近日,ACL 2023的论文录用结果公布,小米AI实验室机器翻译团队联合厦门大学苏劲松教授团队在多模态图片翻译方向的最新研究成果已被ACL 2023主会录用,标志着小米在多模态机器翻译方向取得了重要进展。
ACL(Annual Meeting of the Association for Computational Linguistics)是自然语言处理(NLP)领域最重要的顶级国际会议之一。每年由国际计算语言学协会举办,是中国计算机学会(CCF)A类推荐会议。

▍论文简介
题目:Exploring Better Text Image Translation with Multimodal Codebook
作者:蓝志彬,余嘉炜,李响,张文,栾剑,王斌,黄德根,苏劲松
类型:主会长文
一、研究背景
图片文本翻译(Text Image Translation,简称TIT)的目标是将图片中的源语言文本翻译成目标语言。它在旅游、外语学习、专业阅读、跨境电商等场景中具有重要的应用价值,已成为机器翻译产品的标配功能。
目前,TIT的研究面临两大主要瓶颈:
1. 缺乏公开可用的真实数据集。
2. 模型主要采用级联结构,易受OCR错误传播的影响。例如下图中的消防员衣服上的文本没有显示完整,导致“富锦消防”四个字被误识别为“富锦消阳”,从而产生了错误的译文。

二、方法介绍
针对上述问题,该项工作主要包含两部分:
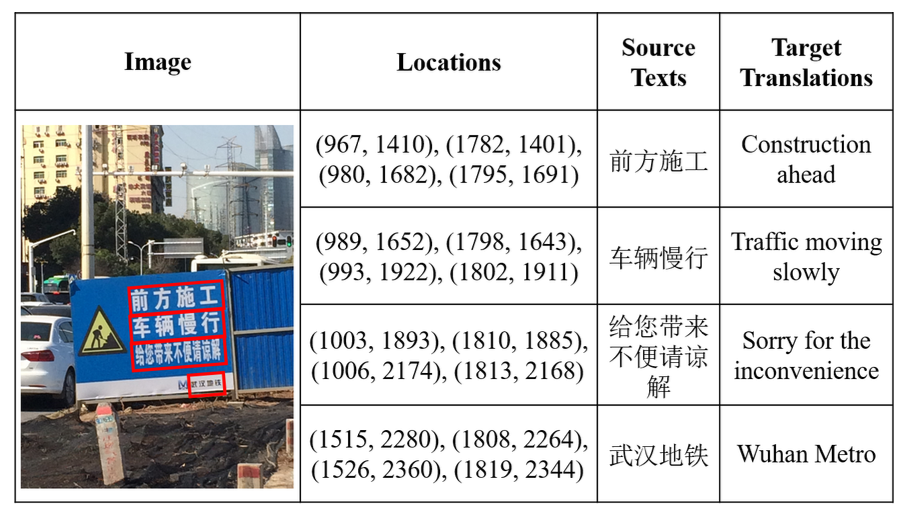
1/ 发布了该领域首个大规模真实场景TIT数据集OCRMT30K
包含约3万张中英双语图片-文本对,有助于推动此领域的后续研究。数据样例如下图所示。
2/ 提出了一种基于多模态codebook的图片翻译模型
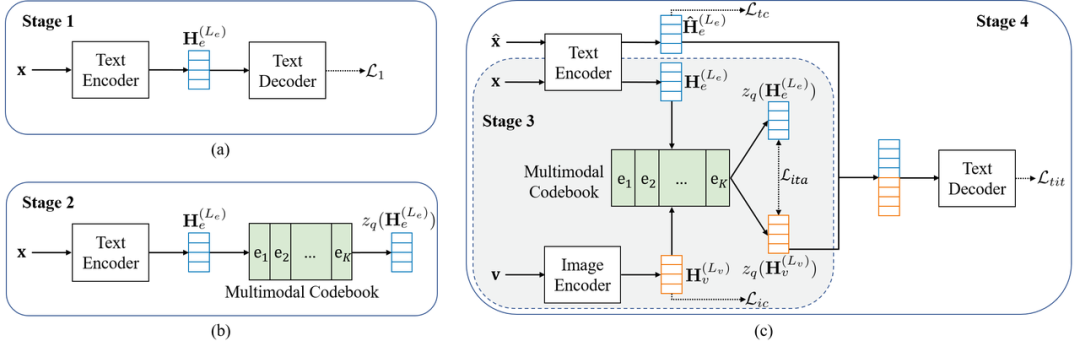
它能够利用图片联想相关文本,为翻译提供有效的补充信息。此外,我们创新性的提出了一种四阶段训练框架,充分利用训练机器翻译模型的双语文本、训练OCR模型的单语图片-文本数据,以及训练TIT模型的双语图像-文本数据。
如下图所示,在第一阶段,以大规模双语文书数据上预训练常规的基于encoder-decoder架构的神经机器翻译模型;在第二阶段,利用大规模源语言单语数据预训练多模态 codebook;在第三阶段,借鉴图像-文本对齐任务,进一步在OCR数据集上训练图像encoder和多模态codebook;在第四阶段,基于OCRMT30K数据集微调整个模型。广泛的实验和深入的分析有力地证明了本研究提出的模型和训练框架的有效性。
三、应用场景
小米AI实验室自研机器翻译技术已广泛应用于小米手机和 IoT 产品,包括最新发布的小米 13 Ultra手机、小米平板6和米家词典笔。
小米手机用户皆可通过小爱翻译App,实现观看“生肉”外语视频、浏览外文网页,以及无论是与外国友人面对面还是通话沟通、还是遇到含有外文的图片时,都能随时随地便捷的获取到机器翻译的译文。能够轻松应对各种语言障碍,边说边译、边听边译、边看边译即刻交流。
小爱翻译中「屏幕翻译」和「拍照翻译」即基于图片翻译技术打造的实用功能,满足不同场景下翻译图片中外语文本的需求,实现所看即所译。
用法:对手机上的小爱同学说「小爱翻译」或「翻译」,或通过手机桌面下拉栏点击「小爱翻译」,开启小爱翻译浮窗,点击其中「屏幕翻译」按键。
「屏幕翻译」演示视频
「拍照翻译」演示视频
未来,我们将持续探索和推动多模态机器翻译技术发展,服务于产品应用,让全球每个人都能享受没有语言障碍的美好生活。

