HDFS客户端环境准备
1.根据本机windows操作系统使用对应编译hadoop的jar包到非中文目录下(目录不能包含空格,如:D:\Develop\hadoop-2.7.2)
2.配置HADOOP_HOME环境变量
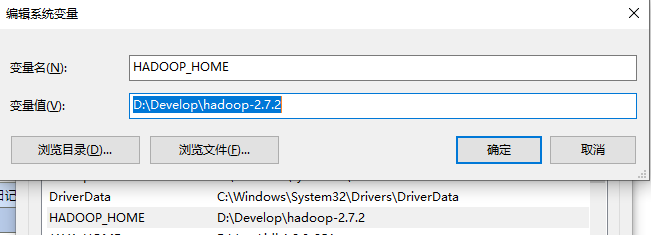
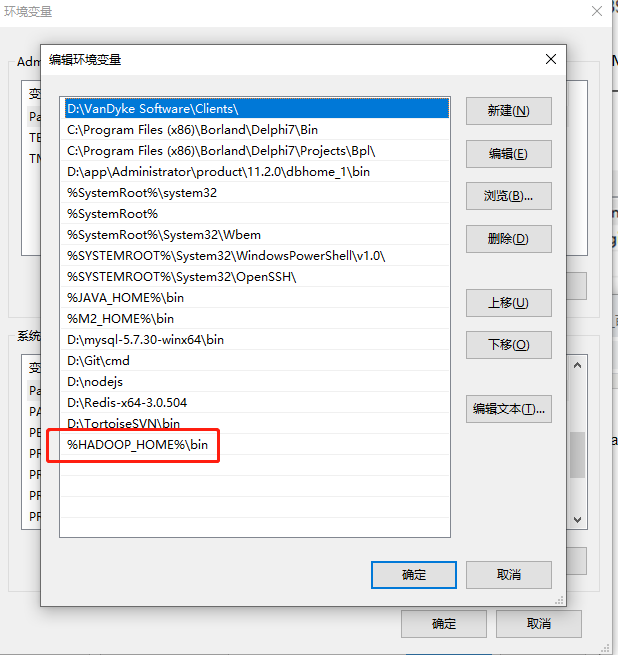
3.配置Path环境变量
4.使用idea创建一个Maven工程hdfsClient
5.导入相应的依赖包
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.hdfs.client</groupId> <artifactId>hdfsClient</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> </dependencies> </project>
在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
6.创建HdfsClient类
package com.hdfs.client;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
// 配置在集群上运行
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.1.11:9000"), configuration, "hadoop");
// 2 创建目录
fs.mkdirs(new Path("/test/hdfs"));
// 3 关闭资源
fs.close();
}
}
HDFS的API操作
1.文件上传
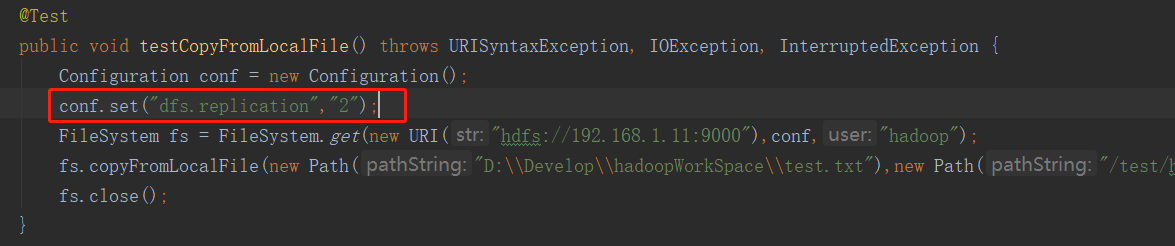
@Test public void testCopyFromLocalFile() throws URISyntaxException, IOException, InterruptedException { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.1.11:9000"),conf,"hadoop"); fs.copyFromLocalFile(new Path("D:\\Develop\\hadoopWorkSpace\\test.txt"),new Path("/test/hdfs/test.txt")); fs.close(); }
注意:hdfs设置生成的副本数,可以在服务器hadoop的hdfs-site.xml中设置,也可以客户端项目中的resources下用户自定义配置文件,也可在代码中设置值
服务器的默认配置
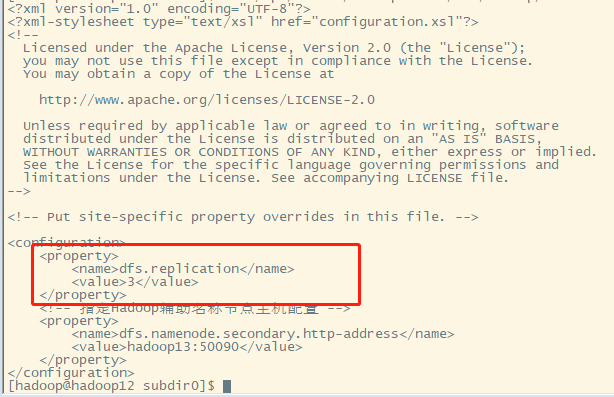
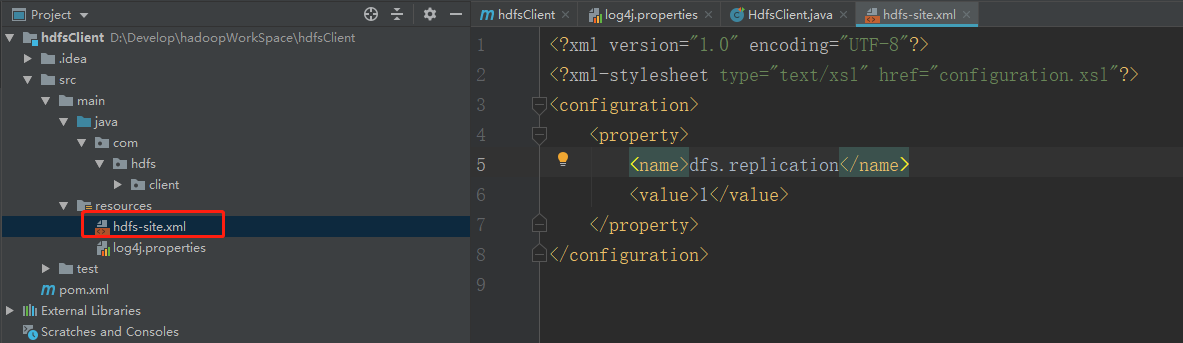
客户端项目下的配置文件
客户端代码中设置的值
这三者的优先级
客户端代码中设置的值 > 客户端项目下的配置文件 > 服务器的默认配置
2.文件下载
@Test public void testCopyToLocalFile() throws IOException, URISyntaxException, InterruptedException { Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.1.11:9000"),configuration,"hadoop"); // boolean delSrc 指是否将原文件删除 // Path src 指要下载的文件路径 // Path dst 指将文件下载到的路径 // boolean useRawLocalFileSystem 是否开启文件校验 false 用该方法会生成(.文件名.txt.crc)的文件 // fs.copyToLocalFile(new Path("/test/hdfs/test.txt"),new Path("d:\\Develop\\hadoopWorkSpace\\test1.txt")); fs.copyToLocalFile(false,new Path("/test/hdfs/test.txt"),new Path("d:\\Develop\\hadoopWorkSpace\\test1.txt"),true); fs.close(); }
3.文件夹删除
@Test public void testDelete() throws IOException, URISyntaxException, InterruptedException { Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.1.11:9000"),configuration,"hadoop"); fs.delete(new Path("/a"),true); //true表示文件夹下的所有文件也要删除(递归) false 只删除文件 fs.close(); }
4.文件名更改
@Test public void testRename() throws IOException, URISyntaxException, InterruptedException { Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.1.11:9000"),configuration,"hadoop"); fs.rename(new Path("/test/hdfs/test.txt"),new Path("/test/hdfs/test1.txt")); fs.close(); }
5.文件详情查看
@Test public void testListFiles() throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.1.11:9000"),configuration,"hadoop"); RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true); while(listFiles.hasNext()){ LocatedFileStatus status = listFiles.next(); // 输出详情 // 文件名称 System.out.println(status.getPath().getName()); // 长度 System.out.println(status.getLen()); // 权限 System.out.println(status.getPermission()); // 分组 System.out.println(status.getGroup()); // 获取存储的块信息 BlockLocation[] blockLocations = status.getBlockLocations(); for (BlockLocation blockLocation : blockLocations) { // 获取块存储的主机节点 String[] hosts = blockLocation.getHosts(); for (String host : hosts) { System.out.println(host); } } System.out.println("---------分割线----------"); } fs.close(); }
6.文件和文件夹判断
@Test public void testListStatus() throws IOException, InterruptedException, URISyntaxException{ Configuration configuration = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.1.11:9000"),configuration,"hadoop"); // 2 判断是文件还是文件夹 FileStatus[] listStatus = fs.listStatus(new Path("/")); for (FileStatus fileStatus : listStatus) { // 如果是文件 if (fileStatus.isFile()) { System.out.println("file:"+fileStatus.getPath().getName()); }else { System.out.println("dir:"+fileStatus.getPath().getName()); } } fs.close(); }