS=('n', 'v'))
for key_word in key_words:
# 分别为关键词和相应的权重
print(key_word[0], key_word[1])
if __name__ == '__main__':
main()
输出:
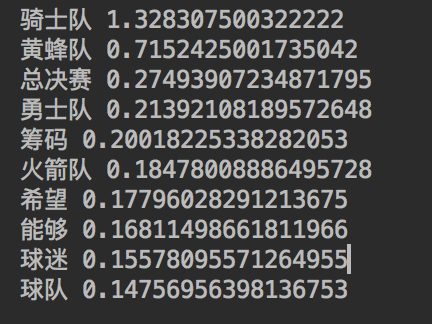
其中,key_words = jieba.analyse.extract_tags(content, topK=10, withWeight=True, allowPOS=('n', 'v'))里面的参数,content代表待提取关键词的文本, topK代表返回关键词的数量,重要性从高到低, withWeight表示是否同时返回每个关键词的权重, allowPOS代表词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词。
词嵌入
词嵌入可以将文本和词语转换为机器能够接受的数值向量。 就好比是,我们给机器传输一个词 -“电脑”, 让机器分析“电脑”和“电视”这两个词之间的相关性,通过字符串匹配只能得到完全不相等的结论,但是它们属于电器,因此词语所蕴含的语义实际上非常复杂,无法通过简单的字符串表示。而语言的表示主要有两种:符号主义和分布式表示。
符号主义
符号主义: Bag of words,即词袋模型。如果将语料词典中的每个词都看作一个袋子,那么一句话无非是选择一些袋子,然后将出现的词丢入相应的袋子。即词典中一共有n个词,就可以用n个 n维向量来表示每个词。以下是一个简单的例子,这里的词典中只有5个词:苹果、梨子、香蕉、和、好吃,分别用一个五维向量表示,仅对应的维度上为1,其他维度都为0。词袋模型可以方便地用一个n维向量表示任何一句话,每个维度的值即对应的词出现的次数。
dictionary = {
"苹果": [1, 0, 0, 0, 0],
"梨子": [0, 1, 0, 0, 0],
"香蕉": [0, 0, 1, 0, 0],
"和": [0, 0, 0, 1, 0],
"好吃": [0, 0, 0, 0, 1]
}
# 苹果好吃: [1, 0, 0, 0, 1]
# 梨子和香蕉好吃: [0, 1, 1, 1, 1]
# 苹果好吃苹果好吃: [2, 0, 0, 0, 2]
词袋模型缺点也很明显, 当词典中的数量增大时,向量的维度将随之增大,当维度变得很大的时候,就会让计算带来很大的不方便。无论是词还是句子的表示,向量都过于稀疏,除了少数维度之外的大多数维度都为0。每个词对应的向量在空间上都两两正交,任意一对向量之间的内积等数值特征都为0, 无法表达词语之间的语义关联和差异。当表示句子的时候,其向量表示丢失两词序特征,即“我很不高兴”和“不我很高兴”对应的向量相同,但实际语义是不符合的。
分布式表示
分布式表示即 Word Embedding, 即词嵌入,使用低维,稠密、实值的词向量来表示每一个词,从而赋予词语丰富的语义含义,并使得计算词语相关度成为可能。如果使用二维向量来表示词语,那么可以将每个词看作平面上的一个点,典的位置即横纵坐标由对应的二维向量确定,可以是任意且连续的。如果希望点的位置中蕴含词的语义,那么平面上位置相邻的点应当具有相关或相似的语义。用数学的语言来说,两个词具有语义相关或者相似,则它们对应的词向量之间的距离相近,度量向量之间的距离可以使用经典的欧拉距离和余弦相似度等。一个好的词嵌入模型应当满足以下两方面要求:1.相关:语义相关或者相似的词语,它们对应的词向量之间距离相近,例如“苹果”和“梨子”的词向量距离相近。 2. 类比: 具有类比关系的4个词语,例如, 男人对于女人, 类比国王对于王后,满足男人-女人=国王-王后, 即保持词向量之间的关联类比,其中的减号表示两个词向量之间求差。 这样一来,通过词嵌入模型得到的词向量中既包含了词本身的语义,又蕴含了词之间的关联,同时具备低维、稠密、实值等优点,可以直接输入计算机并进行后续分析。但词典中的词如此之多,词本身的语义便十分丰富,词之间的关联则更为复杂,所以相对于词袋模型,训练一个足够好的词向量模型更加困难。
训练词向量
gensim 支持包括 TF-IDF、LSA、LDA和 Word2Vec在内的多种主题模型算法,并提高了诸如相似度计算、信息检索等常用任务的API接口。这里仅提供模型实现,而语料的文本模型,则没有提供。
# 训练模型
sentences = LineSentence('wiki.word.text')
# size: 词向量的维度
# window: 上下文环境的窗口大小
# min_count: 忽略出现次数低于 min_count 的词
model = Word2Vec(sentences, size=128, window=5, min_count=5, workers=4)
# 保存模型
model.save('word_embedding_128')
# 如果已经保存过模型,则直接加载即可
# 前面训练并保存的代码都可以省略
# model = Word2Vec.load("word_embedding_128")
# 使用模型
# 返回和一个词语最相关的多个词语以及对应的相关度
items = model.most_similar(u'你好')
for item in items:
# 词的内容,词的相关度
print(item[0], item[1])
model.similarity(u'男人', u'女人')