我们要写程序去访问hdfs的话,我们可以使用hdfs提供的工具jar包。我们不知道具体需要哪些jar包的话,我们可以将有关的jar包一股脑全部导入。这些jar包全部都在hadoop的安装包下。
我们可以这样导入:
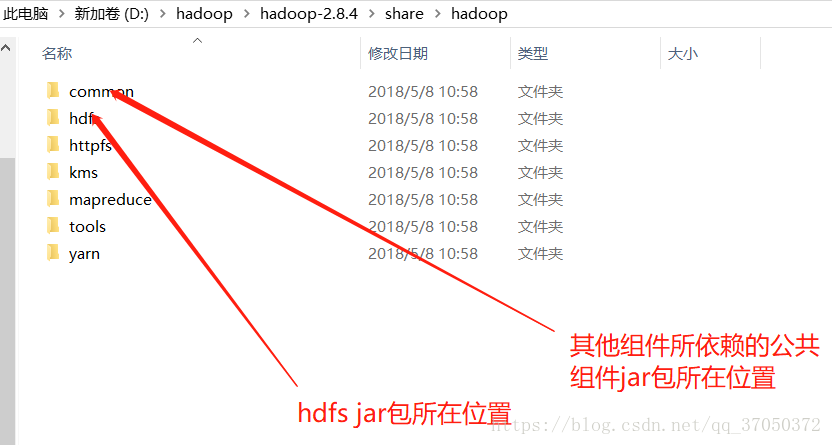
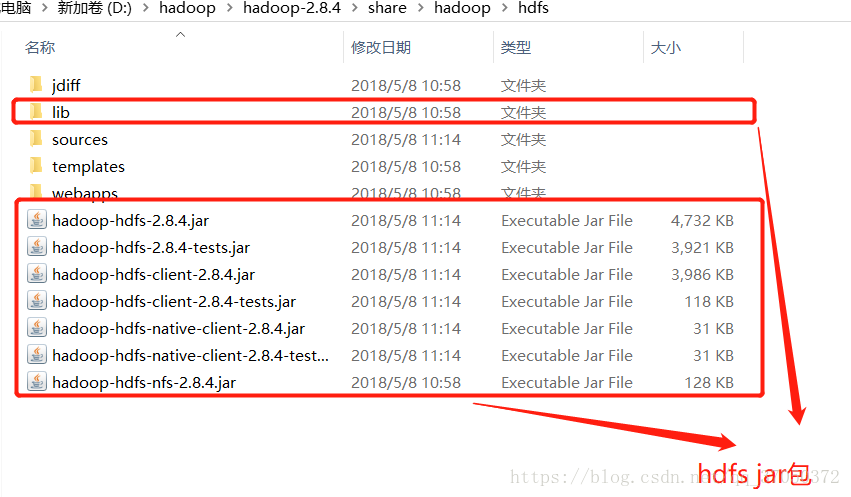
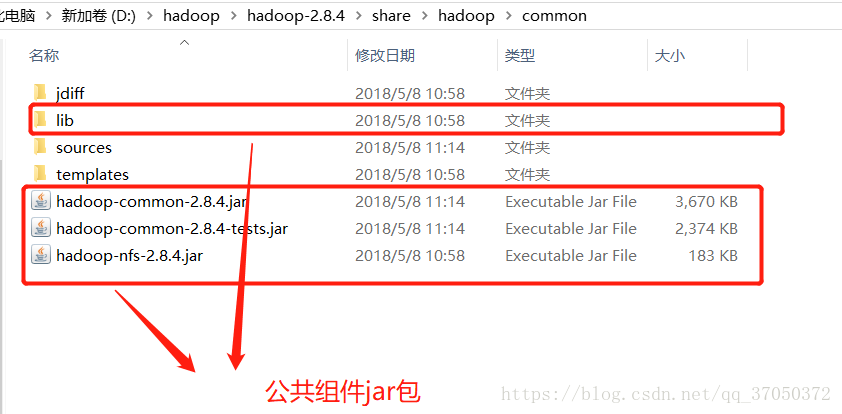
接下来就是在myeclipse中,通过java代码来操作hdfs文件啦:
package com.test.hdfs;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.Arrays;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsClientDemo {
FileSystem fs = null;
@Before
//上传文件
public void init() throws Exception{
Configuration conf = new Configuration();
conf.set("dfs.blocksize", "64m");
conf.setInt("dfs.replication", 1);;
//构造一个客户端的对象
fs = FileSystem.get(new URI("hdfs://marshal:9000/"),conf,"root" );
}
@Test
public void testUpload() throws Exception{
fs.copyFromLocalFile(new Path("D:/GongAn.csv"), new Path("/"));
fs.close();
}
//下载文件
//从hdfs下载的时候,windows会用本地库往本地磁盘写文件,
//要用本地库就意味着机器上要有本地库,而本地库会从HADOOP_HOME找
//所以就要在环境变量中设置HADOOP_HOME,而且得放windows版本的本地库
//执行下载的时候,会去HADOOP_HOME目录下找bin目录下的可执行文件,这些可执行文件必须是再windows环境下编译的
//可是我们下载的安装包都是在linux环境下编译的,我使用的是别人编译好的可执行文件
//当我们配置好环境变量之后发现还是无法下载时我们就需要重启myeclipse,因为打开myeclipse的时候
//它该加载的环境已经加载好了,重启时为了让他重新加载
@Test
public void testDownload() throws Exception{
fs.copyToLocalFile(new Path("/aaa/GongAn2.csv"), new Path("E:/"));
fs.close();
}
/**
* 当然前面的那种使用本地库的方式时默认的方式,我们能也可以不适用本地库下载
* 因为java本身就是跨平台的语言,既可以在windows写也可以在linux下写
* 这种方式,客户端会使用jdk原生的api来进行本地平台的文件数据操作
* 建议使用前面的方法,因为将来写mapreduce的时候,人家已经封装好这些东西了
* 这个时候我们就不能进行干预,使用原生的api还是本地库了
* @throws Exception
*/
@Test
public void testDownload2() throws Exception{
//第一个参数:是否删除原来的数据
fs.copyToLocalFile(false, new Path("/aaa/GongAn2.csv"),new Path("E:/"), true);
fs.close();
}
//删除文件
@Test
public void testDelete() throws Exception{
fs.delete(new Path("/aaa"),true);
fs.close();
}
//移动文件(相当于改名)
@Test
public void testMove() throws Exception{
fs.rename(new Path("/GongAn.csv"), new Path("/aaa/GongAn2.csv"));
fs.close();
}
//创建目录
@Test
public void testMkdir() throws Exception{
//mkdirs可以一次性建立多级
fs.mkdirs(new Path("/a/c/d"));
fs.close();
}
//查看目录信息
@Test
public void testListDir() throws Exception{
//第二个参数代表是否递归显示
//迭代器和集合一点关系都没有,迭代器是一个工具,可以帮我们取数据。但是它本身不装数据。
//所以它本身所占的内存很少
//远程迭代器,定位文件状态
RemoteIterator<LocatedFileStatus> iter = fs.listFiles(new Path("/"), true);
while(iter.hasNext()){
LocatedFileStatus fileInfo = iter.next();
System.out.println(fileInfo.getPath());//文件路径
System.out.println(fileInfo.getGroup());//文件所属组
System.out.println(fileInfo.getOwner());//文件所有者
System.out.println(fileInfo.getAccessTime());//文件的最后访问时间
System.out.println(fileInfo.getLen());//文件的长度
System.out.println(fileInfo.getModificationTime());//文件的最后修改时间
System.out.println(fileInfo.getBlockSize());//文件的块大小
System.out.println(fileInfo.getReplication());//文件的副本数量
//这里的返回值时一个数组,时=是每一个块的位置信息,如果写了toString则会显示信息
//但是如果返回值是数组的话则需要用Arrays.toString将数组中每一个对象的toString显示出来
System.out.println(Arrays.toString(fileInfo.getBlockLocations()));
System.out.println("------------------------------------------------------");
}
fs.close();
}
@Test
public void testListDir2() throws Exception{
//前面的方式只会显示文件信息。
//而这种方式则会连文件夹一块显示。但是不会递归显示,所以没有返回迭代器
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileInfo : listStatus) {
if(fileInfo.isDirectory()){
System.out.println("这是一个文件夹");
}
if(fileInfo.isFile()){
System.out.println("这是一个文件");
}
System.out.println(fileInfo.getPath());//文件路径
System.out.println(fileInfo.getGroup());//文件所属组
System.out.println(fileInfo.getOwner());//文件所有者
System.out.println(fileInfo.getAccessTime());//文件的最后访问时间
System.out.println(fileInfo.getLen());//文件的长度
System.out.println(fileInfo.getModificationTime());//文件的最后修改时间
System.out.println(fileInfo.getBlockSize());//文件的块大小
System.out.println(fileInfo.getReplication());//文件的副本数量
System.out.println("------------------------------------------------------");
}
fs.close();
}
//读取文件内容
@Test
public void testReadContent() throws Exception{
//这个是在DataInputStream上做的实现
FSDataInputStream open = fs.open(new Path("/README.txt"));
//这里也可以用循环读,文件小只用数组就可以了
byte[] b = new byte[4096];
int n = open.read(b);
String content = new String(b,0,n);
System.out.println(content);
open.close();
fs.close();
}
@Test
public void testReadContent2() throws Exception{
//前面的读法是从头读到尾,接下来我们就要控制,想读多少读多少
FSDataInputStream open = fs.open(new Path("/qingshu.txt"));
byte[] b = new byte[10];
int n = 0;
while((n = open.read(b))!=-1){
System.out.print(new String(b,0,n));
}
//从指定的偏移量20开始,读所需的长度10
open.seek(20);
byte[] b2= new byte[10];
int n2 = open.read(b2);
//这里的10个字节把换行也算进去了
System.out.println(new String(b2,0,n2));
}
//写数据到文件中
@Test
public void testWriteDataToFile() throws Exception{
FSDataOutputStream out = fs.create(new Path("/我的自白"));
String selfIntroduction = "我是段王爷,祖籍云南大理,家传六脉神剑,凌波微步,女朋友一大堆";
int age=18;
float salary = 1.88f;
out.writeUTF(selfIntroduction);
out.writeInt(age);
out.writeFloat(salary);
out.close();
FSDataInputStream in = fs.open(new Path("/我的自白"));
String str = in.readUTF();
System.out.println(str);
int age1 = in.readInt();
System.out.println(age1);
float f1 = in.readFloat();
System.out.println(f1);
fs.close();
}
}